标签:top nbsp 终端 进程 取数 安装 image 文件 man
自己的案列:win7上安装ubuntu (win7作为slaver,ubuntu作为master )
修改配置文件redis.conf
1)打开配置文件把下面对应的注释掉
# bind 127.0.0.1

2)Redis默认不是以守护进程的方式运行,可以通过该配置项修改,设置为no
daemonize no

3)保护模式
protected-mode no

关键的一步:ubuntu终端命令中重启redis服务的时候如下操作:
redis-server redis.conf
在win7上安装RedisDesktopManage查看ubuntur Redis数据库 (连接方法:完成以上1,2,3即可连接 注意:ubuntu的网络适配器要选择桥接模式。)
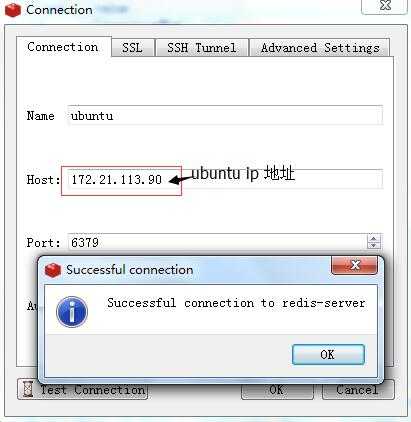
在编写爬虫的时候:
发现这样写域名的范围会报错(在ubuntu中push url后爬虫没有爬取数据):
#动态域范围的获取
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop(‘domain‘, ‘‘)
self.allowed_domains = filter(None, domain.split(‘,‘))
super(MySpider, self).__init__(*args, **kwargs)
而这样写不会报错:
allowed_domains = ["xxx.com"]
在爬虫的settings.py中指明主机地址以及端口号
如:
REDIS_HOST = ‘x.x.x.x‘ 主机地址(ubuntu IP地址)
REDIS_PORT = 6379
标签:top nbsp 终端 进程 取数 安装 image 文件 man
原文地址:http://www.cnblogs.com/huwei934/p/7066223.html