标签:guid size port mpi highlight 总线 time 专用 soft
#include <iostream>
int main()
{
#pragma omp parallel
{
std::cout << "Hello World!\n";
}
}
#pragma omp parallel 仅在您指定了 -fopenmp 编译器选项后才会发挥作用。在编译期间,GCC 会根据硬件和操作系统配置在运行时生成代码,创建尽可能多的线程。user@NLP ~/vsworksapce $ g++ hello.cpp user@NLP ~/vsworksapce $ ./a.out Hello World! user@NLP ~/vsworksapce $ g++ hello.cpp -fopenmp user@NLP ~/vsworksapce $ ./a.out Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World!
#include <omp.h>
#include <iostream>
int main()
{
int number_threads = 1;
omp_set_num_threads(number_threads) //方法二
#pragma omp parallel num_threads(number_threads) //方式一
{
std::cout << "Hello World!\n";
}
}
pragma omp sections 和 pragma omp parallel 之间的代码将由所有线程并行运行。pragma omp sections 之后的代码块通过 pragma omp section 进一步被分为各个子区段。每个 pragma omp section 块将由一个单独的线程执行。但是,区段块中的各个指令始终按顺序运行。#include <iostream>
int main()
{
#pragma omp parallel
{
std::cout << "parallel \n";
#pragma omp sections
{
#pragma omp section
{
std::cout << "section1 \n";
}
#pragma omp section
{
std::cout << "sectio2 \n";
std::cout << "after sectio2 \n";
}
#pragma omp section
{
std::cout << "sectio3 \n";
std::cout << "after sectio3 \n";
}
}
}
}
//运行结果
user@NLP ~/vsworksapce $ g++ openMP12.cpp -fopenmp
user@NLP ~/vsworksapce $ ./a.out
parallel
section1
sectio2
after sectio2
sectio3
after sectio3
parallel
parallel
parallel
parallel
parallel
parallel
parallel
parallel
parallel
parallel
parallel
4、还有一些omp_get_wtime、for循环中的并行处理、OpenMP 实现锁和互斥、以及firstprivate和lastprivate指令
等一些openMP的使用可以参考(https://www.ibm.com/developerworks/cn/aix/library/au-aix-openmp-framework/)。
1、简单的测试--不限制线程数量
#include <omp.h>
#include <time.h>
#include <iostream>
#include <ctime>
int main()
{
time_t start,end1;
time( &start );
int a = 0;
#pragma omp parallel for
for (int i = 0; i < 100; ++i)
{
for (int j = 0; j < 1000000000; j++);
//std::cout<< a++ << std::endl;
}
time( &end1 );
double omp_end = omp_get_wtime( );
std::cout<<std::endl;
std::cout<<"Time_used " <<((end1 - start))<<"s"<<std::endl;
std::cout<<"omp_time: "<<((omp_end - omp_start))<<std::endl;
return 0;
}


2、简单的测试--限制线程数量
#include <omp.h>
#include <time.h>
#include <iostream>
#include <ctime>
int main()
{
time_t start,end1;
time( &start );
int a = 0;
double omp_start = omp_get_wtime( );
#pragma omp parallel for num_threads(8)
for (int i = 0; i < 100; ++i)
{
for (int j = 0; j < 1000000000; j++);
}
time( &end1 );
double omp_end = omp_get_wtime( );
std::cout<<std::endl;
std::cout<<"Time_used " <<((end1 - start))<<"s"<<std::endl;
std::cout<<"omp_time: "<<((omp_end - omp_start))<<std::endl;
return 0;
}



3、简单测试--提升数据量,限制线程数量
#include <omp.h>
#include <time.h>
#include <iostream>
#include <ctime>
int main()
{
time_t start,end1;
time( &start );
int a = 0;
double omp_start = omp_get_wtime( );
#pragma omp parallel for num_threads(12)
for (int i = 0; i < 1000; ++i)
{
for (int j = 0; j < 1000000000; j++);
}
time( &end1 );
double omp_end = omp_get_wtime( );
std::cout<<std::endl;
std::cout<<"Time_used " <<((end1 - start))<<"s"<<std::endl;
std::cout<<"omp_time: "<<((omp_end - omp_start))<<std::endl;
return 0;
}
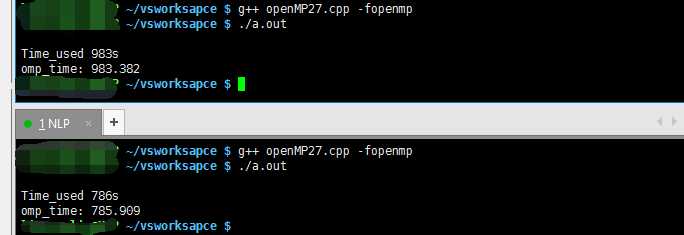
4、简单测试--降低数据量,限制线程数量
#include <omp.h>
#include <time.h>
#include <iostream>
#include <ctime>
int main()
{
time_t start,end1;
time( &start );
int a = 0;
double omp_start = omp_get_wtime( );
#pragma omp parallel for
for (int i = 0; i < 1000; ++i)
{
for (int j = 0; j < 10000; j++);
}
time( &end1 );
double omp_end = omp_get_wtime( );
std::cout<<std::endl;
std::cout<<"Time_used " <<((end1 - start))<<"s"<<std::endl;
std::cout<<"omp_time: "<<((omp_end - omp_start))<<std::endl;
return 0;
}
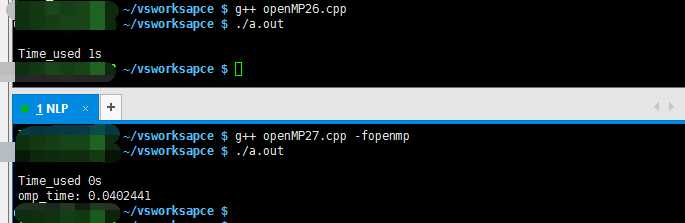
Guide into OpenMP : http://bisqwit.iki.fi/story/howto/openmp/
标签:guid size port mpi highlight 总线 time 专用 soft
原文地址:http://www.cnblogs.com/bamtercelboo/p/7107009.html