标签:范围 file 分配 排序 com 加载 文件 分布式 oop
1、hbase主要通过行主键,列主键,及时间这样的索引找到具体的值的,其中行主键以及主键(即列名)是字典序列存储的,而时间是根据递减排序的。其中列族的多少是确定的,在列族中的列的个数没有限制。hbase中对于列值为空的值不存储。
2、hbase中扩展及负载均衡的基本单元是region,他本质上是以行键排序的连续存储区域。如果region太大系统会进行拆分,如果region文件太小会进行相应的合并。每台服务器可以加载多个region区域,每个region区域仅能被一个服务器加载,region有最佳大小大约1G~2G,每台服务器的加载region区域个数在10~1000。
3、hbase有客户端api提供用户进行简单的查询操作,可以通过scan操作查询某一时间范围的指定的数据。
4、hbase中数据是存储在Hfile中的,Hfile文件其实存储的是经过排序的键值映射结构。每一个hfile文件都有一个索引,通过扫描整个磁盘就可以实现查询。在内存的块索引中进行二分查找,确定要找的数据的键,再根据键值结果确定到具体的数据。存储文件在hadoop的集群上,保证给hbase一个可扩展、持久的、冗余的存储层。
hbase中的数据更新是将数据先写入提交日志中,再将数据写入内存中的memstore中,一旦memstore中的数据满了,系统会在开一个memstore代替原来的memstore然后将原来的memstore作为文件写入Hfile文件中,然后删除没有提交日志,不删除没有持久化数据的日志。
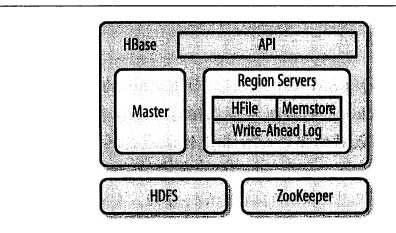
hbase中有3个主要的组件:客户端、一台主服务器、多台region服务器。主服务器主要利用zookeeper为region分配region服务器,zookeeper实际是一个具有可靠的、高可用、持久性的分布式协调系统。
下面是hbase的一个组织结构。
标签:范围 file 分配 排序 com 加载 文件 分布式 oop
原文地址:http://www.cnblogs.com/moss-yang/p/6833488.html