标签:class 交互 发布 服务 大数据应用 session 平衡 jpg exist
1.分布式与集群简单理解:
分布式:不同的多台服务器上面部署不同的服务模块,他们之间通过RPC/RMI之间通信和调用,对外提供服务和组内协作。
集 群:不同的多台服务器上面部署相同的服务模块,通过分布式调度软件进行统一的调度,对外提供服务和访问。
2.NoSQL定义:NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,泛指非关系型的数据库。NoSQL数据库的产生就是为了解决大规模数据集合,多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
3.NoSQL特点:
(1)易扩展:NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
(2)大数据量高性能:NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MySQL使用Query Cache,表的更新都会导致Cache失效,是一种大粒度的Cache,在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,
是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了
(3)多样灵活的数据模型:NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。
4.大数据时代3V:Volume(海量),Variety(多样),Velocity(实时);互联网需求三高:高并发,高可扩,高性能
5.关系型数据库遵循ACID规则:
(1)A (Atomicity):原子性:事务里的所有操作要么全部做完,要么都不做,只要有一个操作失败,整个事务就失败,需要回滚。
(2)C (Consistency) 一致性:数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
(3)I (Isolation) 独立性:指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
(4)D (Durability) 持久性:指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
6.CAP理论:Consistency(强一致性),Availability(可用性),Partition tolerance(分区容错性。CAP理论就是说在分布式存储系统中,最多只能实现
上面的两点。而由于网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。分布式架构的时候必须做出取舍,在一致性和可用性之间取一个平衡。
7.因为大型系统往往由于地域分布和极高性能的要求,不可能采用分布式事务来完成这些指标,为了解决这种关系数据库强一致性引起的可用性降低问题,BASE理论应运而生。BASE是下面三个术语的缩写:基本可用(Basically Available)软状态(Soft state) 最终一致(Eventually consistent);它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体的伸缩性和性能上的改观。
8.Redis是一个高性能的(key-value)分布式内存数据库,基于内存运行并支持持久化的NoSQL数据库,有五种数据类型:string,list,set,zset,hash.
Redis通过单进程模型来处理客户端的请求以及对对读写等事件的响应,它是是通过对linux底层的epoll(Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃情况下的系统CPU利用率)函数的包装来做到的。
9.Redis可以用作内存存储和持久化(redis支持异步将内存中的数据写到硬盘上,同时不影响继续服务),可以使用Redis模拟实现HttpSession的功能,使用Redis发布、订阅消息系统,使用Redis做定时器、计数器等。
10.Redis的key的相关用法:
set k1 v1 ex 3 设置string类型的键k1,值为“v1”,并设置过期时间为3s keys * 返回所有的key exists key k1 判断键k1是否存在,(存在1否则0) del key 删除key expire key 设置key的过期时间 ttl key 返回key距离过期剩余的时间 type key 返回可以的类型
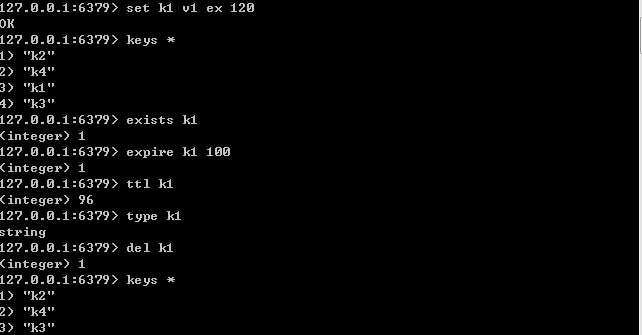
string:redis最基本的类型,一个key对应一个value。string类型是二进制安全的。即redis的string可以包含任何数据。比如jpg图片或者序列化的对象 一个redis中字符串value最多可以是512M
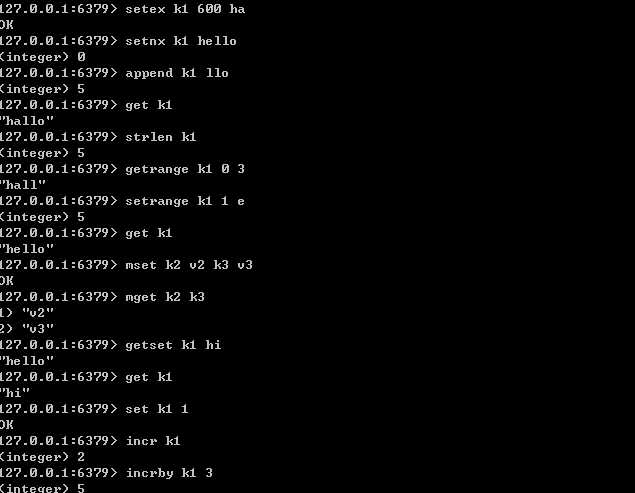
string的相关操作:
set/get/del/append/strlen/ incr/desr/incrby/descby 使用这组命令时key必须是数字 getrange/setrange mset/mget getset 先get再set,返回key的旧值 setex set的时候同时设定过期时间 setnx 如果key不存在则设置key-value,存在则什么都不做
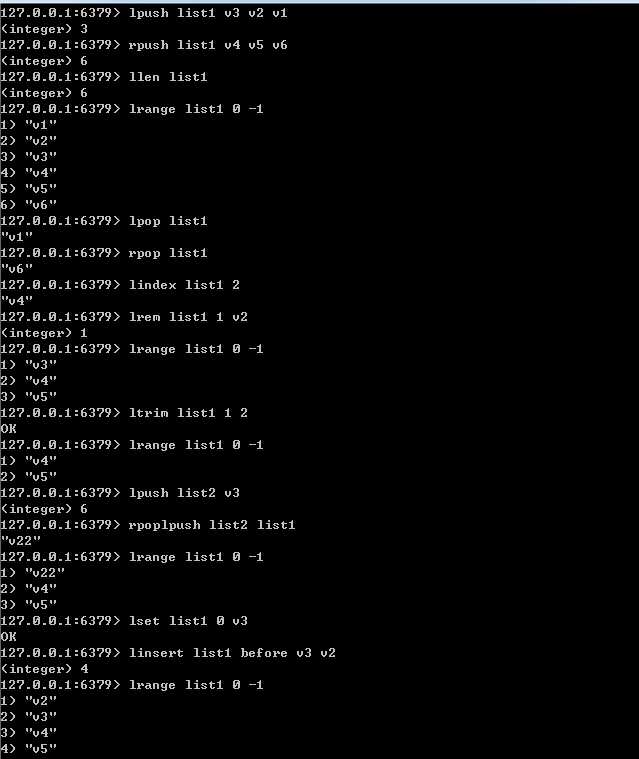
list:列表是简单的字符串列表,按照插入顺序排序。可以添加元素到列表的头部或者尾部。它的底层实际是个链表,因此无论操作头和尾的元素效率都极高,但是对中间元素进行操作,效率就很惨淡了
list的相关操作:
lpush/rpush/lpop/rpop/llen/ lrem key count value 删count个值为value的元素,返回实际删除的元素个数 ltrim key start end 截取指定范围的值后再赋值给key rpoplpush source destination 移除source列表的最后一个元素,并将该元素添加到destination列表并返回
lset key index value
linsert key before/after pivot value1 value2 在值为pivot的元素之前/后插入value1 value2
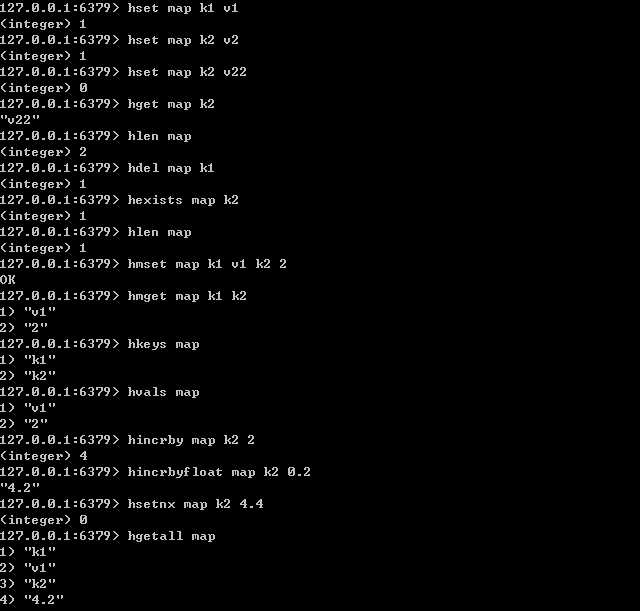
hash :一个string类型的field和value的映射表,hash特别适合用于存储对象。类似Java里面的Map<String,Object>
hash 相关的操作:
hset/hget/hmset/hmget/hgetall/hdel/hlen hexists key field 在hash里面是否存在某个key hkeys/hvals 返回所有的key/value hincrby/hincrbyfloat key field value 对key中某个元素的value自增 hsetnx key field value 对key中某个元素field 赋值,如果该field存在则什么都不做直接返回
标签:class 交互 发布 服务 大数据应用 session 平衡 jpg exist
原文地址:http://www.cnblogs.com/pepper7/p/7095683.html