标签:步骤 应用 基本 可读性 一个 如何 大小 介绍 随机
刘知远老师博士论文-基于文档主题结构的关键词抽取方法研究
一、研究背景和论文工作介绍
关键词抽取分为两步:选取候选关键词和从候选集合中推荐关键词。
1.1. 选取候选关键词
关键词:单个词或者多个单词组成的短语。
抽取难点:如何正确判定候选关键词的边界。(在英文关键词抽取中,一般选N元词串,计算N元词串内部联系的紧密程度来判断是否是一个有独立语义的短语。类比搭配抽取、多词表达抽取任务)
1.2. 推荐关键词
得到候选关键词集合后,两种途径解决关键词选取问题。
(1)无监督的方法
利用统计特性(egTF-IDF),排序,选取最高若干作为关键词。
(2)有监督的方法
将关键词抽取问题转换为判断每个候选关键词是否为关键词的二分类问题,它需要一个已经标注关键词的文档集合训练分类模型。(什么意思?具体怎么做?)
注:标注虽效果好,但耗时耗力,不能灵活面对时间变化下文档主题的变化,因此方法集中在无监督。
知识扩展(了解一些算法思想):
PageRank算法:对网页进行排序,基本思想,一个网页的重要性由链向它的其他网页重要性来决定,即如果越多重要的网页指向某网页,那么该网页也就相应越重要。
PageRank引出TextRank(基于图的关键词抽取算法),用在关键字抽取和文档摘要。基本思想,将文档看作一个词的网络,该网络中的链接表示词与词之间的语义关系。基于与PageRank相似的思想,TextRank认为一个词的重要性由链向它的其他词的重要性来决定,利用PageRank计算网络中词的重要性,然后根据候选关键词的PageRank值进行排序,从而选择排名最高的若干个词作为关键词。优点是考虑了文档中词与词之间的语义关系。
用于网页排序的HITS算法用于候选关键词排序,效果也相似。
主流方法:基于图的算法成为无监督关键词抽取的主流方法。关键词抽取以文档的词网作为基础。
应用扩展:社会标签自动标注(1.3节)分为两部分
(1)基于图的方法(涉及概念:协同标注、协同过滤、FolkRank算法、矩阵分解技术, 冷启动)
(2)基于内容的方法(涉及概念:K 近邻、隐含主题模型)
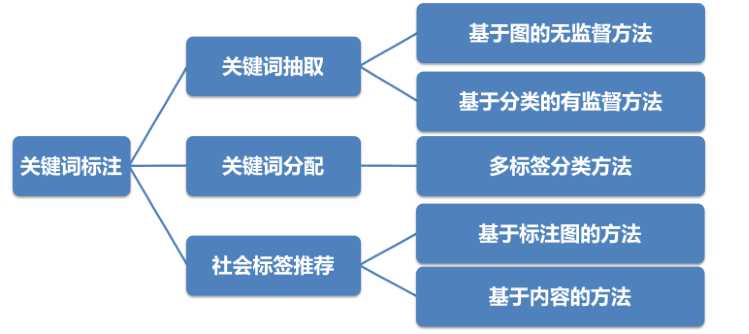
图 传统方法
总结:以上为传统方法,已有实现,但未系统考虑文档主题结构对关键词标注的作用。文档关键词同时有三个特点:可读性,相关性,覆盖度(考虑多主题问题)。论文主要解决关键词对文档主题覆盖度问题和文档与主题之间的词汇差异问题(什么是词汇差异?1.4.2节介绍)。
二、文档词汇聚类算法构建文档主题(利用文档内部信息、提高对文档主题的覆盖度)
主要步骤:
1. 去停用词,选取候选词2. 计算候选词之间的语义相似度
3. 根据语义相似度进行聚类
4. 选取每个聚类中心词,在文档中选取合适的关键词
对每个步骤详细介绍:
2.1. 去停用词,选取候选词
2.1.1 英语要进行断词,如果是汉语,先分词。(断词和分词的区分)
2.1.2 去停用词得到候选词。(一种候选关键词研究方法:先将单词作为候选词,聚类中心词,再将单个候选词扩展为多个词的短语)4,73
2.2. 计算候选词之间的语义相似度
2.2.1 基于文档内的词同现关系(度量词与词的相似度)
词与词的同现关系简单地表示为两个词在一个最多为w个词的滑动窗口内同现的次数。窗口大小w一般设为2到10之间的数值。在计算同现相似度时,利用每个文档中的每个词(不去停用词,无意义词用来提供距离信息),转换为词的序列。
2.2.2 利用外部知识库
利用维基百科来度量词与词之间的相似度,基本思想:将每个维基百科词条看作是一个独立的概念,一个词的语义信息可以用维基百科概念上的分布来表示,在某个概率上的权重可以用这个词的概率词条中的TF-IDF值来表示。比较两个词的概念向量来度量相似度。(很有效)
选用余弦相似度(COS)、欧式距离(EU-C)、点互信息(PMI)和规范化Google距离(NGD)来计算相似度。具体公式查看第12页
2.3 聚类方法(无监督,将对象划分为不同组,每个组内对象相互比较相似,组与组之间对象不同)
采用三种典型聚类算法:层次聚类、谱聚类、信任传播聚类。
未完待续
三、隐含主题模型构建文档主题(利用文档外部信息,不受限文档长短)
四、基于主题的随机游走模型(隐含主题模型和文档结构信息相结合)
五、机器翻译词对齐模型计算词到关键词的翻译概率(比较有效)
标签:步骤 应用 基本 可读性 一个 如何 大小 介绍 随机
原文地址:http://www.cnblogs.com/Joyce-song94/p/7119254.html