标签:conf eof writer documents 技术分享 bsp 开发人员 分析 solr
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包.
粘贴这句话的意思就是想说明 Lucene仅仅是一个工具包,搜索引擎的工具包.
有人会问?Lucene和solr的区别,solr是一个搜索系统,打个比方,就如servlet和struts2的区别 Lucene就是servlet,solr就好比solr,solr封装了Lucene.
下面说说Lucene的原理:
我们使用Lucene,其实使用的是他的倒排查询
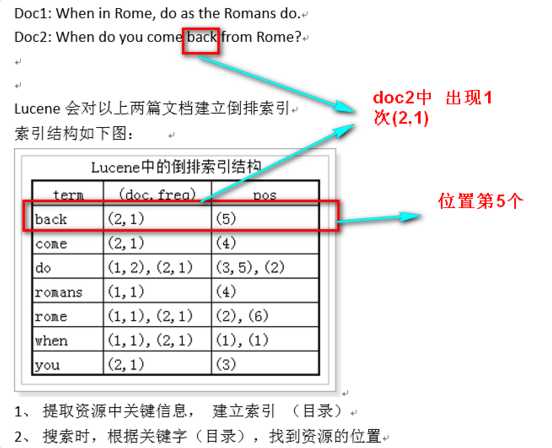
什么是倒排查询?举个例子
新华字典,我们都用过吧,新华字典分为两部分,第一部门就是目录的边旁部首,第二部分就是正文,一个一个字的解释,
我们在用新华字典的时候,一般我们都是通过边旁部首找字,没有人一页一页的翻字典找字吧.
Lucene的倒排就是如此,他会检索文本,数据库,web网页,在把内容分词,就像边旁部首
再次强调
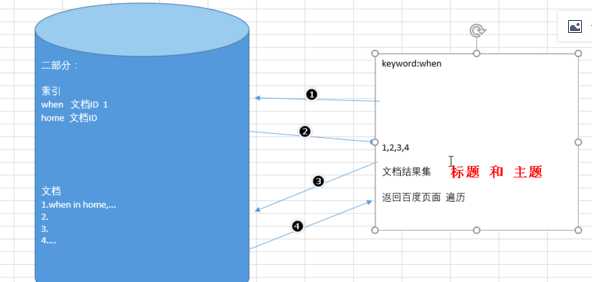


这一条数据就是一个document文档
每一个字段就是一个Field域
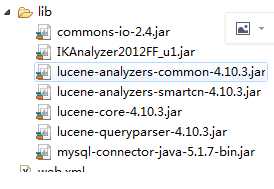
这就是要用到的包;
 ik下载后把这3个文件也要导入项目中,ext.dic是加词的,stop是停词的.
ik下载后把这3个文件也要导入项目中,ext.dic是加词的,stop是停词的.
前面的都是Lucece的理论,只有理论搞懂了,下面的代码实现过程也就轻松了
1 package com.itheima.lucene; 2 3 import java.io.File; 4 import java.util.ArrayList; 5 import java.util.List; 6 7 import org.apache.lucene.analysis.Analyzer; 8 import org.apache.lucene.analysis.standard.StandardAnalyzer; 9 import org.apache.lucene.document.Document; 10 import org.apache.lucene.document.Field.Store; 11 import org.apache.lucene.document.TextField; 12 import org.apache.lucene.index.DirectoryReader; 13 import org.apache.lucene.index.IndexReader; 14 import org.apache.lucene.index.IndexWriter; 15 import org.apache.lucene.index.IndexWriterConfig; 16 import org.apache.lucene.queryparser.classic.QueryParser; 17 import org.apache.lucene.search.IndexSearcher; 18 import org.apache.lucene.search.Query; 19 import org.apache.lucene.search.ScoreDoc; 20 import org.apache.lucene.search.TopDocs; 21 import org.apache.lucene.store.Directory; 22 import org.apache.lucene.store.FSDirectory; 23 import org.apache.lucene.util.Version; 24 import org.junit.Test; 25 import org.wltea.analyzer.lucene.IKAnalyzer; 26 27 import com.itheima.dao.BookDao; 28 import com.itheima.dao.impl.BookDaoImpl; 29 import com.itheima.pojo.Book; 30 31 public class CreateIndexTest { 32 //分词 33 @Test 34 public void testCreateIndex() throws Exception{ 35 // 1. 采集数据 36 BookDao bookDao = new BookDaoImpl(); 37 List<Book> listBook = bookDao.queryBookList(); 38 39 // 2. 创建Document文档对象 40 List<Document> documents = new ArrayList<>(); 41 for (Book bk : listBook) { 42 43 Document doc = new Document(); 44 doc.add(new TextField("id", String.valueOf(bk.getId()), Store.YES));// Store.YES:表示存储到文档域中 45 doc.add(new TextField("name", bk.getName(), Store.YES)); 46 doc.add(new TextField("price", String.valueOf(bk.getPrice()), Store.YES)); 47 doc.add(new TextField("pic", bk.getPic(), Store.YES)); 48 doc.add(new TextField("desc", bk.getDesc(), Store.YES)); 49 50 // 把Document放到list中 51 documents.add(doc); 52 } 53 54 // 3. 创建分析器(分词器) 55 //Analyzer analyzer = new StandardAnalyzer(); 56 //中文 IK 57 Analyzer analyzer = new IKAnalyzer(); 58 59 // 4. 创建IndexWriterConfig配置信息类 60 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); 61 62 // 5. 创建Directory对象,声明索引库存储位置 63 Directory directory = FSDirectory.open(new File("H:\\temp")); 64 65 // 6. 创建IndexWriter写入对象 66 IndexWriter writer = new IndexWriter(directory, config); 67 68 // 7. 把Document写入到索引库中 69 for (Document doc : documents) { 70 writer.addDocument(doc); 71 } 72 73 // 8. 释放资源 74 writer.close(); 75 } 76
//查 77 @Test 78 public void serachIndex() throws Exception{ 79 //创建分词器 必须和检索时的分析器一致 80 Analyzer analyzer = new StandardAnalyzer(); 81 // 创建搜索解析器,第一个参数:默认Field域,第二个参数:分词器 82 QueryParser queryParser = new QueryParser("desc", analyzer); 83 84 // 1. 创建Query搜索对象 85 Query query = queryParser.parse("desc:java AND lucene"); 86 87 // 2. 创建Directory流对象,声明索引库位置 88 Directory directory = FSDirectory.open(new File("H:\\temp")); 89 90 // 3. 创建索引读取对象IndexReader 91 IndexReader indexReader = DirectoryReader.open(directory); 92 93 // 4. 创建索引搜索对象IndexSearcher 94 IndexSearcher indexSearcher = new IndexSearcher(indexReader); 95 96 // 5. 使用索引搜索对象,执行搜索,返回结果集TopDocs 97 // 第一个参数:搜索对象,第二个参数:返回的数据条数,指定查询结果最顶部的n条数据返回 98 TopDocs topDocs = indexSearcher.search(query, 10); 99 System.out.println("查询到的数据总条数是:" + topDocs.totalHits); 100 //获得结果集 101 ScoreDoc[] docs = topDocs.scoreDocs; 102 103 // 6. 解析结果集 104 for (ScoreDoc scoreDoc : docs) { 105 //获得文档 106 int docID = scoreDoc.doc; 107 Document doc = indexSearcher.doc(docID); 108 109 System.out.println("docID:"+docID); 110 System.out.println("bookid:"+doc.get("id")); 111 System.out.println("pic:"+doc.get("pic")); 112 System.out.println("name:"+doc.get("name")); 113 System.out.println("desc:"+doc.get("desc")); 114 System.out.println("price:"+doc.get("price")); 115 } 116 117 // 7. 释放资源 118 indexReader.close(); 119 } 120 }
标签:conf eof writer documents 技术分享 bsp 开发人员 分析 solr
原文地址:http://www.cnblogs.com/hd976521/p/7062177.html