标签:处理对象 面向对象 lte git master 时间 设置 合成 字节
数据结构
核心之数据集RDD
俗称为弹性分布式数据集。Resilient Distributed Datasets,意为容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。
RDD的特点
优点:
1编译时类型安全
2面向对象的编程风格 ,直接通过类名点的方式来操作数据
缺点:
1序列化和反序列化的性能开销
因为RDD只有数据,没有数据结构,无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化.
2GC的性能开销
频繁的创建和销毁对象, 势必会增加GC
RDD曾是spark处理数据最核心的基本单元,而spark在1.6推出了新的数据处理对象DataFarme和DataSet。
DataFarme
它在RDD的基础上增加了数据的类型。DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
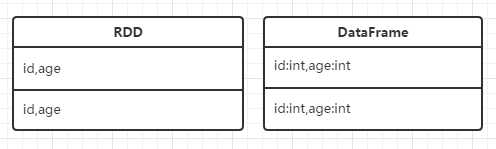
它针对RDD的弱点做了如下优化
序列化与反序列化的性能开销
这个不用说,因为有了数据结构,所以节省了这一块。具体上,DataFrame引入了schema : RDD每一行的数据, 结构都是一样的. 这个结构就存储在schema中. spark通过schame就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了.
GC的性能开销
DataFrame引入了off-heap : 意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时, 就直接操作off-heap内存. 由于Spark理解schema, 所以知道该如何操作.
但是,DataFrame针对RDD的弱点做了优化,但是它却没有了RDD类型安全和面向对象的优点。可谓是有得必有失。人生不过是取舍。
Dataset
结合了RDD和DataFrame的优点。它同时具备了RDD的类型安全和面向对象优点,同时也具备了DataFrame的schema和off-heap。同时,它引入了新的概念Encoder。能够按需访问,而无需访问整个对象。
总结
1:RDD类型安全,面向对象。
2:RDD仅有数据没有数据结构,序列化开销大。DataFrame引入schema使其具备了数据结构。同时其生命周期脱离了JVM和频繁的GC回收。因此其不再是字节码,而是二进制,又因为schema,所以操作系统和spark能够快速识别。但DataFrame失去了RDD类型安全面向对象的优点。
3:DataSet具体RDD和DataFrame的共同优点。同时能够按字段访问,无需操作整 个对象。
4:就优点和性能来说 RDD<DataFrame<DataSet
组件
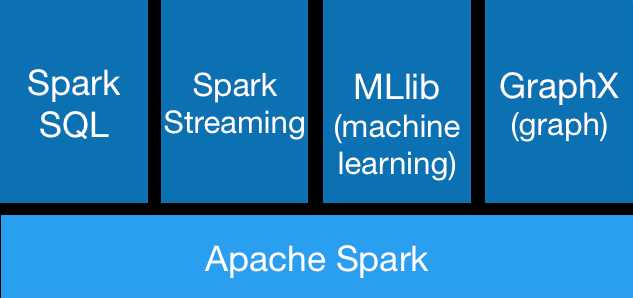
Spark SQL 通常用于交互式查询,但这一领域同类产品太多,更多作为MapReduce的替代者,用于批量作业。
Spark Streaming 流式batch处理。主要同类产品为storm。除了storm延迟低以外,想不出不使用spark streaming的理由。(spark streaming 2.2以后延迟将降低到1ms以内;除了spark不稳定和不兼容的理由以外)
MLlib机器学习, 不了解。
GraphX图计算,不了解。
Spark core spark的核心框架,以上四大组件都依赖于core。
核心概念
client 客户端进程,负责提交作业到Master。
master Standalone模式中主控节点,负责接收Client提交的作业,管理Worker,并命令Worker启动分配Driver的资源和启动Executor的资源。
worker Standalone模式中slave节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor。
Driver 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
Executor 即真正执行作业的地方,一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task。
图片来自:https://github.com/lw-lin/CoolplaySpark/blob/master/Spark%20Streaming%20%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E7%B3%BB%E5%88%97/1.1%20DStream%2C%20DStreamGraph%20%E8%AF%A6%E8%A7%A3.md
常见概念
未完待续
比较优势
网上曾有人号称,spark要取代hadoop。目前看来,spark并无这样的打算。事实上,hadoop已经成为大数据领域的标准,怎么取代呢。spark官方也从未说过这样的话。比如分布式数据存储,spark官方并未有hdfs的替代方案。资源管理调度,spark有自己的想法,但远远达不到生产阶段。除了standnode,还是得深度依赖mesos和yarn。实际上,spark只是hadoop的一个有益补充,如果真的要说替代的话,也只能说是替代mapreduce和storm。
spark的优势体现在:
1:内存计算。这是最广为人知的一点。但是spark在宽依赖的时候也得进行suffle,面且所说,hadoop3.0也引入了内存计算。内存计算绝不是spark引以为傲的优势。据说,在资源紧张spark根本没有多少内存进行计算的情况下,同样的配置和数据条件下,spark依然比mapreduce效率高。(据官网,内存计算,spark效率是mapreduce10-100倍,磁盘计算,spark效率是mapreduce10倍,非内存计算没有测试过)
2:弱化了批处理和实时计算。在spark诞生之前,大数据分成了泾渭分明的两大阵营。批处理和实时,分别以hadoop(mapreduce)和storm为代表。spark以spark sql和spark streaming将两者整合了起来。当然,这里的弱化绝不仅仅是简单的将实时和批处理技术整合成一家。spark创造性的将数据整合为RDD,可大可小,时间可以自行设置。在spark里,数据将是流动的,各种RDD可以自由组合计算。
3:DAG。当然DAG是一种编程思想,并非spark独有。DAG加RDD为spark带来了高容错的特性。如果处理失败,只需恢复失败的RDD即可。
4:得益于scala语言的简洁强大,spark提供了许多强大的算子。hadoop只提供了map及reduce(shuffle阶段除外),storm trident提供了更多的算子,但是效率是个问题。比如,wordcount的例子,分别用mapreduce,storm和spark开发,开发效率上spark会有很大的优势。
5:storm进行批处理(minibath)的trident效率低,容错低。它是将数据缓存到本地,而streaming提供了更多的选择,比如streaming提供了lazy的kafka driect api。效率更高,容错更高,占用资源更少。
参考:
http://www.36dsj.com/archives/61155
http://blog.csdn.net/wo334499/article/details/51689549
标签:处理对象 面向对象 lte git master 时间 设置 合成 字节
原文地址:http://www.cnblogs.com/eryuan/p/7089724.html