标签:ica evel dna list 代码 搜索路径 技术分享 sys.path 大于等于
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
import logging logging.debug(‘debug message‘) logging.info(‘info message‘) logging.warning(‘warning message‘) logging.error(‘error message‘) logging.critical(‘critical message‘)
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置:
import logging logging.basicConfig(level=logging.ERROR, format=‘%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s‘, datefmt=‘%a, %d %b %Y %H:%M:%S‘, filename=‘a.txt‘, filemode=‘w‘ ) logging.debug(‘debug message‘) logging.info(‘info message‘) logging.warning(‘warning message‘) logging.error(‘error message‘) logging.critical(‘critical message‘)
配置参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
import logging logger = logging.getLogger() # 创建一个handler,用于写入日志文件 fh = logging.FileHandler(‘test.log‘) # 再创建一个handler,用于输出到控制台 ch = logging.StreamHandler() formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘) fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) #logger对象可以添加多个fh和ch对象 logger.addHandler(ch) logger.debug(‘logger debug message‘) logger.info(‘logger info message‘) logger.warning(‘logger warning message‘) logger.error(‘logger error message‘) logger.critical(‘logger critical message‘)
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象一个子集,JSON和Python内置的数据类型对应如下:
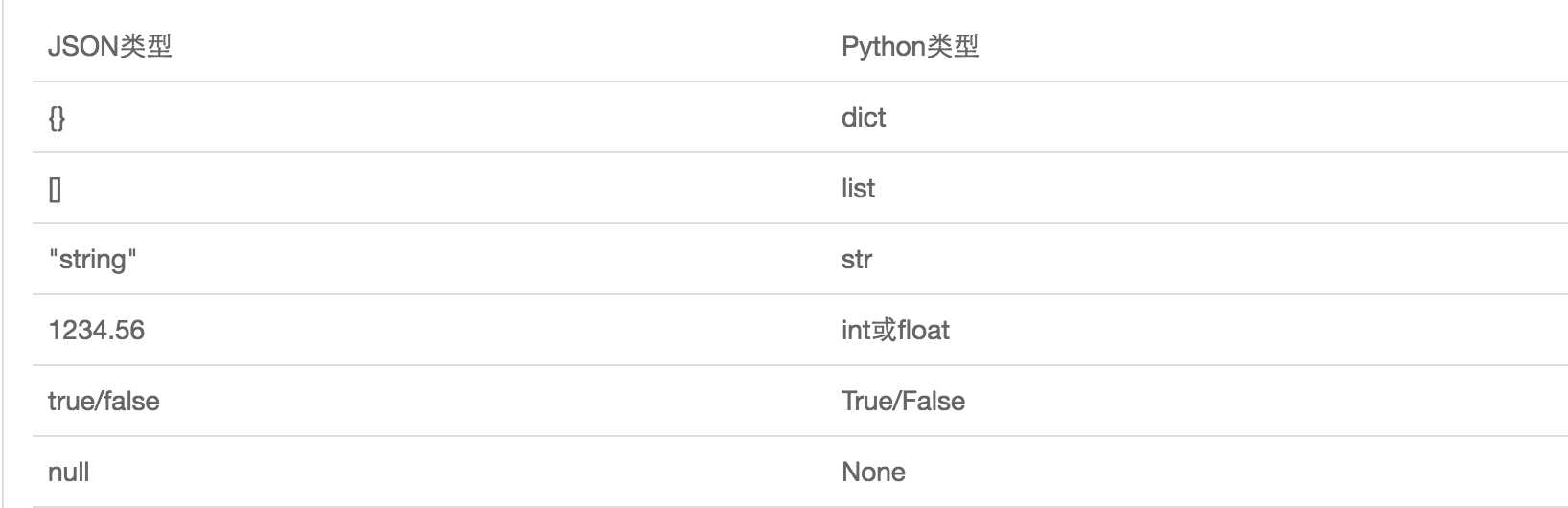
import json i=10 s=‘hello‘ t=(1,4,6) l=[3,5,7] d={‘name‘:"yuan"} json_str1=json.dumps(i) json_str2=json.dumps(s) json_str3=json.dumps(t) json_str4=json.dumps(l) json_str5=json.dumps(d) print(json_str1) #‘10‘ print(json_str2) #‘"hello"‘ print(json_str3) #‘[1, 4, 6]‘ print(json_str4) #‘[3, 5, 7]‘ print(json_str5) #‘{"name": "yuan"}‘
#----------------------------序列化 import json dic={‘name‘:‘alvin‘,‘age‘:23,‘sex‘:‘male‘} print(type(dic))#<class ‘dict‘> data=json.dumps(dic) print("type",type(data))#<class ‘str‘> print("data",data) f=open(‘序列化对象‘,‘w‘) f.write(data) #-------------------等价于json.dump(dic,f) f.close() #-----------------------------反序列化<br> import json f=open(‘序列化对象‘) new_data=json.loads(f.read())# 等价于data=json.load(f) print(type(new_data))
标签:ica evel dna list 代码 搜索路径 技术分享 sys.path 大于等于
原文地址:http://www.cnblogs.com/1204guo/p/7064552.html