标签:finish 开头 复位 资源 设置 时间差 lob 失败 关注
小梅哥编写,未经许可严禁用于任何商业用途
近期,一直在调试使用Verilog编写的以太网发送摄像头数据到电脑的工程(以下简称以太网图传)。该工程基于今年设计的一款FPGA教学板AC620。AC620上有一个百兆以太网接口和一个通用CMOS摄像头接口,因此非常适合实现以太网图传功能。CMOS摄像头接口没有什么好说的,就是IO而已,这里先重点介绍下以太网接口。
以太网接口使用了一片10/100M自适应以太网收发器(PHY),型号为RTL8201。该芯片和FPGA采用标准的MII接口进行连接。什么是MII接口呢?这里暂不做任何介绍,因为今天要介绍的主角不是他。关于MII接口等以太网知识,可以关注小梅哥的FPGA以太网系列连载博客。简单点说,对于以太网发送数据来说,有一个发送时钟、一个发送使能信号和4位并行的数据发送信号,对于以太网接收数据,有一个接收时钟、一个接收数据有效信号和4位并行的数据接收信号。在发送时,发送使能信号有效,则每个字节的数据被拆分成2个4位的数据然后通过4位的数据信号,通过两个周期的时钟信号,依次传递到以太网PHY芯片,再由PHY进行并串转换,串行编码等工作后,将数据通过网络变压器加载到传输媒介(网线)上。在这里,以太网发送时钟是由以太网PHY芯片产生,然后送给FPGA使用的。该时钟信号一般叫做mii_tx_clk,当以太网速率为100Mbps时,该时钟信号为25MHz。而在FPGA侧,为了保证数据和控制信号的传输能够高度的同步于该以太网发送时钟信号,因此往往直接使用该以太网发送时钟信号作为相关时序逻辑的时钟信号。也因为这个要求,问题随之产生——该以太网时钟信号作为众多时序逻辑的时钟信号,其时钟质量和到达各个寄存器的时间最好也没有大的偏差,这样才能够保证时序收敛,从而使得设计的逻辑运行稳定。
在AC620 FPGA开发板上,该以太网发送时钟信号连接在了EP4CE10F17型FPGA的D11引脚上。而D11只是一个普通的FPGA输入输出管脚,非时钟输入管脚。因此从该引脚接入的信号如果不经过任何处理,将无法像专用时钟输入管脚上输入的信号一样被连接到全局时钟资源上。那么该时钟信号在FPGA片上进行走线时,只能使用片上的长线和短线布线资源,有时候甚至要通过LUT连接,才能到达各个寄存器。那么这里,问题就出现了,个人感觉的主要问题最起码有2点(不足的欢迎大家补充):
1、由于该时钟信号是通过各种长短布线资源,甚至经过LUT连接才能到达其驱动的各个寄存器,因此该时钟信号从进入FPGA管脚,到传递到各个寄存器的时钟输入端,其时间是很难保持相同的,距离的远近直接决定了该时钟信号的传输延迟。而这个传输延迟的差值,可能达到几纳秒甚至十几纳秒。这个差值,将直接影响数据的建立和保持时间,造成时序无法收敛,从而导致设计失败。我们可以通过下图更加直观的分析这个问题。
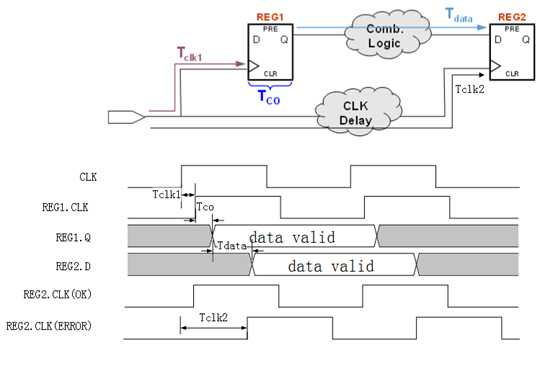
由于REG2.D端口上的数据将在REG2.CLK的上升沿被采样,那么。当使用全局时钟资源时可以看到,在REG2.CLK的上升沿前后一段时间,数据是保持稳定的。而使用非全局时钟资源的时候,由于时钟走线的延迟,REG2.CLK到达REG2的时间将会有一个较大的差值,在这种情况下。在REG2.CLK的上升沿前后,REG2.D上的数据可能已经不稳定甚至变化了。因此导致数据接收失败。
2、使用非全局布线资源,时钟信号在布线的过程中更容易受到周围信号的干扰。导致时钟质量变差。什么意思呢?打个比方,一只小鸟和一只兔子共同穿越一个满是灰尘的工地。工地上到处都是灰尘。小鸟从空中飞过,不直接与灰尘接触,因此基本不会沾到灰尘,因为它有自己独立的路线和空间。而兔子因为不会飞,因此只能跑着从工地中穿过,那么,不可避免的,兔子的脚上会沾上灰尘。导致当兔子穿过这个工地的时候,早已由小白兔变成了小灰兔。时钟信号也是如此,全局时钟资源有专门的时钟路径,在自己的空间走线,不穿过或很少穿过各种高速翻转的逻辑区域,因此很少受到污染。而非全局时钟资源没有专门的时钟路径,只能使用通用布线资源,而这些布线不可避免的会穿过很多高速翻转的逻辑区域。从而受到这些逻辑的翻转噪声的污染。最终时钟信号变的很差。例如边沿上升和下降更慢,占空比发送变化,时钟抖动增大等。
好了,回到问题的开头,由于AC620开发板上以太网PHY芯片的mii_tx_clk是连接到了FPGA的普通IO口上,因此如果不经过处理,该时钟信号将不能走全局时钟资源,因此只能通过普通布线资源走线,从而导致到达各个寄存器的时间差别很大,而且受到各个高速翻转逻辑的噪声影响也很大,时钟抖动严重。所以,当该时钟信号驱动的逻辑过多时,势必导致整个设计时序无法收敛,然后就会出现各种各样的问题。
接下分析下我所编写的以太网发送逻辑。由于该逻辑主要为讲解以太网的各种协议而设计,而以太网协议最典型的特征就是数据是分层打包的。因此我在设计该逻辑的时候也严格按照以太网分层的方式进行。分别为MAC层、IP层、UDP层和用户数据层。在MAC层、IP层和UDP层,我都使用了PHY提供的这个时钟信号,所以导致该时钟信号的扇出非常的高。
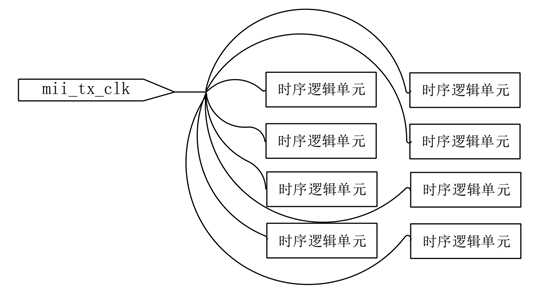
从Quartus II软件的编译报告可以看出,该时钟信号的扇出为193个。是所有非全局信号中扇出最高的。这么高扇出的一个信号,还是时钟,可以想象该时钟到达这193个位置的路径有多少种可能,要经过多少布线链接。可想而知该时钟信号有多差。所以,我在调试时候出现的问题就是——不做任何修改,将该工程编译多次,有的时候编译得到的sof文件下载进芯片后能跑一整夜不宕机,而有的时候编译得到的sof文件下载进入芯片后几秒钟内就宕机了。
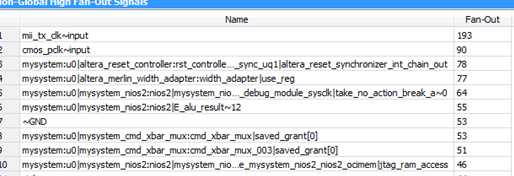
为了解决这个问题,需要将mii_tx_clk这个时钟信号分配到全局时钟资源上。这样该时钟信号就能走全局时钟资源,扇出再多,也能差不多同时到达各个寄存器。也有了自己的专线,不用从灰尘里滚爬,不怕小白兔变小灰兔。
首先看下全局资源的使用情况,如下图。

可以看到,PLL的4个输出,复位输入,以及晶振输入的50M时钟(clk)都被分配到了全局时钟资源上,尤其是clk信号,扇出高达1018个。
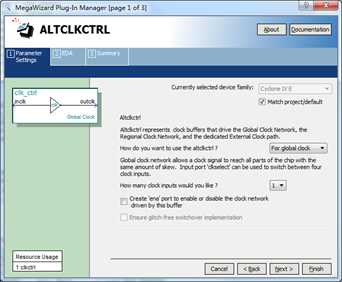
那么怎样才能让我们普通IO输入的时钟信号mii_tx_clk信号也能进入全局时钟资源呢?在Cyclone IV E器件中,有这样的专用缓冲器,该缓冲器可以将普通IO或者寄存器产生的时钟信号分配到全局时钟资源上。该缓冲器对用户以IP的形式提供,在IP列表的IO分组中,名称叫做ALTCLKCTRL,如下图所示。
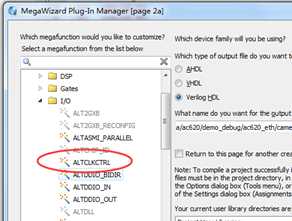
设置也非常简单只需选择该时钟控制器的用途,我们这里设置为"For global clock"。另外在输入数量那里选择相应的值即可,我们这里只需将mii_tx_clk接入全局时钟资源,不需要做多时钟切换,因此数量选择1,设置完成后点击finish即可。
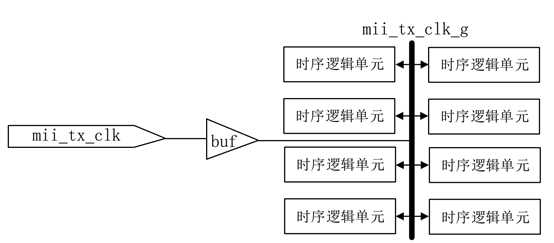
将该IP例化到我们的设计中,先定义一个mii_tx_clk_g,代表走全局时钟资源的mii_tx_clk信号。然后将输入的mii_tx_clk信号连接到这个缓冲器的输入,将缓冲器的输出连接到mii_tx_clk_g上即可,再由mii_tx_clk_g作为时钟信号驱动之前的所有时序逻辑。如下图所示。
|
wire mii_tx_clk_g; clk_ctrl clk_ctrl( .inclk(mii_tx_clk), .outclk(mii_tx_clk_g) ); |
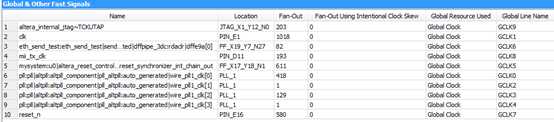
通过该缓冲器,将mii_tx_clk信号连接到了全局时钟资源上,再通过全局时钟资源去连接到各个寄存器,则时钟延迟和时钟抖动都变的很小,使得时序易于收敛,设计出来的系统就更加稳定了。下图为通过该缓冲器将mii_tx_clk分配到全局时钟信号上后的全局资源使用图,可以看到,mii_tx_clk信号已经被分配到了全局时钟资源上。再由此方式编译得到的sof文件,烧写到AC620开发板中,能持续稳定运行。再次编译工程,再下载测试,都能稳定运行,问题得以解决。
下图为使用AC620开发板进行以太网图传的实际照片。

总之,还是那句话:学无止境,治学严谨,学以致用。我是小梅哥,欢迎大家关注我,一起学习FPGA技术。
小梅哥
2017年7月8日星期六
武汉.光谷
标签:finish 开头 复位 资源 设置 时间差 lob 失败 关注
原文地址:http://www.cnblogs.com/xiaomeige/p/7135873.html