标签:blog http os io 使用 strong ar for 文件
做前端的我们每天跟浏览器打交道,但是浏览器内部机制,工作原理我们真的了解吗?之前看到别人翻译过的一篇介绍浏览器工作原理的文章,感觉真心不错,原文太长,这里就整理一些基础而重要的内容分享给大家。
英文原文:How Browsers Work: Behind the Scenes of Modern Web Browsers;
翻译原文:http://kb.cnblogs.com/page/129756/#chapter1
一、介绍
浏览器可以被认为是使用最广泛的软件,本文将介绍浏览器的工作原理,我们将看到,从你在地址栏输入google.com到你看到google主页过程中都发生了什么。
今天,有五种主流浏览器——IE、Firefox、Safari、Chrome及Opera。
本文将基于一些开源浏览器的例子——Firefox、Chrome及Safari,Safari是部分开源的。
根据W3C(World Wide Web Consortium万维网联盟)的浏览器统计数据,当前(2011年5月),Firefox、Safari及Chrome的市场占有率综合已接近60%。(原文为2009年10月,数据没有太大变化)因此,可以说开源浏览器已经占据了浏览器市场的半壁江山。
浏览器的主要功能是将用户选择的web资源呈现出来,它需要从服务器请求资源,并将其显示在浏览器窗口中,资源的格式通常是HTML,也包括PDF、image及其他格式。用户用URI(Uniform Resource Identifier统一资源标识符)来指定所请求资源的位置,在网络一章有更多讨论。
HTML和CSS规范中规定了浏览器解释html文档的方式,由W3C组织对这些规范进行维护,W3C是负责制定web标准的组织。
HTML规范的最新版本是HTML4(http://www.w3.org/TR/html401/),HTML5还在制定中(译注:两年前),最新的CSS规范版本是2(http://www.w3.org/TR/CSS2),CSS3也还正在制定中(译注:同样两年前)。
这些年来,浏览器厂商纷纷开发自己的扩展,对规范的遵循并不完善,这为web开发者带来了严重的兼容性问题。
但是,浏览器的用户界面则差不多,常见的用户界面元素包括:
奇怪的是,并没有哪个正式公布的规范对用户界面做出规定,这些是多年来各浏览器厂商之间相互模仿和不断改进的结果。
HTML5并没有规定浏览器必须具有的UI元素,但列出了一些常用元素,包括地址栏、状态栏及工具栏。还有一些浏览器有自己专有的功能,比如Firefox的下载管理。更多相关内容将在后面讨论用户界面时介绍。
浏览器的主要组件包括:
1. 用户界面 - 包括地址栏、后退/前进按钮、书签目录等,也就是你所看到的除了用来显示你所请求页面的主窗口之外的其他部分。
2. 浏览器引擎 - 用来查询及操作渲染引擎的接口。
3. 渲染引擎 - 用来显示请求的内容,例如,如果请求内容为html,它负责解析html及css,并将解析后的结果显示出来。
4. 网络 - 用来完成网络调用,例如http请求,它具有平台无关的接口,可以在不同平台上工作。
5. UI后端 - 用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口。
6. JS解释器 - 用来解释执行JS代码。
7. 数据存储 - 属于持久层,浏览器需要在硬盘中保存类似cookie的各种数据,HTML5定义了web database技术,这是一种轻量级完整的客户端存储技术
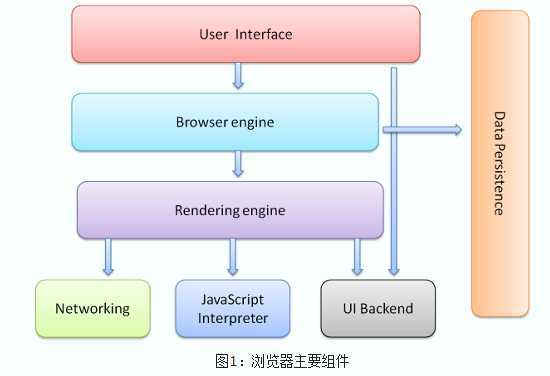
需要注意的是,不同于大部分浏览器,Chrome为每个Tab分配了各自的渲染引擎实例,每个Tab就是一个独立的进程。
渲染引擎的职责就是渲染,即在浏览器窗口中显示所请求的内容。
默认情况下,渲染引擎可以显示html、xml文档及图片,它也可以借助插件(一种浏览器扩展)显示其他类型数据,例如使用PDF阅读器插件,可以显示PDF格式,将由专门一章讲解插件及扩展,这里只讨论渲染引擎最主要的用途——显示应用了CSS之后的html及图片。
渲染引擎首先通过网络获得所请求文档的内容,通常以8K分块的方式完成。
下面是渲染引擎在取得内容之后的基本流程:
解析html以构建dom树 -> 构建render树 -> 布局render树 -> 绘制render树

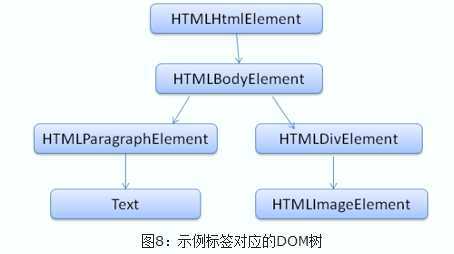
输出的树,也就是解析树,是由DOM元素及属性节点组成的。DOM是文档对象模型的缩写,它是html文档的对象表示,作为html元素的外部接口供js等调用。
树的根是“document”对象。
DOM和标签基本是一一对应的关系,例如,如下的标签:
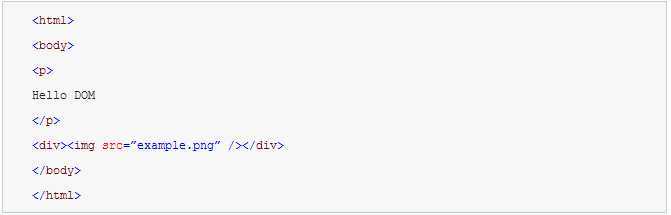
将会被转换为下面的DOM树:
正如前面章节中讨论的,hmtl不能被一般的自顶向下或自底向上的解析器所解析。
原因是:
1. 这门语言本身的宽容特性
2. 浏览器对一些常见的非法html有容错机制
3. 解析过程是往复的,通常源码不会在解析过程中发生改变,但在html中,脚本标签包含的“document.write”可能添加标签,这说明在解析过程中实际上修改了输入。
不能使用正则解析技术,浏览器为html定制了专属的解析器。
Html5规范中描述了这个解析算法,算法包括两个阶段——符号化及构建树。
符号化是词法分析的过程,将输入解析为符号,html的符号包括开始标签、结束标签、属性名及属性值。
符号识别器识别出符号后,将其传递给树构建器,并读取下一个字符,以识别下一个符号,这样直到处理完所有输入。
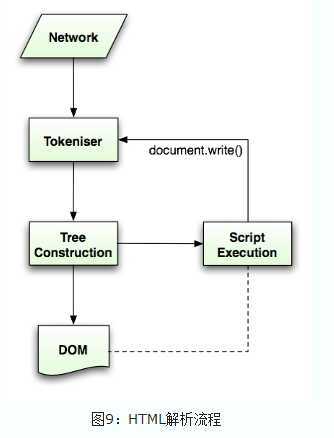
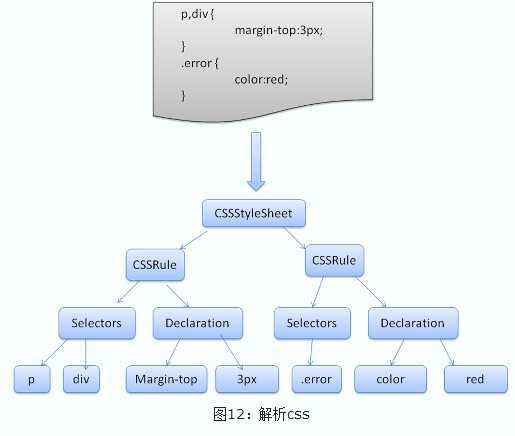
Webkit使用Flex和Bison解析生成器从CSS语法文件中自动生成解析器。回忆一下解析器的介绍,Bison创建一个自底向上的解析器,Firefox使用自顶向下解析器。它们都是将每个css文件解析为样式表对象,每个对象包含css规则,css规则对象包含选择器和声明对象,以及其他一些符合css语法的对象。
这里有三种策略:
1. normal -对象根据它在文档的中位置定位,这意味着它在渲染树和在Dom树中位置一致,并根据它的盒模型和大小进行布局。
2. float -对象先像普通流一样布局,然后尽可能的向左或是向右移动。
3. absolute -对象在渲染树中的位置和Dom树中位置无关。
static和relative是normal,absolute和fixed属于absolute。
在static定位中,不定义位置而使用默认的位置。其他策略中,作者指定位置——top、bottom、left、right。
Box布局的方式由这几项决定:box的类型、box的大小、定位策略及扩展信息(比如图片大小和屏幕尺寸)。
Block box:构成一个块,即在浏览器窗口上有自己的矩形

Inline box:并没有自己的块状区域,但包含在一个块状区域内
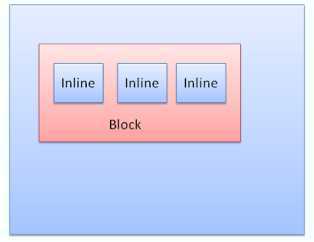
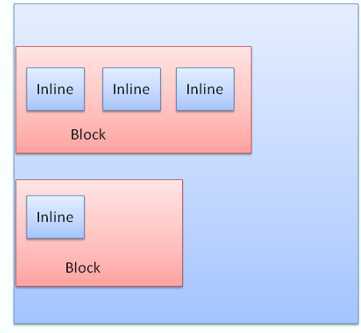
block一个挨着一个垂直格式化,inline则在水平方向上格式化。
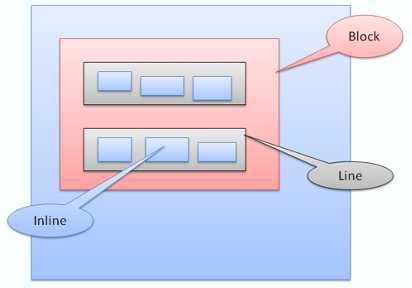
Inline盒模型放置在行内或是line box中,每行至少和最高的box一样高,当box以baseline对齐时——即一个元素的底部和另一个box上除底部以外的某点对齐,行高可以比最高的box高。当容器宽度不够时,行内元素将被放到多行中,这在一个p元素中经常发生。
标签:blog http os io 使用 strong ar for 文件
原文地址:http://www.cnblogs.com/veitch007/p/3948382.html