标签:des style blog http color io 使用 ar for
第一篇文章还有要修改的地方,现在我的集群已经扩展到5台(虚拟机)有些配置还要改,这一篇记录一下Hadoop HA 和zookeeper的配置,方便自己以后看。
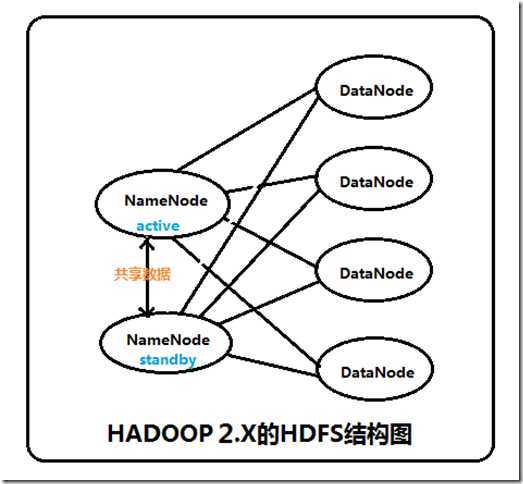
新的HDFS中的NameNode不再是只有一个了,可以有多个(目前只支持2个)。每一个都有相同的职能。
在HDFS(HA) 集群中,Standby 节点还执行着对namespace 状态的checkpoint 功能,因此没有必要再运行SecondaryNameNode。
这两个NameNode的地位如何:一个是active状态的,一个是standby状态的。当 集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode是处于待命状态的,时刻同步active状态 NameNode的数据。一旦active状态的NameNode不能工作,通过手工或者自动切换,standby状态的NameNode就可以转变为 active状态的,就可以继续工作了。这就是高可靠。
当NameNode发生故障时,他们的数据如何保持一致:在这里,2个NameNode的数据其实是实时共享的。新HDFS采用了一种共享机制,JournalNode集群或者NFS进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这里使用JournalNode集群进行数据共享。
如何实现NameNode的自动切换:这就需要使用ZooKeeper集群进行选择了。HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。
先介绍一下环境:
| ip地址 | 主机名 | NameNode | JournalNode | DataNode |
| 192.168.1.109 | hadoop1 | 是 | 是 | |
| 192.168.1.110 | hadoop2 | 是 | 是 | |
| 192.168.1.111 | hadoop3 | 是 | 是 | |
| 192.168.1.112 | hadoop4 | 是 | 是 | |
| 192.168.1.113 | hadoop5 | 是 | 是 |
1.下载解压,我放在了/usr/local/zookeeper下
2.修改配置项,进入zookeeper的conf目录,拷贝命名zoo_sample.cfg 为zoo.cfg,然后修改其内容如下:
1 tickTime=2000 2 initLimit=10 3 syncLimit=5 4 dataDir=/hadoop/zookeeper/zkdata 5 dataLogDir=/hadoop/zookeeper/zkdatalog 6 clientPort=2181 7 server.1=hadoop1:2888:3888 8 server.2=hadoop2:2888:3888 9 server.3=hadoop3:2888:3888 10 server.4=hadoop4:2888:3888 11 server.5=hadoop5:2888:3888
3.创建zkdata和zkdatalog两个文件夹和一个myid文件:
创建/hadoop/zookeeper/zkdata 和 /hadoop/zookeeper/zkdatalog 如有不存在目录则创建。还有一个myid文件其内容为1 意思是zoo.cfg文本中的server.1中 的1。
4.添加环境变量server.namenode.ha.ConfiguredFailoverProxyProviderserver.namenode.ha.ConfiguredFailoverProxyProvider
export ZOOKEEPER_HOME=/usr/local/zookeeper
PATH=$ZOOKEEPER_HOME/bin:$PATH
source /etc/profile
5.这样子zookeeper就配置好了,scp拷贝到其他节点。
然后就到了HA部分了
1.修改core-site.xml
server.namenode.ha.ConfiguredFailoverProxyProvider
1 <configuration> 2 <property> 3 <name>fs.defaultFS</name> 4 <value>hdfs://mycluster</value> 5 </property> 6 7 <property> 8 <name>hadoop.tmp.dir</name> 9 <value>/hadoop/tmp</value> 10 </property> 11 12 <property> 13 <name>ha.zookeeper.quorum</name> 14 <value>hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181,hadoop5:2181</value> 15 </property> 16 17 </configuration>
2.修改hdfs-site.xml
1 <configuration> 2 <property> 3 <name>dfs.nameservices</name> 4 <value>mycluster</value> 5 </property> 6 7 <property> 8 <name>dfs.ha.namenodes.mycluster</name> 9 <value>hadoop1,hadoop2</value> 10 </property> 11 12 <property> 13 <name>dfs.namenode.secondary.http-address</name> 14 <value>hadoop2:9001</value> 15 </property> 16 17 <property> 18 <name>dfs.namenode.rpc-address.mycluster.hadoop1</name> 19 <value>hadoop1:8020</value> 20 </property> 21 22 <property> 23 <name>dfs.namenode.rpc-address.mycluster.hadoop2</name> 24 <value>hadoop2:8020</value> 25 </property> 26 27 <property> 28 <name>dfs.namenode.http-address.mycluster.hadoop1</name> 29 <value>hadoop1:50070</value> 30 </property> 31 32 <property> 33 <name>dfs.namenode.http-address.mycluster.hadoop2</name> 34 <value>hadoop2:50070</value> 35 </property> 36 37 <property> 38 <name>dfs.namenode.shared.edits.dir</name> 39 <value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485;hadoop4:8485;hadoop5:8485/mycluster</value> 40 </property> 41 42 <property> 43 <name>dfs.client.failover.proxy.provider.mycluster</name> 44 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 45 </property> 46 47 <property> 48 <name>dfs.journalnode.edits.dir</name> 49 <value>/hadoop/journal</value> 50 </property> 51 52 <property> 53 <name>dfs.ha.fencing.methods</name> 54 <value>sshfence</value> 55 </property> 56 57 <property> 58 <name>dfs.ha.fencing.ssh.private-key-files</name> 59 <value>/root/.ssh/id_rsa</value> 60 </property> 61 62 <property> 63 <name>dfs.ha.fencing.ssh.connect-timeout</name> 64 <value>10000</value> 65 </property> 66 67 <property> 68 <name>dfs.namenode.handler.count</name> 69 <value>100</value> 70 </property> 71 72 <property> 73 <name>dfs.namenode.name.dir</name> 74 <value>/hadoop/hdfs/name</value> 75 </property> 76 77 <property> 78 <name>dfs.datanode.data.dir</name> 79 <value>/hadoop/hdfs/data</value> 80 </property> 81 82 <property> 83 <name>dfs.replication</name> 84 <value>2</value> 85 </property> 86 87 </configuration>
3.修改slaves
hadoop3
hadoop4
hadoop5
4.修改masters 没有则创建
hadoop2
现在所有配置就算全部完成了,如果从第一步中配置过来现在的就没有问题,来跑一跑吧。
顺序不能乱。
1.在每台机器上启动zookeeper,zkServer.sh start
2.检查是否启动成功 echo ruok | nc hadoop1 2181
echo ruok | nc hadoop2 2181
echo ruok | nc hadoop3 2181
echo ruok | nc hadoop4 2181
echo ruok | nc hadoop5 2181
若返回的imok则zookeeper是正常的。
或者直接使用jps查看进程若有QuorumPeerMain的进程则启动正常。
3.启动JournalNode集群
分别在hadoop1,2,3,4,5上面执行命令 hadoop-daemon.sh start journalnode
4.在hadoop1上格式化NameNode
hadoop namenode -format
5.启动这个NameNode
hadoop-daemon.sh start namenode
6.在Hadoo2上格式化NameNode
hdfs namenode -bootstrapStandby
7.启动hadoop2的NameNode
hadoop-daemon.sh start namenode
8.通过 http://hadoop1:50070,http://hadoop2:50070 查看这两个NameNode 现在都是standby状态
9.切换hadoop1到active状态 hdfs haadmin -transitionToActive hadoop1
10.启动DataNodes hadoop-daemons.sh start datanode
hadoop 2.2 第二步 HA zookeeper 配置
标签:des style blog http color io 使用 ar for
原文地址:http://www.cnblogs.com/zqbBlog/p/3948484.html