标签:line 动作 jupyter 风格 render value rate end 比较
这是优达学院机器学习课程的第4个实习项目,需要训练智能出租车学习交通规则,然后安全可靠地到达目的地。项目通过循序渐进的方式展开,从熟悉基本的领域知识开始,再以随机动作来直观感受智能车的状态,也是在这一步,让初学者有了心潮澎湃的感觉,“车终于动了!”,是的,从0开始一路走来,以游戏闯关的方式,终于来到了4级,第一次体验了传说中的“智能”了,也许是“眼见为实”吧,小车在自己算法的控制之下行动,是一种很美好的感受。然后项目通过引导,让大家开始实现基于Q-Learning算法的智能车控制。这是本项目核心算法的实现部分,对于初学者来说也是一个挑战。接着,项目要求在上一个Q-Learning算法的基础上通过调节参数,让智能车达到更优的效果。最后,项目延续以往的风格,分析讨论环节,引导大家思考并论证为什么这个实现是优化的,为什么这个项目中不需要使用gamma参数。
我喜欢优达学院的项目设计。从我的感受,项目设计对我们工作、学习也很有启发:
回到本项目,是强化学习在自动驾驶领域的迷你实验项目,我相信和工业级的自动驾驶还是有较大距离,但背后的算法思想应该有共同之处:从环境中学习,不断优化行为的质量。这就是强化学习要研究的方向。
Reinforcement Learning,与监督学习的和非监督学习不同的是,强化学习研究的是:具有行为能力的智能体,在环境中如何行动,从而取得预期的结果。我的理解,根据环境的不同,强化既可以应用于机器人、无人机等实体操控,又可以用于(复杂的)纯数据分析。当然应用于自动驾驶等与现实环境交互的领域是强化学习的强项。
那么强化学习的模型中,都有哪些元素呢?这里就完全可以类比一下人类的行为模式,想象一下,一个人初次看到“火”会是怎么样的过程,比如小孩子对火的认识过程:
首先你进入一个环境中,通过眼睛观察,发现了一团红彤彤的东西在火把顶部,你从大脑中搜索,没有找到对应的认识,但是又好奇这到底是什么,于是好奇心驱使着你,于是你决定用手去感受一下,你慢慢用手靠近火焰,感受到温度慢慢上升,你知道了这个东西是“热”的,胆大的人也许还会靠近,直到被烫伤一次,你又知道了这个东西可以烫伤皮肤,还有些人,或许会继续其他动作,拿一张纸靠近火焰,结果纸也染上了这东西,于是又知道了这个东西可以从一个地方传递到另外一个地方,知道哪天有人告诉你,这个东西叫“火”。人类的整个生活,就是这样一系列观察-思考-动作-反馈-【观察-思考-动作-反馈】的过程。而强化学习,就是应用这样的过程不断“自主学习”,从而学会一项技能,如驾驶。
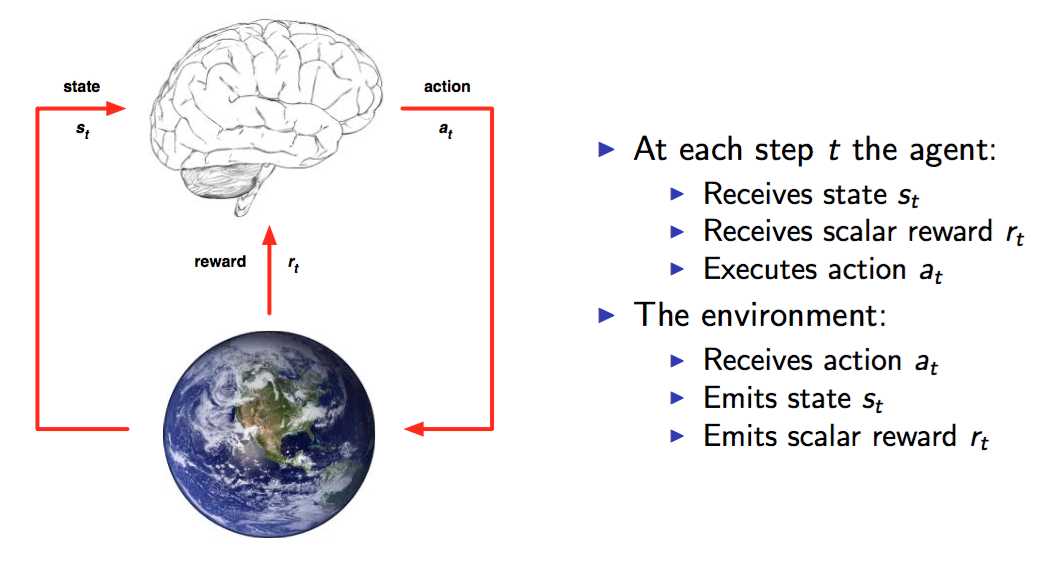
如图,强化学习的要素就是:状态State,动作Action,奖励Reward。强化学习的过程就是:不断通过当前的样本{s1,a1,r1},学习改进得到更优的策略Policy,使得Reward越来越好。
Q-Learning
原理虽然明确了,但是算法的实现确是经历了前人不断的探索,从MDP马可夫决策过程,到Bellman方程,以及Q-Learning算法理论,正是在这些大量的理论研究基础上,强化学习才得以落地。(这些算法及其过程将在其他篇幅中讨论)
回到本次智能出租车项目,用的就是Q-Learning,为什么选择Q-Learning?这实际上也是个问题,也不是初学者就能知道的。这次重点工作包括: Q-Learning算法的实现,参数调节优化。
既然是项目总结,还是要贴一下Q-Learning算法,其实实现过程还是走了一些弯路。

其中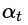 是学习率learning rate (取值(0,1])),表示智能车的Q值更新过程中有多少来自经验,多少来自新的探索发现。gamma折扣因子,表示未来状态回溯到当前状态时的反向正面奖励,由于本项目的特点(起点终点不固定,当前位置与终点距离未知,过大的回溯操作容易造成路径依赖),并没有使用,相当于取值为0。
是学习率learning rate (取值(0,1])),表示智能车的Q值更新过程中有多少来自经验,多少来自新的探索发现。gamma折扣因子,表示未来状态回溯到当前状态时的反向正面奖励,由于本项目的特点(起点终点不固定,当前位置与终点距离未知,过大的回溯操作容易造成路径依赖),并没有使用,相当于取值为0。
另外,项目中还使用了epsilon参数,表示开始阶段智能车随机选择动作的概率较大,以便有更多的路径探索机会,随着经验的积累,随机动作越来越少,而是更多的根据经验选择。
经过多轮测试,项目达到的效果如下:
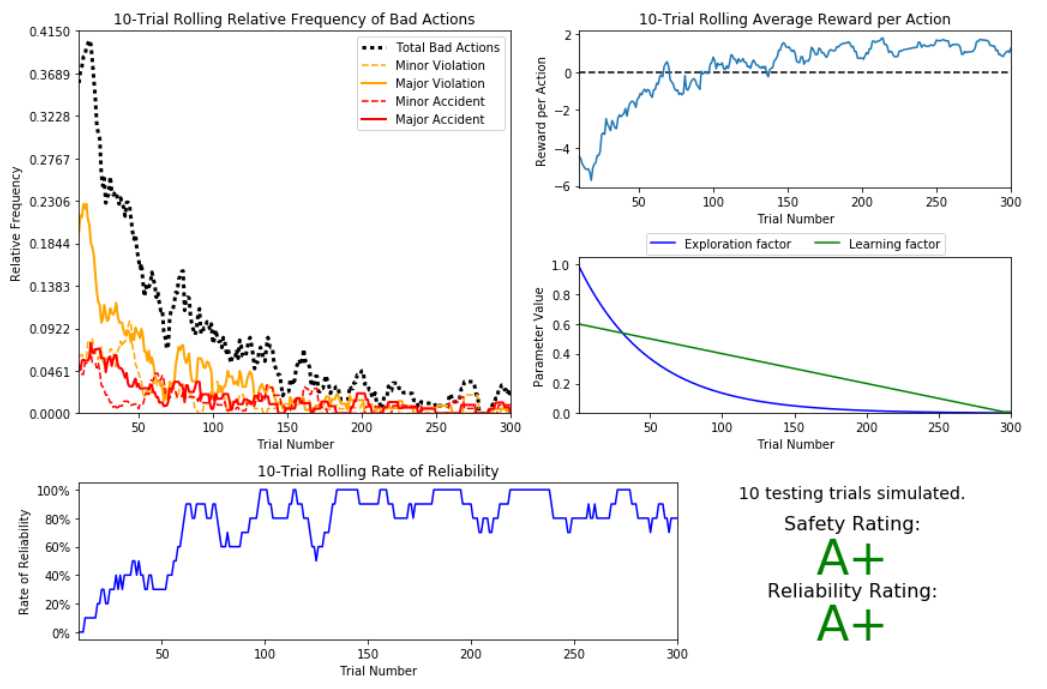
但是如果多次测试,测试结果稳定性依然不太理想。另外,可靠性在训练200次以后,依然有一定的起伏现象,不知是否有更优的参数选择。但不论如何,通过这个项目,已经能够切实感受到算法的魅力,通过训练,代理程序确实获得了较好的经验用于驾驶。
标签:line 动作 jupyter 风格 render value rate end 比较
原文地址:http://www.cnblogs.com/1xin/p/7062990.html
 )
)