标签:完成 分布式 logs width drive 控制 src res 实时
权作《Spark快速大数据分析》学习笔记
定义:Spark是一个用来实现 快速 而 通用 的集群计算平台;(通用的大数据处理引擎;)
改进了原Hadoop MapReduce处理模型,体现在三方面:
a. 速度;(内存计算)
b. 不仅支持批处理,还支持交互式查询(速度快的成果)、流式计算、机器学习、图计算等;(迭代算法)
c. 丰富的API和易用性;
Spark组件主要组成:
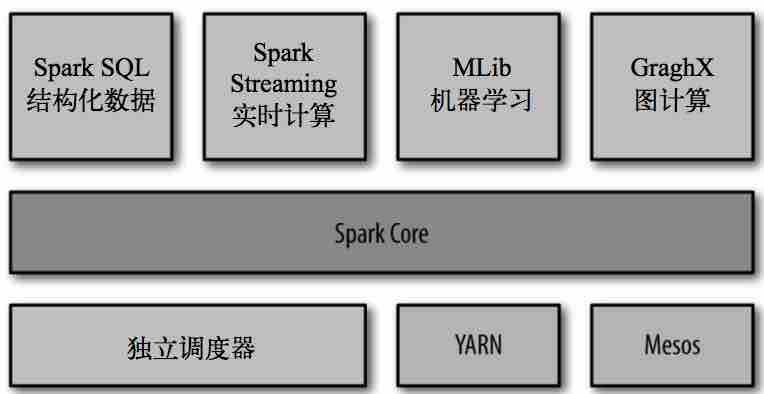
Spark Core:实现了Spark的核心功能,包含任务调度、内存管理、与存储系统交互、错误恢复等;定义了RDD API;
RDD:(resilient distributed dataset)弹性分布式数据集,表示分布在多个计算节点上可以平行操作的元素集合;
通过创建RDD来操作完成 统计计算,这些计算会自动地 在集群上并行进行。
Spark主要的编程抽象;
Spark SQL:Spark操作结构化数据的程序包;
Spark Streaming: Spark 提供的对实时数据进行流式计算的组件 ;
MLlib: 提供常见的机器学习(ML)功能的程序库 ;
GraphX: 是用来操作图(比如社交网络的朋友关系图)的程序库,可以进行并行的图计算;
Spark shell:和其他 shell 工具不一样的是,在其他 shell 工具中你只能使用单机的硬盘和内存来操作数据;
可用来与分布式存储在许多机器的内存或者硬盘上的数据进行交互,并且处理过程的分发由 Spark 自动控制完成;
动作原理:
driver program
executor
标签:完成 分布式 logs width drive 控制 src res 实时
原文地址:http://www.cnblogs.com/mzzcy/p/7106080.html