标签:gif odi nes 自定义 tar 交互 text img 扩展
字符串是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符‘0‘和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
需要强调的一点是:
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
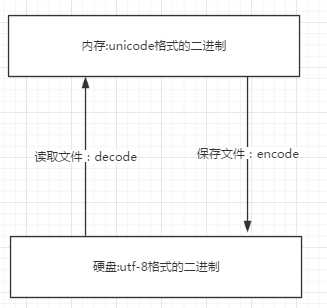
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
打开文件,得到文件句柄并赋值给一个变量
通过句柄对文件进行操作
关闭文件

f = open(‘chenli.txt‘) #打开文件 first_line = f.readline() print(‘first line:‘,first_line) #读一行 print(‘我是分隔线‘.center(50,‘-‘)) data = f.read()# 读取剩下的所有内容,文件大时不要用 print(data) #打印读取内容 f.close() #关闭文件
文件以gbk格式保存,以utf-8打开会报错,所以,什么编码保存的用什么编码打开。
#不指定打开编码,默认使用操作系统的编码,windows为gbk,linux为utf-8,与解释器编码无关 f=open(‘chenli.txt‘,encoding=‘gbk‘) #在windows中默认使用的也是gbk编码,此时不指定编码也行 f.read()
文件句柄 = open(‘文件路径‘, ‘模式‘)
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
w,只写模式【不可读;不存在则创建;存在则清空内容】
x, 只写模式【不可读;不存在则创建,存在则报错】
a, 追加模式【可读; 不存在则创建;存在则只追加内容】
"+" 表示可以同时读写某个文件
r+, 读写【可读,可写】
w+,写读【可读,可写】
x+ ,写读【可读,可写】
a+, 写读【可读,可写】
"b"表示以字节的方式操作
rb 或 r+b
wb 或 w+b
xb 或 w+b
ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
flush原理:
文件打开以字节的方式操作才能使用一下命令:
read(3)代表读取3个字符
seek(3,0)代表读取3个字节 第二个参数0代表从文件头开始 1代表从光标目前位置开始 2代表从文件末尾开始
tell()返回光标目前在的位置
truncate()截断
open(file[, mode[, buffering[, encoding[, errors[, newline[, closefd=True]]]]]])
open函数有很多的参数,常用的是file,mode和encoding
file文件位置,需要加引号
mode文件打开模式,见下面3
buffering的可取值有0,1,>1三个,0代表buffer关闭(只适用于二进制模式),1代表line buffer(只适用于文本模式),>1表示初始化的buffer大小;
encoding表示的是返回的数据采用何种编码,一般采用utf8或者gbk;
errors的取值一般有strict,ignore,当取strict的时候,字符编码出现问题的时候,会报错,当取ignore的时候,编码出现问题,程序会忽略而过,继续执行下面的程序。
newline可以取的值有None, \n, \r, ”, ‘\r\n‘,用于区分换行符,但是这个参数只对文本模式有效;
closefd的取值,是与传入的文件参数有关,默认情况下为True,传入的file参数为文件的文件名,取值为False的时候,file只能是文件描述符,什么是文件描述符,就是一个非负整数,在Unix内核的系统中,打开一个文件,便会返回一个文件描述符。
两者都能够打开文件,对文件进行操作,也具有相似的用法和参数,但是,这两种文件打开方式有本质的区别,file为文件类,用file()来打开文件,相当于这是在构造文件类,而用open()打开文件,是用python的内建函数来操作,建议使用open()
| Character | Meaning |
| ‘r‘ | open for reading (default) |
| ‘w‘ | open for writing, truncating the file first |
| ‘a‘ | open for writing, appending to the end of the file if it exists |
| ‘b‘ | binary mode |
| ‘t‘ | text mode (default) |
| ‘+‘ | open a disk file for updating (reading and writing) |
| ‘U‘ | universal newline mode (for backwards compatibility; should not be used in new code) |
r、w、a为打开文件的基本模式,对应着只读、只写、追加模式;
b、t、+、U这四个字符,与以上的文件打开模式组合使用,二进制模式,文本模式,读写模式、通用换行符,根据实际情况组合使用。
常见的mode取值组合
r或rt 默认模式,文本模式读
rb 二进制文件
w或wt 文本模式写,打开前文件存储被清空
wb 二进制写,文件存储同样被清空
a 追加模式,只能写在文件末尾
a+ 可读写模式,写只能写在文件末尾
w+ 可读写,与a+的区别是要清空文件内容
r+ 可读写,与a+的区别是可以写到文件任何位置
上下文管理,程序后面不用再关闭文件。
with open(‘a.txt‘,‘w‘) as f:
pass
with open(‘a.txt‘,‘r‘) as read_f,open(‘b.txt‘,‘w‘) as write_f:
data=read_f.read()
write_f.write(data)
import os
with open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) as read_f, open(‘.a.txt.swap‘,‘w‘,encoding=‘utf-8‘) as write_f:
for line in read_f:
if line.startswith(‘hello‘):
line=‘哈哈哈\n‘
write_f.write(line)
os.remove(‘a.txt‘)
os.rename(‘.a.txt.swap‘,‘a.txt‘)
f=open(‘a.txt‘,encoding=‘utf-8‘) f.read() #读取文件所有内容 f.readline() #一次读取一行内容 f.readlines() #读取所有内容,并存成列表 f.readable() #文件是否可读 f.write() #写文件,打开文件清空再追加,可创建新文件 f.writable() #文件是否可写 f.writelines() #以列表的方式写入文件 f.closed #文件是否关闭 f.name f.encoding #文件的名字 文件的字符编码类型 f.close() #关闭文件
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
我们以自定义一个求绝对值的my_abs函数为例:
def my_abs(x):
if x >= 0:
return x
else:
return -x
请自行测试并调用my_abs看看返回结果是否正确。
请注意,函数体内部的语句在执行时,一旦执行到return时,函数就执行完毕,并将结果返回。因此,函数内部通过条件判断和循环可以实现非常复杂的逻辑。
如果没有return语句,函数执行完毕后也会返回结果,只是结果为None。
return None可以简写为return。
在Python交互环境中定义函数时,注意Python会出现...的提示。函数定义结束后需要按两次回车重新回到>>>提示符下:
如果你已经把my_abs()的函数定义保存为abstest.py文件了,那么,可以在该文件的当前目录下启动Python解释器,用from abstest import my_abs来导入my_abs()函数,注意abstest是文件名(不含.py扩展名)。
如果想定义一个什么事也不做的空函数,可以用pass语句:
def nop():
pass
pass语句什么都不做,那有什么用?实际上pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。
pass还可以用在其他语句里,比如:
if age >= 18:
pass
缺少了pass,代码运行就会有语法错误。
调用函数时,如果参数个数不对,Python解释器会自动检查出来,并抛出TypeError:
>>> my_abs(1, 2) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: my_abs() takes 1 positional argument but 2 were given
但是如果参数类型不对,Python解释器就无法帮我们检查。试试my_abs和内置函数abs的差别:
>>> my_abs(‘A‘) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in my_abs TypeError: unorderable types: str() >= int() >>> abs(‘A‘) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: bad operand type for abs(): ‘str‘
当传入了不恰当的参数时,内置函数abs会检查出参数错误,而我们定义的my_abs没有参数检查,会导致if语句出错,出错信息和abs不一样。所以,这个函数定义不够完善。
让我们修改一下my_abs的定义,对参数类型做检查,只允许整数和浮点数类型的参数。数据类型检查可以用内置函数isinstance()实现:
def my_abs(x):
if not isinstance(x, (int, float)):
raise TypeError(‘bad operand type‘)
if x >= 0:
return x
else:
return -x
添加了参数检查后,如果传入错误的参数类型,函数就可以抛出一个错误:
>>> my_abs(‘A‘) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 3, in my_abs TypeError: bad operand type
错误和异常处理将在后续讲到。
函数可以返回多个值吗?答案是肯定的。
比如在游戏中经常需要从一个点移动到另一个点,给出坐标、位移和角度,就可以计算出新的新的坐标:
import math
def move(x, y, step, angle=0):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny
import math语句表示导入math包,并允许后续代码引用math包里的sin、cos等函数。
然后,我们就可以同时获得返回值:
>>> x, y = move(100, 100, 60, math.pi / 6) >>> print(x, y) 151.96152422706632 70.0
但其实这只是一种假象,Python函数返回的仍然是单一值:
>>> r = move(100, 100, 60, math.pi / 6) >>> print(r) (151.96152422706632, 70.0)
原来返回值是一个tuple!但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,Python的函数返回多值其实就是返回一个tuple,但写起来更方便。
定义函数时,需要确定函数名和参数个数;
如果有必要,可以先对参数的数据类型做检查;
函数体内部可以用return随时返回函数结果;
函数执行完毕也没有return语句时,自动return None。
函数可以同时返回多个值,但其实就是一个tuple。
参考博客:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
http://www.cnblogs.com/linhaifeng/category/890629.html
标签:gif odi nes 自定义 tar 交互 text img 扩展
原文地址:http://www.cnblogs.com/1204guo/p/7051182.html