标签:tar 参数 分享 nbsp 填充 iso 一个 idt doc
参考:W3School
XML基本概念
1.XML是eXtensible Markup Language,使用DTD(Document Type Definition)来描述数据,主要是为传输和存储数据,其焦点是数据的内容。
2.所有XML元素都必须正确地关闭,XML标签对大小写敏感,没有预定义的标签(eg:<h1>),XML文档必须有根标签,XML元素必须被正确地嵌套,XML 元素是可扩展。XML可保留空白字符,必须使用引号包围XML的属性值
3.XML 元素必须遵循以下命名规则:1)名称可以含字母、数字以及其他的字符名称;2)不能以数字或者标点符号开始;3)名称不能以字符 “xml”(或者 XML、Xml)开始;4)名称不能包含空格
4.XML注释 <!-- This is a comment -->
5. CDATA 指的是不应由 XML 解析器进行解析的文本数据(Unparsed Character Data),忽略这部分内容的正确语法是:<![CDATA[ Text to be ignored ]]>
6.在 XML 中有 5 个预定义的实体引用:
< < 小于
> > 大于
& & 和号
' ‘ 省略号
" " 引号
<message>if salary < 1000 then</message> 错误
<message>if salary < 1000 then</message> 正确
XML特点
1.命名空间:元素名称是由开发者定义的,当两个不同的文档使用相同的元素名时,就会发生命名冲突。XML 命名空间属性被放置于元素的开始标签之中,并使用以下的语法:xmlns:namespace-prefix="namespaceURI"
<h:table xmlns:h="http://www.w3.org/TR/html4/"> <h:tr> <h:td>Apples</h:td> <h:td>Bananas</h:td> </h:tr> </h:table>
2.XML DOM:定义了所有 XML 元素的对象和属性,以及访问它们的方法(接口)
DOM特性:
整个文档是一个文档节点
每个 XML 标签是一个元素节点
包含在 XML 元素中的文本是文本节点
每一个 XML 属性是一个属性节点
注释属于注释节点
DOM属性:x表示一个节点对象
- x.nodeName - x 的名称
- x.nodeValue - x 的值
- x.parentNode - x 的父节点
- x.childNodes - x 的子节点
- x.attributes - x 的属性节点
DOM方法:x表示一个节点对象
- x.getElementsByTagName(name) - 获取带有指定标签名称的所有元素
- x.appendChild(node) - 向 x 插入子节点
- x.removeChild(node) - 从 x 删除子节点
Tips:DOM 处理中的普遍错误,认为元素节点包含文本。<year>2005</year>,元素节点 <year>,拥有一个值为 "2005" 的文本节点,"2005" 不是 <year> 元素的值!
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book category="children"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="web"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> <book category="Literature "> <title >托斯卡纳艳阳下</title> <author>弗朗西丝·梅耶斯</author> <year>2006</year> <price>29.8</price> </book> </bookstore>
说明:根节点 <bookstore> 有四个 <book> 节点,每个 <book> 节点有四个子节点:<title>, <author>, <year> 以及 <price>,其中每个节点都包含一个文本节点,"Harry Potter", "J K. Rowling", "2005" 以及 "29.99"
创建XML文件
基于python语言,调用xml.dom模块创建xml的API
#coding=utf-8 import xml.dom.minidom #在内存中创建一个空的文档 doc = xml.dom.minidom.Document() #创建一个根节点bookstore对象,名为root root = doc.createElement(‘bookstore‘) #设置根节点的属性 root.setAttribute(‘name‘, ‘Sisyphe Bookstore‘) root.setAttribute(‘address‘, ‘老街‘) #将根节点添加到文档对象中 doc.appendChild(root) bookList = [{‘title‘ : ‘Harry Potter‘,‘author‘ : ‘J K. Rowling‘, ‘year‘ : 2005,‘price‘:29.99}, {‘title‘ : ‘Learning XML‘,‘author‘ : ‘Erik T. Ray‘, ‘year‘ : 2003,‘price‘:39.95}, {‘title‘ : ‘托斯卡纳艳阳下‘,‘author‘ : ‘弗朗西丝·梅耶斯‘, ‘year‘ : 2006,‘price‘:29.8} ] for i in bookList : nodeBookstore = doc.createElement(‘bookstore‘) nodeTitle = doc.createElement(‘title‘) nodeTitle.appendChild(doc.createTextNode(str(i[‘title‘]))) #给叶子节点name设置一个文本节点,用于显示文本内容 nodeAuthor = doc.createElement("author") nodeAuthor.appendChild(doc.createTextNode(str(i["author"]))) nodeYear = doc.createElement("year") nodeYear.appendChild(doc.createTextNode(str(i["year"]))) nodePrice = doc.createElement("price") nodePrice.appendChild(doc.createTextNode(str(i["price"]))) #将各叶子节点添加到父节点bookstore中, nodeBookstore.appendChild(nodeTitle) nodeBookstore.appendChild(nodeAuthor) nodeBookstore.appendChild(nodeYear) nodeBookstore.appendChild(nodePrice) root.appendChild(nodeBookstore) #最后将bookstore添加到根节点root中 #开始写xml文档 fp = open(‘C:\Users\HP\Desktop\BookStore.xml‘, ‘w‘) doc.writexml(fp, indent=‘\t‘, addindent=‘\t‘, newl=‘\n‘, encoding="utf-8")
解析源码:
1.minidom.Document() 创建一个空白xml文档树对象。每个xml文档都是一个Document对象,代表着内存中的DOM树
2.doc. createElement(tagName) 创建xml文档节点,参数表示要生成节点的名称
3.node.setAttribute(attname, value) 给节点添加属性值对(Attribute)
4.doc.createTextNode(data) 给叶子节点添加文本节点
5.node.appendChild(nodeName) 将某个节点添加到节点node下
6.writexml(writer, indent, addindent, newl, encoding) 将内存中xml文档树写入文件中
writer是文件对象
indent是每个tag前填充的字符,如:’ ‘,则表示每个tag前有两个空格
addindent是每个子结点的缩近字符
newl是每个tag后填充的字符,如:’\n’,则表示每个tag后面有一个回车
encoding是生成的XML信息头中的encoding属性值,在输出时minidom并不真正进行编码的处理,如果你保存的文本内容中有汉字,则需要自已进行编码转换。
writexml方法是除了writer参数必须要有外,其余可以省略。
输出结果:
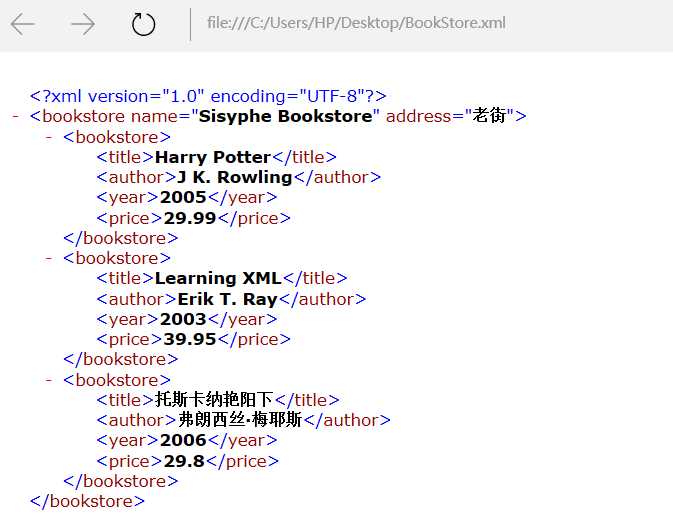
没有编码问题,给自己一个蜜汁微笑

乏善可陈的下午,Happy Ending!
标签:tar 参数 分享 nbsp 填充 iso 一个 idt doc
原文地址:http://www.cnblogs.com/Ryana/p/7091114.html