标签:ade 不能 自增列 name 针对 日期格式 设计 UI 电话
阅读目录
我们作为一个软件系统,肯定到处充满着各种单据,也必然需要有各种单据号与之对应。比如:电商行业的订单号、支付流水号、退款单号等等。SCM的采购单号、进货单号、出货单号、盘点单号等。在一个企业内部或者一个2C的平台,无法避免的需要通过某个单据号来进行沟通。所以一个好的单据号必然是便于沟通的,简单来说优先级就是 好记 > 好输入 > 好看,当然也是越短越好。
有的人可能会问,好像听的最多的就是唯一ID,包括大量的文章都是讲分布式唯一ID的生成的,好像和单据号相关的很少。但是其实我觉得这2者并没有冲突,只是重要性和针对场景不同。下面从不同的角度来分析一下:
1)唯一性:唯一是ID其实更多的是为了保证这个ID在整个系统中都是唯一的,它对唯一的定义范围更加广。而对单据号来说,它只要保证在所属的单据类型下唯一即可,比如订单号:00001和物流号:00001其实并不相互影响。
2)可读性:如果仅仅作为唯一ID来用,其实最简单粗暴的方式就是使用UUID,因为它仅仅给程序使用,人并不需要理解这个ID的意义。但是单据号则不同,上面也提到了,它需要有一定的可读性,便于人与人之间的沟通。想象一下你和其它人电话沟通时报一串UUID是什么体验。
3)业务性:单据号大部分情况下还需要承担一定的业务含义的体现,比如订单号T00001中的T = Trade、支付号P00001中的P = Pay等。甚至还有可能需要多笔单据号之间有一定的关联,比如一个订单号T00001下相关的支付号都必须是P00001-1,P00001-2这个样子。再甚至有些场景需要包含一些日期信息在其中。
和唯一ID一样,单据号的生成本身也是一个相对稳定并且通用的规则,所以把它提炼成一个单独的程序可以提供更好的复用性,避免了各自项目维护单据号所花费的重复劳动。特别在互联网行业中的大流量企业,还需要考虑性能和高可用问题。所以真的要把生成单据号这个“小功能”做好,还是需要一定的投入的。那么把它作为一个单独的程序能够把投入所产生的收益,也就是所谓的“ROI”放大,何乐而不为?
下面罗列一下常用的实现方式和各自的优缺点:
1)前缀列+全局自增列:
这个和唯一ID的方案类似,利用自增列的数字来做。且最简单的方式就是依赖数据库的自增列来做。
优点:
实现简单,不断的++
能够保证全局的唯一性
能够保证递增
可读性尚可
缺点:
需要依赖一个持久化的地方存储当前已经生成的“游标”位置,所以性能有上限,基本就是单应用的TPS上限或者所依赖DB的TPS上限
在一些对外的单据号上容易泄露一些商业信息。比如竞争对手可以通过单号猜出你每天的订单量甚至每个小时、每分钟的订单量。
破除单点的改进方案:
①水平拆分进行多写+同步长(例:机器1的自增数为1,4,7,...;机器2的自增数为2,5,8,...;机器3的自增数为3,6,9,...):
新的缺点:由于是多写,所以需要依赖于负载均衡策略和网络通讯的延时问题,无法保证生成的序号是100%递增的。(例:哪怕是round robin策略先请求1再请求2,但是还是有可能2先返回响应。)
②垂直拆分多写+自增列(机器1专门用于生成订单号、机器2专门用于生成支付单号):
新的缺点:
a.由于根据业务来分,所以流量不均导致某些大请求量的单据还是存在着单点瓶颈问题。
b.扩展性较差。每增加一个业务单据就需要增加一个程序
③水平拆分+增加机器码位(给每台生成单据号的程序编个号:1,2,3插入到自增列的前面):
新的缺点:
a.这个编码要么硬配置到配置文件中,或者依赖与某个分配编号的独立程序。并且号码长度变长了。
b.无法保证递增。
提高性能的改进方案:
①预生成到缓存,减少对DB的依赖
新的缺点:
a.如果需要彻底减少对DB的依赖,那么每次单据号被消耗是不应该回写DB的,也导致了一旦程序重启会存在比较大的序号空洞。
b.缓存的大小与DB获取下一段缓存数据的频率负相关的,当频率比较高的时候,需要做双缓存来预加载下一段缓存数据,避免缓存消耗完之后从DB拉取最新数据产生的阻塞。
2)前缀列+日期+自增列:
我想这个方案应该是大部分系统会采用的方案。这个日期的精度和自增数的数据长度是有关联的。日期精度越高,对于自增数的数据长度需求就越短,反之则越长。
优点:
实现比较容易
能够保证唯一性
能够保证递增
包含日期能体现更多的业务信息
缺点:
方案1的缺点都有
针对日期让自增列进行重置需要做一定的逻辑判断,复杂度提高(在多线程下有线程安全问题),性能降低。
破除单点的改进方案:
① 1)中的改进方案。
提高性能的改进方案:
① 1)中的改进方案。
② 对自增列的重置可以忽略日期变动(也就是哪怕到了下一个时间段,自增数也不重置,继续使用),而直接对整数进行++,直到自动进入下一循环。在C#中,你可以这样写:
var uint32 = (long)UInt32.MaxValue;
Interlocked.Add(ref uint32, 1);
Console.WriteLine((UInt32)uint32);
但是这里需要注意的是,这个自增列的数字上限必须能保证在日期的最小精度范围内不会产生重复。
新的缺点:
a.哪怕请求量不大,也会产生过长的单据号,因为自增数不会主动重置。
笔者个人觉得综合来看,
增加机器码位(给每台生成单据号的程序编个号:1,2,3插入到自增列的前面)
这个方案是相对最一劳永逸的。但是需要在数据长度和可读性上需要做出一定的权衡。首先为了保证递增,那么我们必然需要增加时间到整个单据号的前面。时间可以使用常规的日期格式也可以使用时间戳,当然相同精度来说,肯定是时间戳更短。考虑到实际的大部分场景中,单据号只要能够识别到是哪一种类型的单据,剩下的一般来说本身就是需要去对应的单据列表中找到该笔单据的详细信息查看。所以其实对日期的可读性并不是那么高。(举个例子:客户报出一个订单号出来给我们的客服人员,其实客服人员必然是需要去查看这笔订单的详细信息的。)
OK,那它的长度我们可以如此来设计:
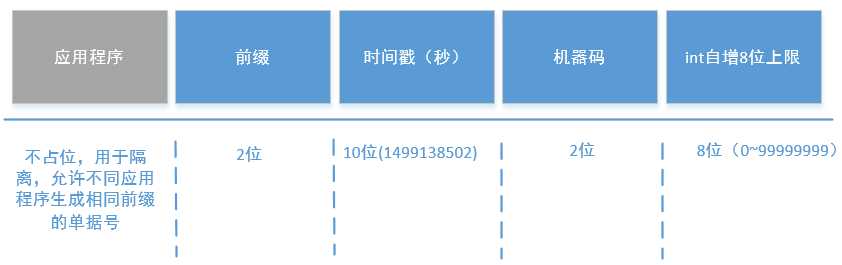
其中时间戳、自增数是全局共用的,所以对于单独某一类型的单据号并不是连续的,但是是趋势递增的,这解决了根据订单号猜到订单量之类的问题。
那么在这样的设计下可以支撑单据号不重复的上限是多少呢?其实就是单点在1秒内的最大量100000000 /1000 = 100000/ms,1毫秒10W个,以snowflake的生成速度4000/ms来算(网络来源,未经实际验证),再根据摩尔定律考虑CPU升级的影响,大约需要50年后才有可能产生重复。并且理论最大值是100台程序负载均衡,1000W/ms,估计这辈子不用考虑重复问题了。
有的人可能会问,为什么不直接时间戳取到毫秒位,会增加3位长度,后面自增数就可以短一点。首先按照比snowflake算法多冗余一个位数来看,哪怕取到时间戳到毫秒,后面还是需要5位(snowflake是4位:4000/ms),所以这个并没有什么区别。那么精度取到秒的好处是什么?我认为有2点:
1)解决了预加载问题,由于精度到秒,所以哪怕程序重启了,我的自增数从0开始累加也不会产生重复。
2)如果精度是毫秒,那么相当于不管我的每秒并发量是多少,哪怕1秒就1个请求进来,也固定占用3位长度。但是如果是秒,那么就省去了这3位,我想除了像阿里腾讯这种体量的公司,实际的环境中毫秒并发达到1W已经不得了了。
其中还有一些细节是:
1.机器码如果是个位数,那么前面加0填充,以免与后面的自增列结合后产生重复(例:机器1,序号11。和机器11,序号1会重复)。
2.每个程序所在服务器上的时钟同步需要做好,因为我们依赖于此保证递增问题。
最终,理论上实际生产环境生成的号码长度在15~19之间。
一个设计良好的单据号,不但可以用于主键,也可以用于做分库分表,比如我们把用户ID按照某个规则得出的几位数字拼到单据号的最后,那么直接用这个号来定位数据库,可以确保一个用户的订单全部落在一个同一个数据库里。
但是值得提醒的是,我们不能过于盲目的追求一步到位,需要结合自身的实际情况来选择合适的方式就好。前面列出的一些常见的方案在系统初期也是能很好的工作的。
作者:Zachary_Fan
出处:http://www.cnblogs.com/Zachary-Fan/p/Global_Unique_No.html
如果你想及时得到个人自写文章的消息推送,欢迎扫描下面的二维码~。

标签:ade 不能 自增列 name 针对 日期格式 设计 UI 电话
原文地址:http://www.cnblogs.com/Zachary-Fan/p/Global_Unique_No.html