标签:语句 params 基本操作 跨表 关联 timestamp closed sql查询 eth
一、ORM操作
1、django orm创建数据库的方法
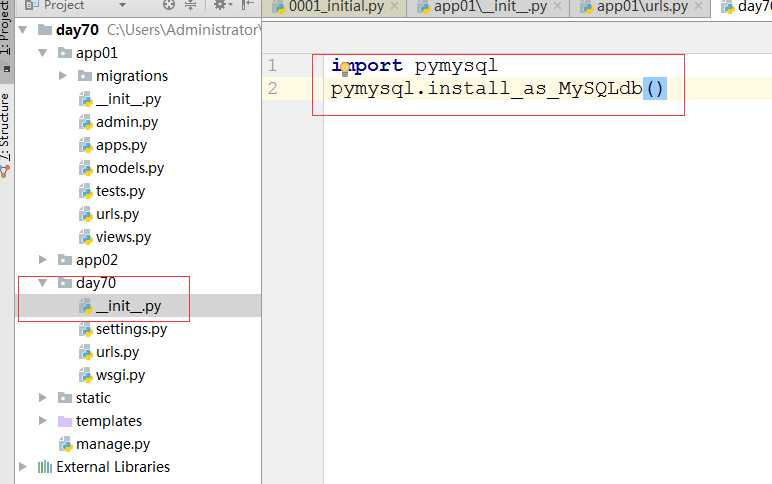
(1)指定连接pymysql(python3.x),先配置__init__.py
import pymysql
pymysql.install_as_MySQLdb()
(2)、配置连接mysql文件信息
settings.py
DATABASES = {
‘default‘: {
‘ENGINE‘: ‘django.db.backends.mysql‘,
‘NAME‘: ‘django_orm‘, #你的数据库名称
‘USER‘: ‘root‘, #你的数据库用户名
‘PASSWORD‘: ‘‘, #你的数据库密码
‘HOST‘: ‘‘, #你的数据库主机,留空默认为localhost
‘PORT‘: ‘3306‘, #你的数据库端口
}
}
(3)、在mysql数据库中,创建数据库。
mysql> create database Django_ORM character set utf8;
Query OK, 1 row affected (0.01 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| abc |
| crm |
| django_orm |
| mysql |
| performance_schema |
| s1 |
| sys |
| t2 |
+--------------------+
rows in set (0.00 sec)
mysql> use django_orm
Database changed
#####################################3
如果是连接linux系统上的mysql数据库,需要先授权,才能连接。
授权语句如下:
grant all privileges on *.* to ‘root‘@‘%‘ identified by ‘123456‘ with grant option;
flush privileges;
(4)、在app01下面的models.py里面写建表语句
from django.db import models
"""
增:
models.UserGroup.objects.create(title=‘销售部‘),创建列
删:
models.UserGroup.objects.filter(id=2).delete(),将id=2的那一行删除
改:
models.UserGroup.objects.filter(id=2).update(title=‘公关部‘),将ID=2的那一列的内容改成公关部
查:
group_list = models.UserGroup.objects.all(),查看用户组的所有信息
group_list = models.UserGroup.objects.filter(id=1),查看用户组id=1的所有信息
group_list = models.UserGroup.objects.filter(id__gt=1),查看用户组的id>1的所有信息
group_list = models.UserGroup.objects.filter(id__lt=1),查看用户组的id<1的所有信息
"""
class Userinfo(models.Model):
nid=models.BigAutoField(primary_key=True)
username=models.CharField(max_length=32)
password=models.CharField(max_length=64)
(5)、在终端执行命令
创建表
python manage.py makemigrations
写入数据库
from django.shortcuts import render,redirect,HttpResponse
from app01 import models
# ============关于数据库的相关操作==============
# 数据库的增、删、改、查
def ChangeSql(request):
# 新增:
# models.Userinfo.objects.create(username="hahaha",password="h123")
# 查询:
group_list=models.Userinfo.objects.all()
# group_list=models.Userinfo.objects.filter(nid=2)
# group_list=models.Userinfo.objects.filter(nid_gt=1)
# group_list=models.Userinfo.objects.filter(nid_lt=1)
# 改
# models.Userinfo.objects.filter(nid=3).update(username="lailailai",password="la123")
# 删除:
models.Userinfo.objects.filter(nid=3).delete()
print(group_list)
for i in group_list:
print(i.nid,i.username,i.password)
return render(request,"ChangeSql.html",{"group_list":group_list})
(2)进阶操作
# 获取个数
#
# models.Tb1.objects.filter(name=‘seven‘).count()
# 大于,小于
#
# models.Tb1.objects.filter(id__gt=1) # 获取id大于1的值
# models.Tb1.objects.filter(id__gte=1) # 获取id大于等于1的值
# models.Tb1.objects.filter(id__lt=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lte=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值
# in
#
# models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
# isnull
# Entry.objects.filter(pub_date__isnull=True)
# contains
#
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
# models.Tb1.objects.exclude(name__icontains="ven")
# range
#
# models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and
# 其他类似
#
# startswith,istartswith, endswith, iendswith,
# order by
#
# models.Tb1.objects.filter(name=‘seven‘).order_by(‘id‘) # asc
# models.Tb1.objects.filter(name=‘seven‘).order_by(‘-id‘) # desc
# group by
#
# from django.db.models import Count, Min, Max, Sum
# models.Tb1.objects.filter(c1=1).values(‘id‘).annotate(c=Count(‘num‘))
# SELECT "app01_tb1"."id", COUNT("app01_tb1"."num") AS "c" FROM "app01_tb1" WHERE "app01_tb1"."c1" = 1 GROUP BY "app01_tb1"."id"
# limit 、offset
#
# models.Tb1.objects.all()[10:20]
# regex正则匹配,iregex 不区分大小写
#
# Entry.objects.get(title__regex=r‘^(An?|The) +‘)
# Entry.objects.get(title__iregex=r‘^(an?|the) +‘)
# date
#
# Entry.objects.filter(pub_date__date=datetime.date(2005, 1, 1))
# Entry.objects.filter(pub_date__date__gt=datetime.date(2005, 1, 1))
# year
#
# Entry.objects.filter(pub_date__year=2005)
# Entry.objects.filter(pub_date__year__gte=2005)
# month
#
# Entry.objects.filter(pub_date__month=12)
# Entry.objects.filter(pub_date__month__gte=6)
# day
#
# Entry.objects.filter(pub_date__day=3)
# Entry.objects.filter(pub_date__day__gte=3)
# week_day
#
# Entry.objects.filter(pub_date__week_day=2)
# Entry.objects.filter(pub_date__week_day__gte=2)
# hour
#
# Event.objects.filter(timestamp__hour=23)
# Event.objects.filter(time__hour=5)
# Event.objects.filter(timestamp__hour__gte=12)
# minute
#
# Event.objects.filter(timestamp__minute=29)
# Event.objects.filter(time__minute=46)
# Event.objects.filter(timestamp__minute__gte=29)
# second
#
# Event.objects.filter(timestamp__second=31)
# Event.objects.filter(time__second=2)
# Event.objects.filter(timestamp__second__gte=31)
(3)、高级操作
# ============其他的关于moders的应用=========================
# 排序
# user_list=models.Userinfo.objects.all().order_by("id","username")#从小到大排序,当出现id一样的话,则按照名字排序
# user_list2=models.Userinfo.objects.all().order_by("-id")#从大到小排序
# print(user_list)
# print(user_list2)
# 分组
from django.db.models import Count,Sum,Min,Max
# res=models.Userinfo.objects.values("ut_id").annotate(a=Count("id"))
# print(res.query)#==>相当于SELECT `app01_userinfo`.`ut_id`, COUNT(`app01_userinfo`.`id`) AS `a` FROM `app01_userinfo` GROUP BY `app01_userinfo`.`ut_id`
# res=models.Userinfo.objects.values("ut_id").annotate(b=Count("id")).filter(id__lt=2)
# print(res)#==><QuerySet [{‘ut_id‘: 1, ‘b‘: 1}]>
# print(res.query)#=>SELECT `app01_userinfo`.`ut_id`, COUNT(`app01_userinfo`.`id`) AS `b` FROM `app01_userinfo` WHERE `app01_userinfo`.`id` < 2 GROUP BY `app01_userinfo`.`ut_id` ORDER BY NULL
# 过滤
# res =models.Userinfo.objects.filter(id__lt=5)#小于
# res =models.Userinfo.objects.filter(id__gt=5)#大于
# res =models.Userinfo.objects.filter(id__lte=5)#小于等于
# res =models.Userinfo.objects.filter(id__gte=5)#大于等于
# res =models.Userinfo.objects.filter(id__in=[1,2,3])#id在列表中
# res =models.Userinfo.objects.filter(id__range=[1,3])#id的范围属于1-3(包含1和3)
# res=models.Userinfo.objects.filter(username__startswith="ha")
# res=models.Userinfo.objects.filter(username__endswith="ha")
# res=models.Userinfo.objects.filter(username__contains="xu")#包含
# res=models.Userinfo.objects.exclude(id=1)#排除id=1的
# print(res)
# ======关于F、Q、extra
# F:
from django.db.models import F
#将数据库中的年级那一列都自加一
# models.Userinfo.objects.all().update(age=F("age")+1)
# Q:
# res=models.Userinfo.objects.filter(id=1,username="xuyuanyuan")#里面是and的关系
# print(res)#==><QuerySet []>
# dict={
# "id":1,
# "username":"xuyuanyuan"
# }#里面是and的关系
# ret=models.Userinfo.objects.filter(**dict)
# print(ret)#===><QuerySet []>
from django.db.models import Q
# Q使用有两种方式:对象方式,方法方式 *
# res=models.Userinfo.objects.filter(Q(id__lt=5))
# res=models.Userinfo.objects.filter(Q(id__lt=5)|Q(id__gt=315))#或
# res=models.Userinfo.objects.filter(Q(id__lt=5)&Q(id__gt=310))
# print(res)
# q1=Q()
# q1.connector="OR"
# q1.children.append(("id__gte",1))
# q1.children.append(("id",3))
# q1.children.append(("id",4))
#
# q2 = Q()
# q2.connector = ‘OR‘
# q2.children.append((‘id‘, 11))
# q2.children.append((‘id‘, 1))
# q2.children.append((‘id‘, 10))
#
# q3 = Q()
# q3.connector = ‘AND‘
# q3.children.append((‘id‘, 111))
# q3.children.append((‘id‘, 200))
# q2.add(q3,‘OR‘)
#
# con = Q()
# con.add(q1, ‘AND‘)
# con.add(q2, ‘AND‘)
# res=models.Userinfo.objects.filter(con)
# print(res)#===><QuerySet [<Userinfo: 1-hahaha-19>]>
# print(res.query)#==>上面定义的就相当于下面的sql语句:
# SELECT `app01_userinfo`.`id`,
# `app01_userinfo`.`username`,
# `app01_userinfo`.`age`,
# `app01_userinfo`.`ut_id`
# FROM `app01_userinfo`
# WHERE ((`app01_userinfo`.`id` >= 1 OR `app01_userinfo`.`id` = 3 OR `app01_userinfo`.`id` = 4)
# AND (`app01_userinfo`.`id` = 11 OR `app01_userinfo`.`id` = 1 OR `app01_userinfo`.`id` = 10
# OR (`app01_userinfo`.`id` = 111 AND `app01_userinfo`.`id` = 200)))
# condition_dict = {
# ‘k1‘:[1,2,3,4],
# ‘k2‘:[1,2,10,11],
# "k3":[1,2,100,111,200],
# }
# con = Q()
# for k,v in condition_dict.items():
# q = Q()
# q.connector = ‘OR‘
# for i in v:
# q.children.append((‘id‘, i))
# con.add(q,‘AND‘)
# res=models.Userinfo.objects.filter(con)
# print(res)
# print(res.query)
# extra:额外的
#
# extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# Entry.objects.extra(select={‘new_id‘: "select col from sometable where othercol > %s"}, select_params=(1,))
# Entry.objects.extra(where=[‘headline=%s‘], params=[‘Lennon‘])
# Entry.objects.extra(where=["foo=‘a‘ OR bar = ‘a‘", "baz = ‘a‘"])
# Entry.objects.extra(select={‘new_id‘: "select id from tb where id > %s"}, select_params=(1,), order_by=[‘-nid‘])
#原生sql
# name_map = {‘title‘: ‘titles‘}
# v1 = models.Userinfo.objects.raw(‘SELECT id,title FROM app01_usertype‘,translations=name_map)
# print(v1.query)
# print(v1)
# for i in v1:
# print(i,type(i))
其它
(4)、其他操作

from django.shortcuts import render,redirect,HttpResponse
from app01 import models
def all(self)
# 获取所有的数据对象
def filter(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q
def exclude(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q
def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。
model.tb.objects.all().select_related()
model.tb.objects.all().select_related(‘外键字段‘)
model.tb.objects.all().select_related(‘外键字段__外键字段‘)
def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。
# 获取所有用户表
# 获取用户类型表where id in (用户表中的查到的所有用户ID)
models.UserInfo.objects.prefetch_related(‘外键字段‘)
from django.db.models import Count, Case, When, IntegerField
Article.objects.annotate(
numviews=Count(Case(
When(readership__what_time__lt=treshold, then=1),
output_field=CharField(),
))
)
students = Student.objects.all().annotate(num_excused_absences=models.Sum(
models.Case(
models.When(absence__type=‘Excused‘, then=1),
default=0,
output_field=models.IntegerField()
)))
def annotate(self, *args, **kwargs)
# 用于实现聚合group by查询
from django.db.models import Count, Avg, Max, Min, Sum
v = models.UserInfo.objects.values(‘u_id‘).annotate(uid=Count(‘u_id‘))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id
v = models.UserInfo.objects.values(‘u_id‘).annotate(uid=Count(‘u_id‘)).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
v = models.UserInfo.objects.values(‘u_id‘).annotate(uid=Count(‘u_id‘,distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
def distinct(self, *field_names)
# 用于distinct去重
models.UserInfo.objects.values(‘nid‘).distinct()
# select distinct nid from userinfo
注:只有在PostgreSQL中才能使用distinct进行去重
def order_by(self, *field_names)
# 用于排序
models.UserInfo.objects.all().order_by(‘-id‘,‘age‘)
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 构造额外的查询条件或者映射,如:子查询
Entry.objects.extra(select={‘new_id‘: "select col from sometable where othercol > %s"}, select_params=(1,))
Entry.objects.extra(where=[‘headline=%s‘], params=[‘Lennon‘])
Entry.objects.extra(where=["foo=‘a‘ OR bar = ‘a‘", "baz = ‘a‘"])
Entry.objects.extra(select={‘new_id‘: "select id from tb where id > %s"}, select_params=(1,), order_by=[‘-nid‘])
def reverse(self):
# 倒序
models.UserInfo.objects.all().order_by(‘-nid‘).reverse()
# 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序
def defer(self, *fields):
models.UserInfo.objects.defer(‘username‘,‘id‘)
或
models.UserInfo.objects.filter(...).defer(‘username‘,‘id‘)
#映射中排除某列数据
def only(self, *fields):
#仅取某个表中的数据
models.UserInfo.objects.only(‘username‘,‘id‘)
或
models.UserInfo.objects.filter(...).only(‘username‘,‘id‘)
def using(self, alias):
指定使用的数据库,参数为别名(setting中的设置)
##################################################
# PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
##################################################
def raw(self, raw_query, params=None, translations=None, using=None):
# 执行原生SQL
models.UserInfo.objects.raw(‘select * from userinfo‘)
# 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw(‘select id as nid from 其他表‘)
# 为原生SQL设置参数
models.UserInfo.objects.raw(‘select id as nid from userinfo where nid>%s‘, params=[12,])
# 将获取的到列名转换为指定列名
name_map = {‘first‘: ‘first_name‘, ‘last‘: ‘last_name‘, ‘bd‘: ‘birth_date‘, ‘pk‘: ‘id‘}
Person.objects.raw(‘SELECT * FROM some_other_table‘, translations=name_map)
# 指定数据库
models.UserInfo.objects.raw(‘select * from userinfo‘, using="default")
################### 原生SQL ###################
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections[‘default‘].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
def values(self, *fields):
# 获取每行数据为字典格式
def values_list(self, *fields, **kwargs):
# 获取每行数据为元祖
def dates(self, field_name, kind, order=‘ASC‘):
# 根据时间进行某一部分进行去重查找并截取指定内容
# kind只能是:"year"(年), "month"(年-月), "day"(年-月-日)
# order只能是:"ASC" "DESC"
# 并获取转换后的时间
- year : 年-01-01
- month: 年-月-01
- day : 年-月-日
models.DatePlus.objects.dates(‘ctime‘,‘day‘,‘DESC‘)
def datetimes(self, field_name, kind, order=‘ASC‘, tzinfo=None):
# 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间
# kind只能是 "year", "month", "day", "hour", "minute", "second"
# order只能是:"ASC" "DESC"
# tzinfo时区对象
models.DDD.objects.datetimes(‘ctime‘,‘hour‘,tzinfo=pytz.UTC)
models.DDD.objects.datetimes(‘ctime‘,‘hour‘,tzinfo=pytz.timezone(‘Asia/Shanghai‘))
"""
pip3 install pytz
import pytz
pytz.all_timezones
pytz.timezone(‘Asia/Shanghai’)
"""
def none(self):
# 空QuerySet对象
####################################
# METHODS THAT DO DATABASE QUERIES #
####################################
def aggregate(self, *args, **kwargs):
# 聚合函数,获取字典类型聚合结果
from django.db.models import Count, Avg, Max, Min, Sum
result = models.UserInfo.objects.aggregate(k=Count(‘u_id‘, distinct=True), n=Count(‘nid‘))
===> {‘k‘: 3, ‘n‘: 4}
def count(self):
# 获取个数
def get(self, *args, **kwargs):
# 获取单个对象
def create(self, **kwargs):
# 创建对象
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的个数
objs = [
models.DDD(name=‘r11‘),
models.DDD(name=‘r22‘)
]
models.DDD.objects.bulk_create(objs, 10)
def get_or_create(self, defaults=None, **kwargs):
# 如果存在,则获取,否则,创建
# defaults 指定创建时,其他字段的值
obj, created = models.UserInfo.objects.get_or_create(username=‘root1‘, defaults={‘email‘: ‘1111111‘,‘u_id‘: 2, ‘t_id‘: 2})
def update_or_create(self, defaults=None, **kwargs):
# 如果存在,则更新,否则,创建
# defaults 指定创建时或更新时的其他字段
obj, created = models.UserInfo.objects.update_or_create(username=‘root1‘, defaults={‘email‘: ‘1111111‘,‘u_id‘: 2, ‘t_id‘: 1})
def first(self):
# 获取第一个
def last(self):
# 获取最后一个
def in_bulk(self, id_list=None):
# 根据主键ID进行查找
id_list = [11,21,31]
models.DDD.objects.in_bulk(id_list)
def delete(self):
# 删除
def update(self, **kwargs):
# 更新
def exists(self):
# 是否有结果
重点:连表操作(正反)
(5)、一对一和一对多正反操作
a、正向和反向操作
.all()=====》查看到的数据类型都是Queryset类型,类似于列表,里面都是一个个对象
.values()===》使用.values查看数据,所查看的数据是Queryset里面套的字典,
.values_list()===》使用.values_list的方法查看的话,所查看的数据是列表里面套字典的方式
示例:
model.py
from django.db import models
from django.views import View
"""
增:
models.UserGroup.objects.create(title=‘销售部‘),创建列
删:
models.UserGroup.objects.filter(id=2).delete(),将id=2的那一行删除
改:
models.UserGroup.objects.filter(id=2).update(title=‘公关部‘),将ID=2的那一列的内容改成公关部
查:
group_list = models.UserGroup.objects.all(),查看用户组的所有信息
group_list = models.UserGroup.objects.filter(id=1),查看用户组id=1的所有信息
group_list = models.UserGroup.objects.filter(id__gt=1),查看用户组的id>1的所有信息
group_list = models.UserGroup.objects.filter(id__lt=1),查看用户组的id<1的所有信息
"""
class UserType(models.Model):
# 用户类型
title=models.CharField(max_length=32)
class Userinfo(models.Model):
# 用户表
# nid=models.BigAutoField(primary_key=True)
username=models.CharField(max_length=32)
age=models.IntegerField()
ut=models.ForeignKey("UserType")
def __str__(self):
return "%s-%s" %(self.id,self.username)
views.py
from django.shortcuts import render,HttpResponse
from django.views import View
from app01 import models
# 关于查看和获取数据(正向操作和反向操作)
# 1.models.Userinfo.objects.all()查看到的数据类型都是Queryset类型,类似于列表,里面都是一个个对象
# Queryset[obj,obj,obj,]
# res=models.Userinfo.objects.all()
# # print(res)
# for obj in res:
# print(obj.username,obj.age,obj.ut_id,obj.ut.title)
#(1)一个用户对应一个用户类型
# UserInfo,ut是外键字段,可以通过点的方式连表 - 正向操作
# PS: 一个用户只有一个用户类型
# Queryset[obj,obj,obj,]
# res=models.Userinfo.objects.all().first()
# print(res.username, res.age, res.ut_id, res.ut.title)
#(2)一个用户类型可以对应多个用户(将同一类型下的用户全部取出)
# UserType, 表名小写_set.all() - 反向操作
# PS: 一个用户类型下可以有很多用户
# obj = models.UserType.objects.all().first()
# print(obj) #=====>UserType object
# print(obj.userinfo_set.all())#====><QuerySet [<Userinfo: Userinfo object>, <Userinfo: Userinfo object>]>
# print(‘用户类型‘,obj.id,obj.title)#===>用户类型 1 普通用户
# for row in obj.userinfo_set.all():
# print(row.username,row.age)
# result = models.UserType.objects.all()
# for item in result:
# print(item.title,item.userinfo_set.filter(username=‘hahaha‘))
# 2.使用.values查看数据,所查看的数据是Queryset里面套的字典,
# 无法向上面的1一样进行obj.取值
# result=models.Userinfo.objects.all().values()
# print(result)#===>
# """
# < QuerySet[{‘id‘: 1, ‘username‘: ‘hahaha‘, ‘age‘: 18, ‘ut_id‘: 1},
# {‘id‘: 2, ‘username‘: ‘xuyuanyuan‘, ‘age‘: 18,‘ut_id‘: 3} ‘ut_id‘: 1}] >
# """
# for i in result:
# print(i)#===>{‘id‘: 1, ‘username‘: ‘hahaha‘, ‘age‘: 18, ‘ut_id‘: 1}
# 3.使用.values_list的方法查看的话,所查看的数据是列表里面套字典的方式
# result=models.Userinfo.objects.all().values_list("username","age")
# print(result)
# """
# < QuerySet[(‘hahaha‘, 18),
# (‘xuyuanyuan‘, 18),
# (‘leileilei‘, 10),
# (‘kkkkk‘, 18),
# (‘bob‘, 18),
# (‘rose‘, 18),
# (‘jack‘, 18),
# (‘nack‘, 18)] >
# """
# for i in result:
# print(i)
#return HttpResponse("hello")
b、多对多连表(正向和反向操作)
.all()=====》查看到的数据类型都是Queryset类型,类似于列表,里面都是一个个对象
.values()===》使用.values查看数据,所查看的数据是Queryset里面套的字典,
.values_list()===》使用.values_list的方法查看的话,所查看的数据是列表里面套字典的方式
from django.shortcuts import render,HttpResponse
from django.views import View
from app01 import models
from django.core.paginator import
def test(request):
# 当数据获取多个数据时,分别用上述1.2.3来实现正反向连表操作:
# 1.
# (1)正向操作=====>根据userinfo来查询操作
# [obj,obj,obj]正向操作:
# models.Userinfo.objects.all()
# models.Userinfo.objects.filter(ut_id__gt=2)
# res=models.Userinfo.objects.filter(ut_id__gt=2)
# for i in res:
# print(i.username,i.age,i.ut.title)
#(2)一个用户类型可以对应多个用户(将同一类型下的用户全部取出)
# UserType, 表名小写_set.all() - 反向操作
# PS: 一个用户类型下可以有很多用户
# obj = models.UserType.objects.all().first()
# print(obj) #=====>UserType object
# print(obj.userinfo_set.all())#====><QuerySet [<Userinfo: Userinfo object>, <Userinfo: Userinfo object>]>
# print(‘用户类型‘,obj.id,obj.title)#===>用户类型 1 普通用户
# for row in obj.userinfo_set.all():
# print(row.username,row.age)
# result = models.UserType.objects.all()
# for item in result:
# print(item.title,item.userinfo_set.filter(username=‘hahaha‘))
# 2.[{"id":1,"username":"xuyuanyuan"}]
# (1)正向操作:====>根据userinfo来操作
# models.Userinfo.objects.all().values("username","age")
# models.Userinfo.objects.filter(id__gt=2).values("username","age")
# res=models.Userinfo.objects.filter(id__gt=7).values("username","age")
# # 根据字典的key取值,无法连表,无法跨表去取usertype的title值
# for i in res:
# print(i["username"],i["age"]) #===>nack 18
#解决办法: 但是如果一开始取值的时候连表的话,则for循环可以取得连表后的值
# res=models.Userinfo.objects.all().values("username", "age","ut__title")
# for i in res:
# print(i["username"],i["age"],i["ut__title"])
# (2)反向操作====>根据usertype来操作:
# models.UserType.objects.all().values("id","title")
# models.UserType.objects.filter(id__1t=4).values("id","title")
# res=models.UserType.objects.filter(id__1t=4).values("id","title")
# 根据字典的key取值,无法连表,无法跨表去取userinfo的值
# 解决办法: 但是如果一开始取值的时候连表的话,则for循环可以取得连表后的值
# res1=models.UserType.objects.filter(id=1).values("id","title","userinfo")
# res2=models.UserType.objects.filter(id=1).values("id","title","userinfo__username")
# res3=models.UserType.objects.filter(id=1).values("id","title","userinfo__age")
# print(res1)
# print(res2)
# print(res3)
# 3.[("xuyuanyuan",18),("kkkk",18)]
# (1)正向操作:====>根据userinfo来操作
# models.Userinfo.objects.all().values_list()
# models.Userinfo.objects.filter(ut_id__gt=2).values_list()
# res=models.Userinfo.objects.filter(ut_id__gt=2).values_list()
# 根据元祖的索引取值,无法实现连表,无法获取usertype内的信息
# for i in res:
# print(i[0],i[1],i[2])
# 解决办法:一开始查询的时候就连表,则for循环即可取值
# models.Userinfo.objects.all().values_list("username","age","ut__title")
# res=models.Userinfo.objects.filter(ut_id__gt=3).values_list("username","age","ut__title")
# for i in res:
# print(i[0],i[2])#===>kkkkk 牛逼用户
# (2)反向操作====>根据usertype来操作:
# models.UserType.objects.all().values_list("id","title")
# 根据字典的key取值,无法连表,无法跨表去取userinfo的值
# 解决办法: 但是如果一开始取值的时候连表的话,则for循环可以取得连表后的值
# res1 = models.UserType.objects.filter(id=1).values_list("id", "title", "userinfo")
# res2 = models.UserType.objects.filter(id=1).values_list("id", "title", "userinfo__username")
# res3 = models.UserType.objects.filter(id=1).values_list("id", "title", "userinfo__age")
# print(res1)#===><QuerySet [(1, ‘普通用户‘, 1), (1, ‘普通用户‘, 8)]>
# print(res2)#===><QuerySet [(1, ‘普通用户‘, ‘hahaha‘), (1, ‘普通用户‘, ‘nack‘)]>
# print(res3)#===><QuerySet [(1, ‘普通用户‘, 18), (1, ‘普通用户‘, 18)]>
# return render(request,"test.html")
标签:语句 params 基本操作 跨表 关联 timestamp closed sql查询 eth
原文地址:http://www.cnblogs.com/xuyuanyuan123/p/7107502.html
