标签:用两个 ber 分享 名称 process pre 自定义 重复 好的
---恢复内容开始---
模块的概念
前面讲了一些内置模块我们可以知道,我么们在进行import的时候后跟的os或者subprocess等都是可以找到他们存在的位置的
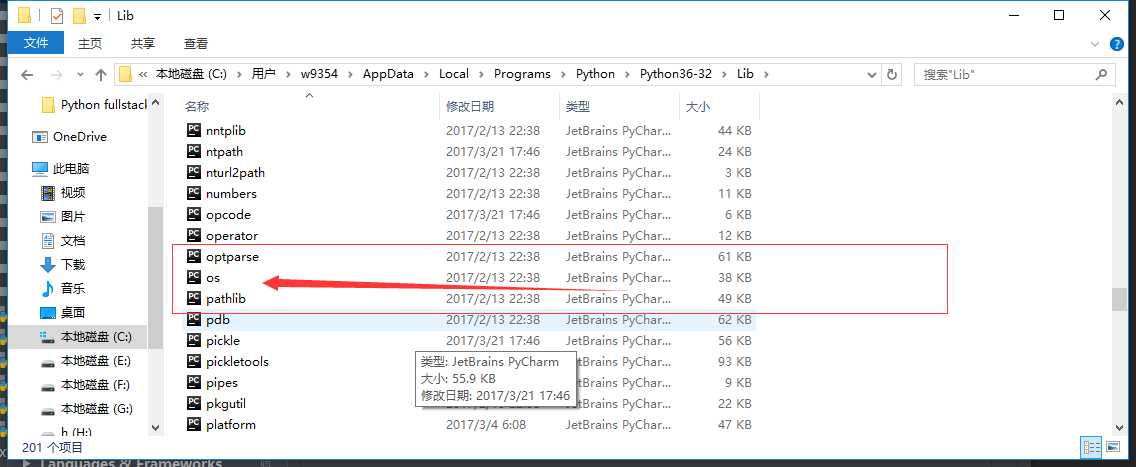
这里我们可以看到在python下的lib文件夹内有这一个个的.py文件这些都是一些写好的含有多个可被调函数的文件,
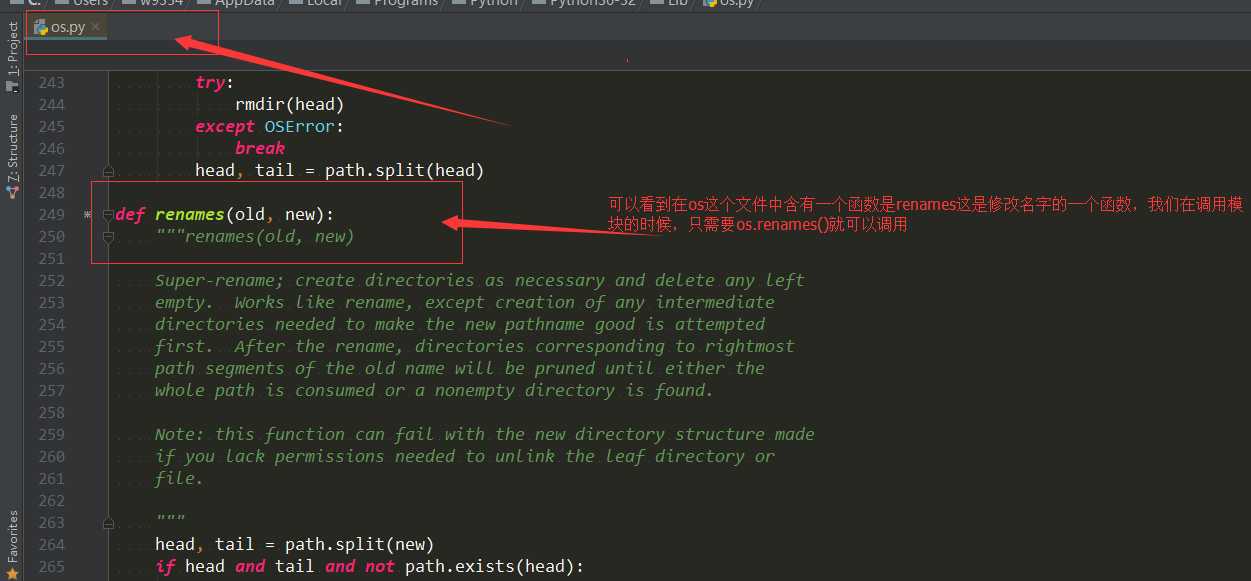
这样我们应该可以看懂一件事,那就是我们会把一整个写好了函数的.py文件定义为模块
模块只有被调用或者直接使用两种途径
这两者是不可以都能做得
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
所以,模块一共三种:
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
模块是什么我们已经知道了但是一个模块是怎么导入进来的呢
模块的调用
import os,sys
这样我们就进行了两个模块的调用
不过不建议这么写他的可读性不强,容易混乱
import sys
import os
这样我们就可以清晰的看出我们调用了哪个模块,这个模块具体是什么,我也可以在后面进行注释的时候,更方便的添加为什么需求这个模块
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?答案就是解释器有自己的搜索路径,存在sys.path里。

因此若像我一样在当前目录下存在与要引入模块同名的文件,就会把要引入的模块屏蔽掉。
当import foo时,首先会立刻创建一个新的名称空间,用来存放所有foo.py中定义的名字;然后会在该名称空间内执行foo.py内所
有的代码,最后需要知道的是import关键字
就是定义了一个名字,只不过此刻我们用import定义的是一个模块名字foo,该名字就是指
向foo.py的名称空间,而foo.的方式就是从该名称空间里找名字,可以使用foo.__dict__来查看这些名字。
在新建的名称空间里执行源文件(foo.py)代码时,所有对全局名称空间的引用或修改,都是以foo.py为准,而不是当前文件(test.py)的全局名称空间
注意1:
个模块可以在当前位置import多次,但只有第一次导入会执行源文件内的代码,原因是:第一次导入就会将模块包含的内
容统统加载到内存了,以后在当前文件位置的导入都是指向内存中已有的模块
这里做个注解 当我们定义一个变量的时候也会发现x=1 和 b=1指向的都是一个内存地址,其实导入模块也是一样,在我们第一次import的时候他导入内存这个过程会进行一次运行,当我们再次导入时,内存中已经有这个内容了,我需要做的就是简单的将第二次内容直接绑定过去就可以了,两次import导入只有第一次真正开辟内存空间,第二次只是做了一次内存绑定而已。
注意2:
我们也可以给导入模块定义一个小名或者说别名通常出现在我需要使用的模块恰好跟我要进行编写的函数名称重复了,那么我们调用的模块可以换个名字
import os as ossss import 导入的模块 as 定义的别名
第二种调用方式,如果我们只想调用另一个模块内的某一个功能
我们就可以通过
from os import path
from 模块名称 import 模块内的需要的一个函数
from os import path
print(path.dirname(__file__))
返回的结果是当前目录的上级目录
__file__意思是返回当前路径的相对路径
这个方式不是特别常用吧
下面讲解包的用法
包的初衷
我们在未来的工作中是会出现一个这样的问题的,我们的一个项目是不可能由一个人进行完成的,即使完成了也会有很久很久的时间去进行这样对于一个公司来说实在是得不偿失了,所以多人进行写作是最好的解决方案,解决了时效性的同时会引起一个新的问题,多人协作的时候会使用相同代码同时也会制作一个个时候任务的模块,这些模块在我们定义的时候就会出现重复的现象,举个例子你写了一个模块叫time.py用来定义自己的时间格式那么别人呢会不会也定义一个模块叫做time.py呢。如果执行文件进行调用的时候到底调用哪个呢?
为了解决这一类问题我们引入了包的概念
每个人建立说与自己的一个独立的文件夹,这个文件夹专门用来存放本人使用的模块
这样就解决了模块名冲突的问题
那么我们怎么去做呢
现在开始讲解
python Packaget翻译成中文就叫做python包文件
在pycharm 2017中这里
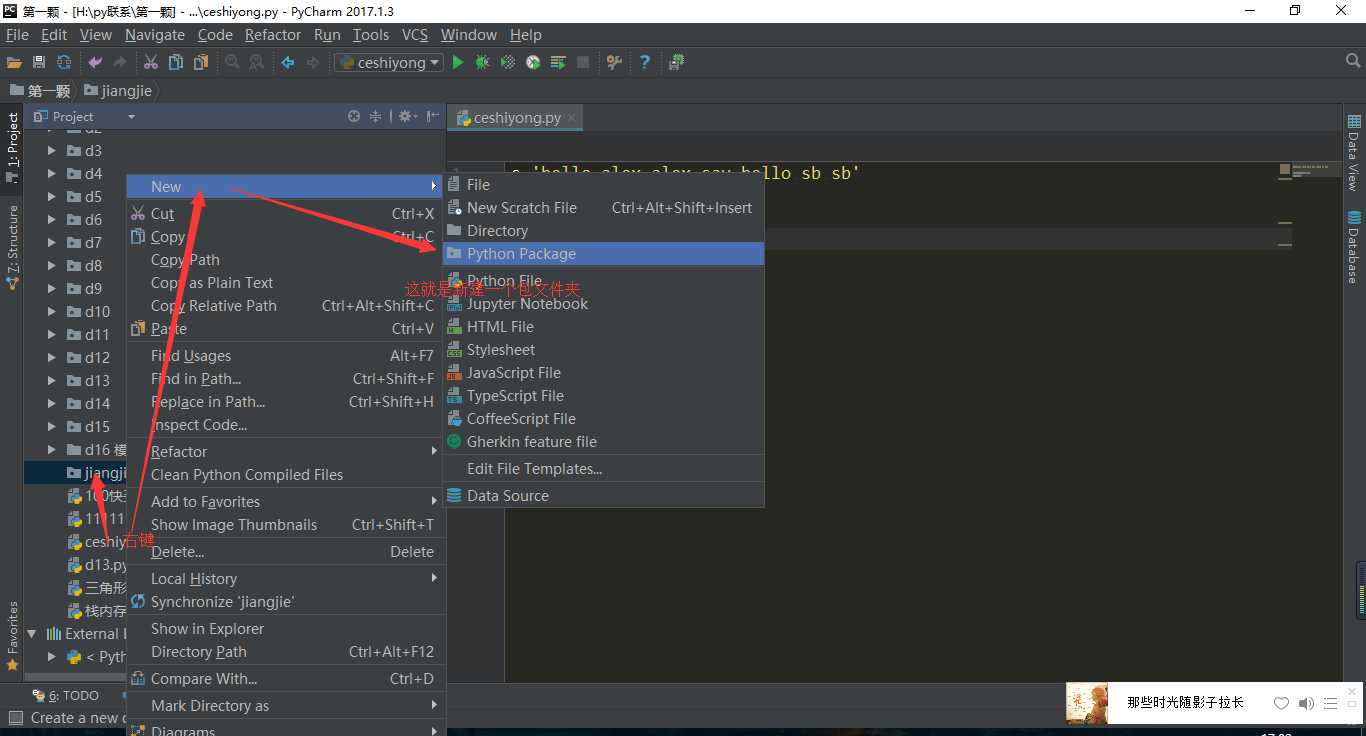
这样我们就创建了一个包文件夹

我们创建一个包文件夹和一个普通文件夹做对比可以看到,创建一个包文件夹的时候会自动创建一个__init__.py文件
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字。
这里先不要管这个文件是什么后面会做讲解
这是我们就创建了一个包文件夹bar它的作用呢就是存放我们功能实现者自己的一些模块

我要怎么去调用bar内模块到bin内呢
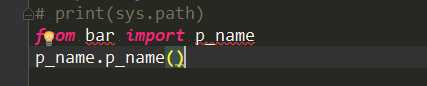
这用就可以了
只需要做from 包名字 import 模块名
就可以正常的调用了
第二种情况
一个包内 模块p_name调用模块p_number后 让bin直接调用p_name
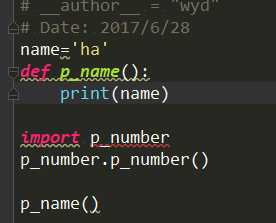
这样就可以完成了
如果上面不进行更改的情况下我们尝试调用以下
常规情况下bin直接调用两个模块
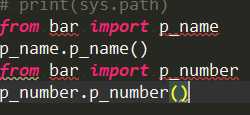
如何做到调用一个p_name直接出现p_number里的内容呢
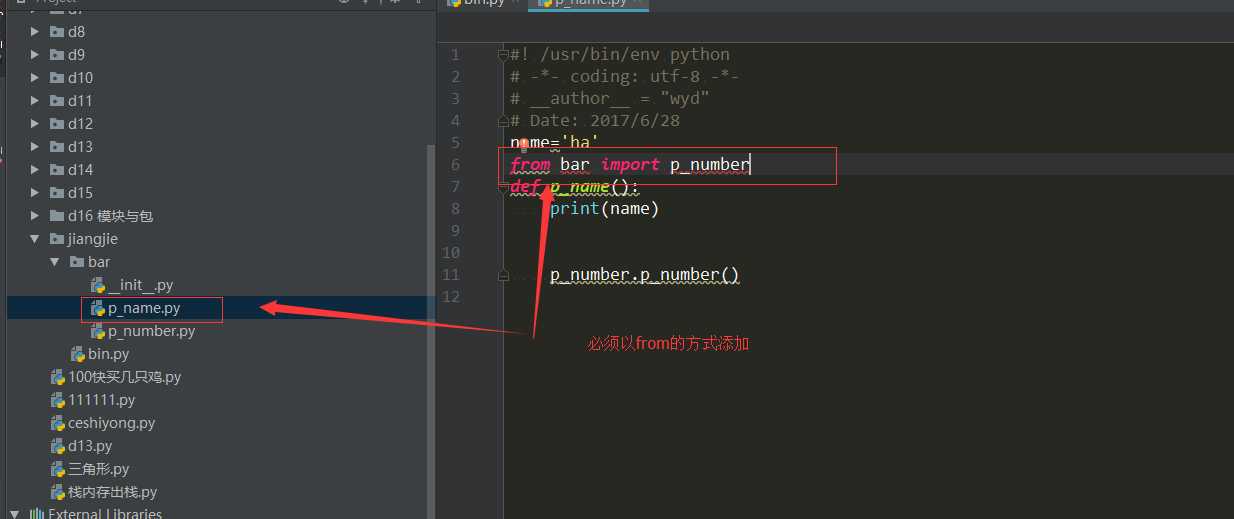
这里是因为我们在调用任何一个模块的时候都是在可执行文件的当前目录为环境变量中第一个环境变量中路径
所以我们咋运行bin的时候是以jiangjie为第一个环境变量中路径的,这里bin配置的from bar import p_name 是因为 from可以找到bar包在从包里找p_name文件的
但是p_name和p_number是同一个目录下他俩是可以直接进行import的
当我想要通过bin调用 p_name同时让p_name直接调用p_number的时候我的当前目录是 jiangjie所以会报错无法找到的,那么我们怎么解决这个问题呢,方法就是在p_name调用p_number的时候直接改写成from bar import p_number
这样我们就可以在bin下直接调用了
以上就是关于包的问题
下面拓展一个问题
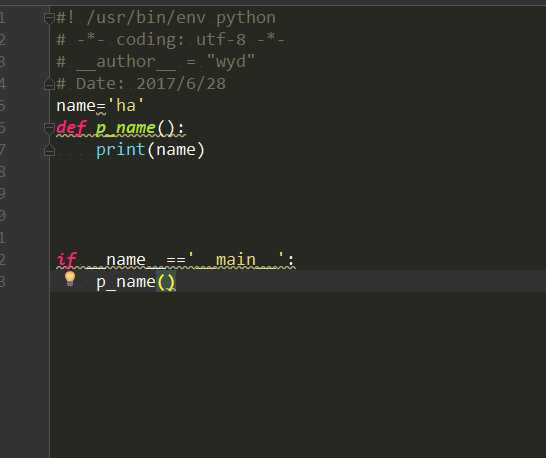
通常我们在写完一个模块后都会在后面加上一个
if __name__ == ‘__main__‘:
这是问了我们在测试模块的时候会进行一个运行的过程
而我交给别人使用的时候我需要去掉p_name()这一项,考虑到会存在忘记或者我只调用不运行的情况,如果我们不加上if __name__ == ‘__main__‘:可能造成一些不必要的问题
那么是什么原理呢?
我们做一个对照
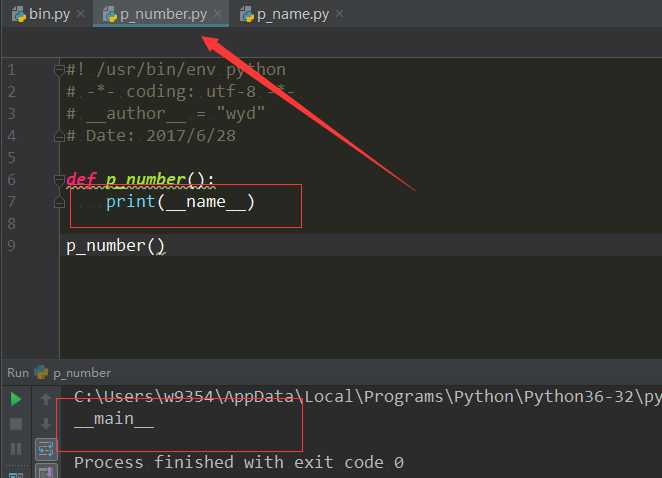
当我们在p_muber下直接打印__name__可以看到返回的是__main__
那么当我们用别的文件调用这个模块在看看
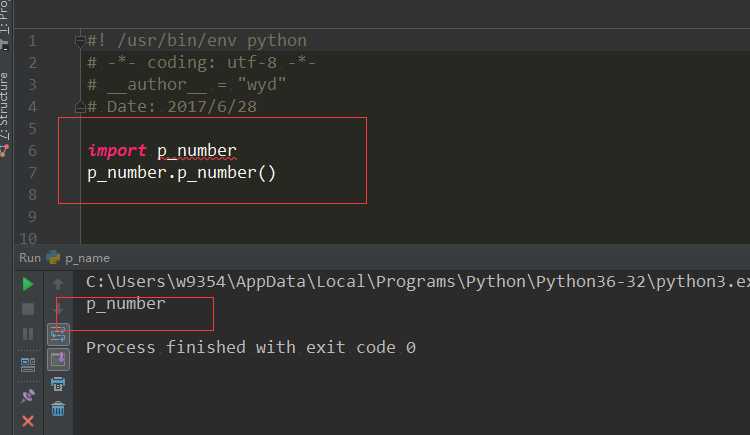
当我们调用的时候打印的就是模块名
试想一下
我们在我么写的哪个模块
调试的时候进行一个
if __name__ == ‘__main__‘:
函数名()
这样在别人调用的时候就不会运行了
多么方便
标签:用两个 ber 分享 名称 process pre 自定义 重复 好的
原文地址:http://www.cnblogs.com/935415150wang/p/7091227.html