标签:系统 通用 归一化 简单 span res 3.1 src font
协同过滤的实现
1、收集用户偏好及标准化处理
要从用户的行为和偏好中发现规律,并基于此给予推荐,如何收集用户的偏好信息成为系统推荐效果最基础的决定因素。用户有很多方式向系统提供自己的偏好信息,而且不同的应用也可能大不相同。
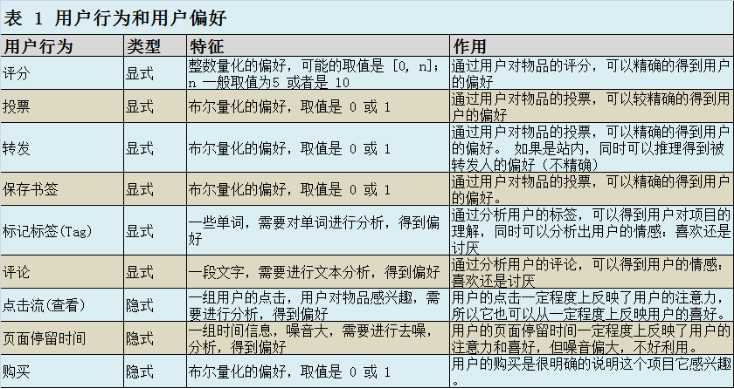
以上列举的用户行为都是比较通用的,推荐引擎设计人员可以根据自己应用的特点添加特殊的用户行为,并用他们表示用户对物品的喜好。在一般应用中,我们提取的用户行为一般都多于一种,关于如何组合这些不同的用户行为,基本上有以下两种方式:
2、数据减噪和归一化
收集了用户行为数据,我们还需要对数据进行一定的预处理,其中最核心的工作就是:减噪和归一化。
进行的预处理后,根据不同应用的行为分析方法,可以选择分组或者加权处理,之后我们可以得到一个用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,值是用户对物品的偏好,一般是 [0,1] 或者 [-1, 1] 的浮点数值。
3、找到相似的用户或物品
当已经对用户行为进行分析得到用户喜好后,我们可以根据用户喜好计算相似用户和物品,然后基于相似用户或者物品进行推荐,这就是最典型的 CF 的两个分支:基于用户的 CF 和基于物品的 CF。这两种方法都需要计算相似度。关于相似度的计算,现有的几种基本方法都是基于向量(Vector)的,其实也就是计算两个向量的距离,距离越近相似度越大。在推荐的场景中,在用 户 - 物品偏好的二维矩阵中,我们可以将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,或者将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度。
3.1 常用的相似度计算方法
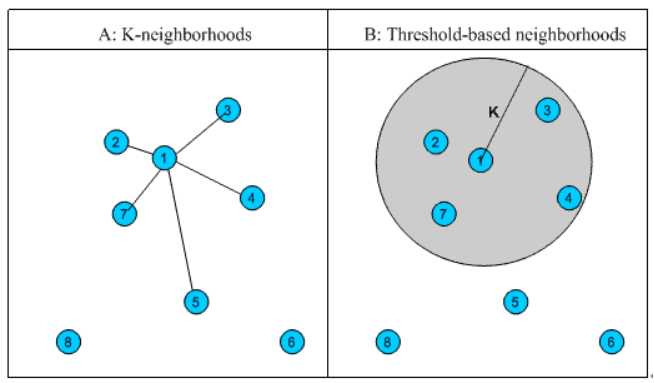
3.2 相似邻居的计算
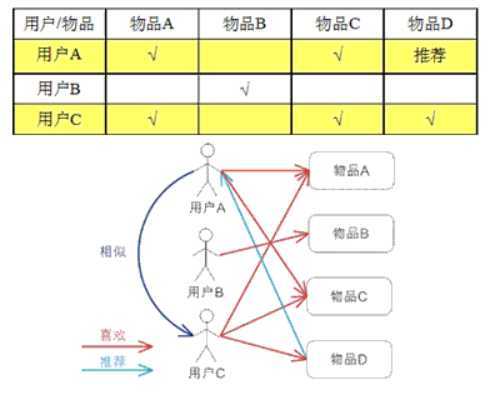
4、计算基于用户的协同过滤(User CF)
例子:
对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
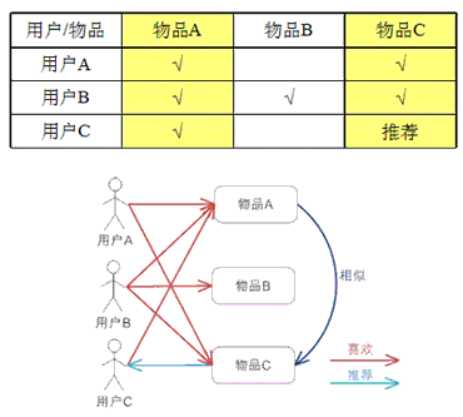
5、计算基于物品的协同过滤(Item CF)
例子:
对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
标签:系统 通用 归一化 简单 span res 3.1 src font
原文地址:http://www.cnblogs.com/ahu-lichang/p/7071754.html