标签:standard 授权 标准 -o original 问题 作者 sub 正态分布
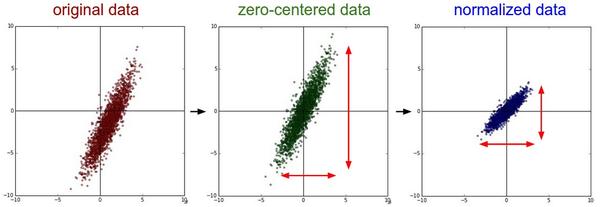
机器学习:样本去中心化目的
原文地址:http://www.cnblogs.com/jackherrick/p/7126914.html