标签:class 系统 操作系统 inux 分享 开始 流式 sub orm
即时处理流式数据;
Spark Streaming 使用 离散化流(discretized stream) DStream作为抽象表示;
DStream是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为RDD存在,而DStream是由这些 RDD所组成的序列 (因此 得名“离散化”)。
DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。
创建出来的DStream支持两种操作,一种是转化操作(transformation),会生成一个新的DStream;另一种是输出操作(output operation),可以把数据写入外部系统中。
批处理程序不同,Spark Streaming 应用需要进行额外配置来保证 24/7 不间断工作。
流计算的实现从创建 StreamingContext 开始。StreamingContext 会在底层创建出 SparkContext,用来处理数据。
//用 Scala 进行流式筛选,打印出包含“error”的行 // 从SparkConf创建StreamingContext并指定1秒钟的批处理大小 val ssc = new StreamingContext(conf, Seconds(1)) // 连接到本地机器7777端口上后,使用收到的数据创建DStream val lines = ssc.socketTextStream("localhost", 7777) // 从DStream中筛选出包含字符串"error"的行 val errorLines = lines.filter(_.contains("error")) // 打印出有"error"的行 errorLines.print()
//用 Scala 进行流式筛选,打印出包含“error”的行 // 启动流计算环境StreamingContext并等待它"完成" ssc.start() // 等待作业完成 ssc.awaitTermination()
//在 Linux/Mac 操作系统上运行流计算应用并提供数据 $ spark-submit --class com.oreilly.learningsparkexamples.scala.StreamingLogInput $ASSEMBLY_JAR local[4] $ nc localhost 7777 # 使你可以键入输入的行来发送给服务器 <此处是你的输入>
Spark Streaming使用“微批次”的架构,把流式计算当作一系列 连续的小规模批处理 来对待。
Spark Streaming处理架构:
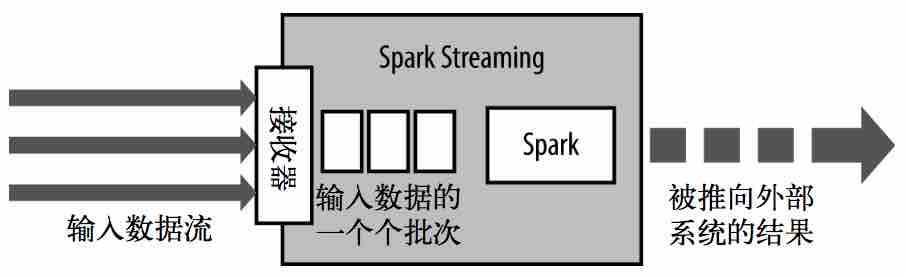
DStream:一个持续的RDD序列:

除了转化操作以外,DStream 还支持输出操作,输出操作在每个时间区间中周期性执行,每个批次都生成输出;比如在示例中使用的print()。
运作流程:
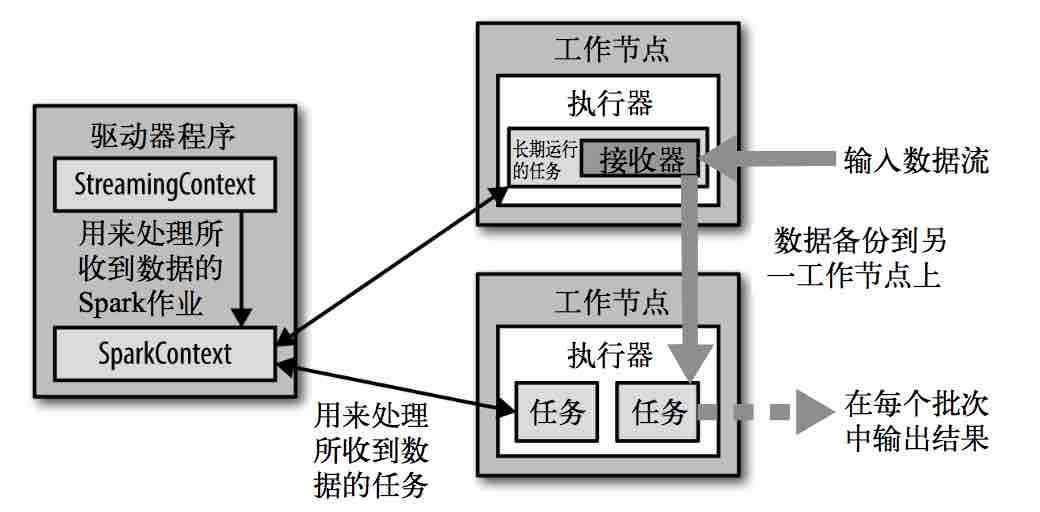
Spark Streaming 为每个输入源启动对应的 接收器,接收器以任务的形式运行在应用的执行器进程中;
从输入源收集数据并保存为RDD。它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默认行为)。数据保存在执行器进程的内存中,和缓存RDD的方式一样。
驱动器程序中的 StreamingContext 会周期性地运行Spark作业来处理这些数据,把数据与之前时间区间中的 RDD 进行整合。
检查点(check point):可以把运算过程中的状态阶段性地存储到可靠文件系统中(例如 HDFS 或者 S3)。一般来说,你需要每处理 5-10 个批次 的数据就保存一次。在恢复数据时,Spark Streaming 只需要回溯到上一个检查点即可。
后续待...
标签:class 系统 操作系统 inux 分享 开始 流式 sub orm
原文地址:http://www.cnblogs.com/mzzcy/p/7108738.html