Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包.
粘贴这句话的意思就是想说明 Lucene仅仅是一个工具包,搜索引擎的工具包.
有人会问?Lucene和solr的区别,solr是一个搜索系统,打个比方,就如servlet和struts2的区别 Lucene就是servlet,solr就好比solr,solr封装了Lucene.
下面说说Lucene的原理:
我们使用Lucene,其实使用的是他的倒排查询
什么是倒排查询?举个例子
新华字典,我们都用过吧,新华字典分为两部分,第一部门就是目录的边旁部首,第二部分就是正文,一个一个字的解释,
我们在用新华字典的时候,一般我们都是通过边旁部首找字,没有人一页一页的翻字典找字吧.
Lucene的倒排就是如此,他会检索文本,数据库,web网页,在把内容分词,就像边旁部首

再次强调
搜索引擎(百度,谷歌)和lucene的区别
搜索引擎就是一个应用,lucene就是一个搜索工具类

name:lucene表示要搜索name这个Field域中,内容为“lucene”的文档。
desc:lucene AND desc:java 表示要搜索即包括关键字“lucene”也包括“java”的文档。
看不懂没关系
我接下来说明Doucment和Field关系
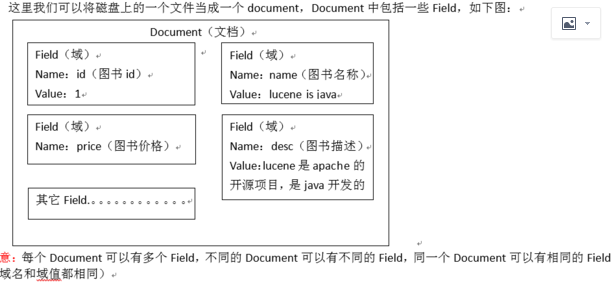
这里我用数据库中的一条数据说明

这一条数据就是一个document文档
每一个字段就是一个Field域
这样说是不是豁然开朗了.
接下来,我们说说分词器
这个lucene是外国人搞得,对中文的支持不说你也知道,不多外国人也想到这一点,"我是中国人">>我 是 中 国 人 >> 这样的效果其实还不是我们想要的,我们要的是"中国","国人"这样的词汇,这里我也不打哑谜了,市场上有很多中文分词器,无敌的存在我觉得就是IK了,这是一个jar包,导入项目即可,说他无敌是因为他可以自己加词,比如"屌丝","高富帅",这也词,可以自己加到分词器中,让程序认得.

这就是要用到的包;
 ik下载后把这3个文件也要导入项目中,ext.dic是加词的,stop是停词的.
ik下载后把这3个文件也要导入项目中,ext.dic是加词的,stop是停词的.
前面的都是Lucece的理论,只有理论搞懂了,下面的代码实现过程也就轻松了

//分词 testCreateIndex() BookDao bookDao = List<Book> listBook = List<Document> documents = ArrayList<> Document doc = doc.add( TextField("id", String.valueOf(bk.getId()), Store.YES)); doc.add( TextField("name" doc.add( TextField("price" doc.add( TextField("pic" doc.add( TextField("desc" Analyzer analyzer = IndexWriterConfig config = Directory directory = FSDirectory.open( File("H:\\temp" IndexWriter writer =
//查 serachIndex() Analyzer analyzer = QueryParser queryParser = QueryParser("desc" Query query = queryParser.parse("desc:java AND lucene" Directory directory = FSDirectory.open( File("H:\\temp" IndexReader indexReader = IndexSearcher indexSearcher = TopDocs topDocs = indexSearcher.search(query, 10 System.out.println("查询到的数据总条数是:" + ScoreDoc[] docs = docID = Document doc = System.out.println("docID:"+ System.out.println("bookid:"+doc.get("id" System.out.println("pic:"+doc.get("pic" System.out.println("name:"+doc.get("name" System.out.println("desc:"+doc.get("desc" System.out.println("price:"+doc.get("price" }
原文地址:http://12951189.blog.51cto.com/12941189/1940786