标签:打包 ict comm syn text color cfg.xml body --
solr同义词的具体实现
1.修改分词器的jar包 并重新打包
并重新打包
在org.wltea.analyzer.lucene包下新增IKTokenizerFactory 类
|
package org.wltea.analyzer.lucene; import java.io.Reader; import org.apache.lucene.analysis.Tokenizer; public class IKTokenizerFactory extends TokenizerFactory { public IKTokenizerFactory(Map<String, String> args) { } @Override } |
2.修改配置文件schema.xml
不需要同义词的配置
<!--增加分词器 -->
<fieldType name="text_ik" class="solr.TextField" >
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
修改为同义词的配置
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory"/>
<!-- <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>-->
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
</analyzer>
</fieldType>
修改synonyms.txt文件加入需要的同义词

如果同义词不生效,则需要下面的配置
在tomcat下的solr项目
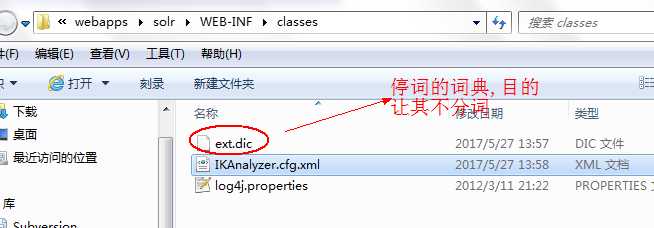
IKAnalyzer.cfg.xml的配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典
<entry key="ext_stopwords">stopword.dic;</entry>
-->
</properties>
有些特殊的词语我们在使用的过程中不需要进行分词所以需要配置停词
停词配置文件ext.dic的配置不分词的词语

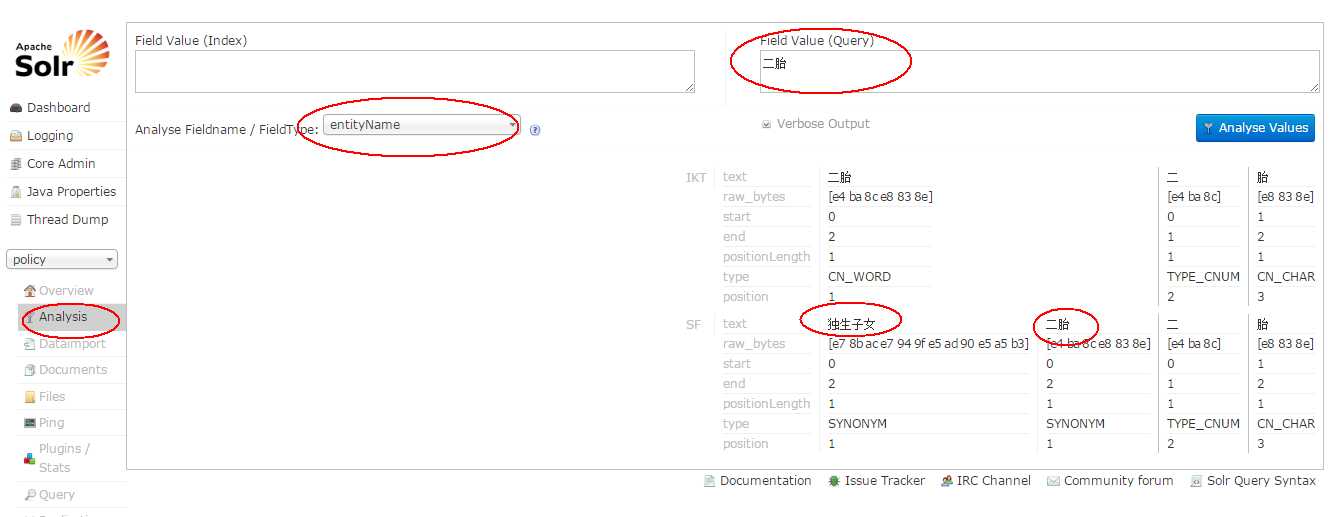
最后的运行效果如下:
标签:打包 ict comm syn text color cfg.xml body --
原文地址:http://www.cnblogs.com/dp-blog/p/7069065.html