标签:init beta eth 方法 als 通过 div tor nts
在我们训练模型的时候,通常会遇到这种情况。我们平衡模型的训练速度和损失(loss)后选择了相对合适的学习率(learning rate)。但是训练集的损失下降到一定的程度后就不在下降了,比如training loss一直在0.7和0.9之间来回震荡,不能进一步下降。如下图所示:
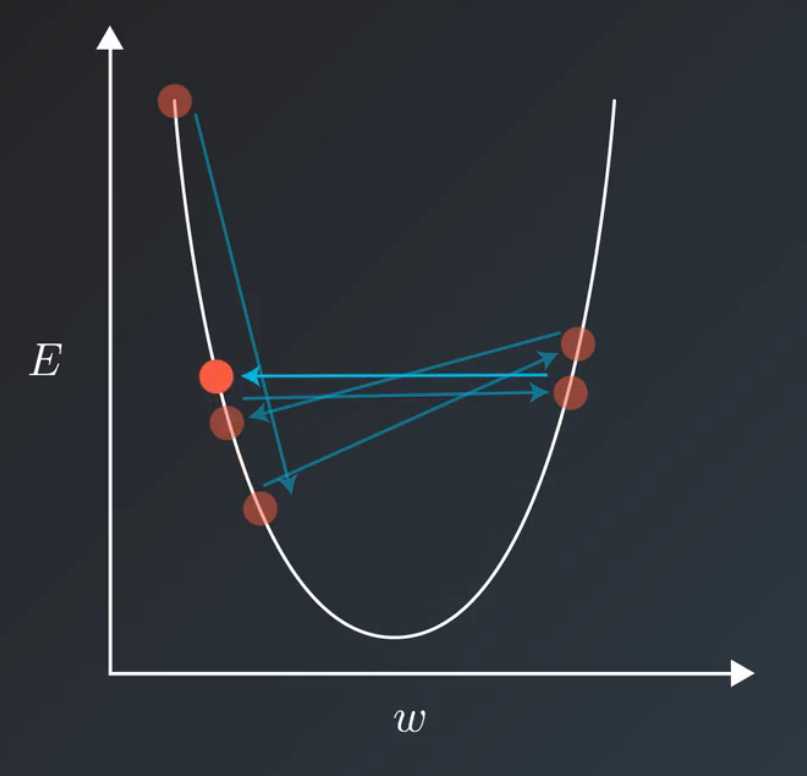
遇到这种情况通常可以通过适当降低学习率(learning rate)来实现。但是,降低学习率又会延长训练所需的时间。
学习率衰减(learning rate decay)就是一种可以平衡这两者之间矛盾的解决方案。学习率衰减的基本思想是:学习率随着训练的进行逐渐衰减。
学习率衰减基本有两种实现方法:
TensorFlow中使用tf.train.AdamOptimizer方法可以很方便的实现学习率衰减,我们来大概看下AdamOptimizer是怎样实现的。
官方文档的描述:
tf.train.AdamOptimizer class tf.train.AdamOptimizer Defined in tensorflow/python/training/adam.py. See the guide: Training > Optimizers Optimizer that implements the Adam algorithm. See Kingma et. al., 2014 (pdf). Methods __init__ __init__( learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, use_locking=False, name=‘Adam‘ ) Construct a new Adam optimizer. Initialization: m_0 <- 0 (Initialize initial 1st moment vector) v_0 <- 0 (Initialize initial 2nd moment vector) t <- 0 (Initialize timestep) The update rule for variable with gradient g uses an optimization described at the end of section2 of the paper: t <- t + 1 lr_t <- learning_rate * sqrt(1 - beta2^t) / (1 - beta1^t) m_t <- beta1 * m_{t-1} + (1 - beta1) * g v_t <- beta2 * v_{t-1} + (1 - beta2) * g * g variable <- variable - lr_t * m_t / (sqrt(v_t) + epsilon) The default value of 1e-8 for epsilon might not be a good default in general. For example, when training an Inception network on ImageNet a current good choice is 1.0 or 0.1. Note that since AdamOptimizer uses the formulation just before Section 2.1 of the Kingma and Ba paper rather than the formulation in Algorithm 1, the "epsilon" referred to here is "epsilon hat" in the paper.
可以看到,随着时间t的增加,学习率的更新方式为 lr_t = learning_rate * sqrt(1 - beta2^t) / (1 - beta1^t)
变量的更新方式为 variable <- variable - lr_t * m_t / (sqrt(v_t) + epsilon)
epsilon的缺省值可能并不适合所有模型。例如,在用感知机模型训练ImagNet数据集时,目前一个比较好的选择是1.0或0.1
标签:init beta eth 方法 als 通过 div tor nts
原文地址:http://www.cnblogs.com/max-hu/p/7078526.html