标签:概念 解析 方法 keep hang 封装 erro 请求 targe
web发展经历了一个漫长的周期,最开始很多人认为Javascript这们语言是前端开发的累赘,是个鸡肋,那个时候人们还享受着从一个a链接蹦到另一个页面的web神奇魔术。后来随着JavaScript的不断更新换代,他的功能不仅仅是为网页添加一点特效了,语言本身的加强以及对DOM操作能力的提升让他在前端大放光彩。尤其是ajax的出现,让JavaScript以及整个web的发展翻开了崭新的一页。
利用ajax局部刷新页面,相信很多人玩得相当熟练了。如果整个页面的刷新都是使用ajax,我们可以称之为一个webapp,所有的逻辑都是在当页处理,这种形式的页面带来的体验是十分不错的,减少了那些比较“冗余”的页面跳转、新开页面等。不过,webapp的代码是十分不好维护的,页面逻辑太多太深,出点小问题,整个页面就会瘫痪,而且不方便定位bug,可维护性很低。
ajax是一个非常好玩的小东西,不过用起来也会存在一些问题。
我们可以利用ajax进行无刷新改变文档内容,但是没办法去修改URL,有童鞋要问,这里为什么一定要修改URL呢?一个URL代表一个特定的网络资源,ajax修改了页面的内容,所以用不同的URL去标识他们,这个还是挺有必要的。
比如我们设计了一个单词查询的页面,比较合理的UR应该是http://example.com/word,不同的word对应不同的内容,但是如果整个页面都是ajax实现,我们就没法去修改/word了,当然我们可以使用hash如http://example.com#word,但这样就不能很好的处理浏览器的前进和后退问题。如:在页面中查询了单词A的翻译,接着又查询了单词B,这个时候浏览器的浏览历史会生成http://example.com#A和http://example.com#B两个记录,可是当我们从B转回A的时候,AJAX的效果还停留在B的状态(页面显示的还是单词B的翻译)。部分浏览器对此问题引入了onhashchange的接口,只要URL的hash值发生变化,我们的程序就可以监听并做出相应。不过对于那些木有这个接口的浏览器,就得定时去判断hash的变化了。
而这样的方式对搜索引擎是十分不友好的,twitter和google约定使用hash bang (#!xxx),也就是hash后面的第一个字符为感叹号,这样的网址他们是会爬取的,但是其他搜索引擎不支持。PJAX可以在改变页面内容的同时也改变他的URL,下面来说说PJAX和他的应用。
history API中有几个新特性,分别是history.pushState和history.replaceState,我们把pushState+AJAX进行封装,合起来简单点叫,就是PJAX~ 虽说实现技术上没什么新东西,但是概念上还是有所不同的。
PJAX的基本思路是,用户点击一个链接,通过ajax更新页面变化的部分,然后使用HTML5的pushState修改浏览器的URL地址,这样有效地避免了整个页面的重新加载。如果浏览器不支持history的两个新API或者JS被禁用了,那这个链接就只能跳转并重新刷新整个页面了。和传统的ajax设计稍微不同,ajax通常是从后台获取JSON数据,然后由前端解析渲染,而PJAX请求的是一个在服务器上生成好的HTML碎片,如下图所示:
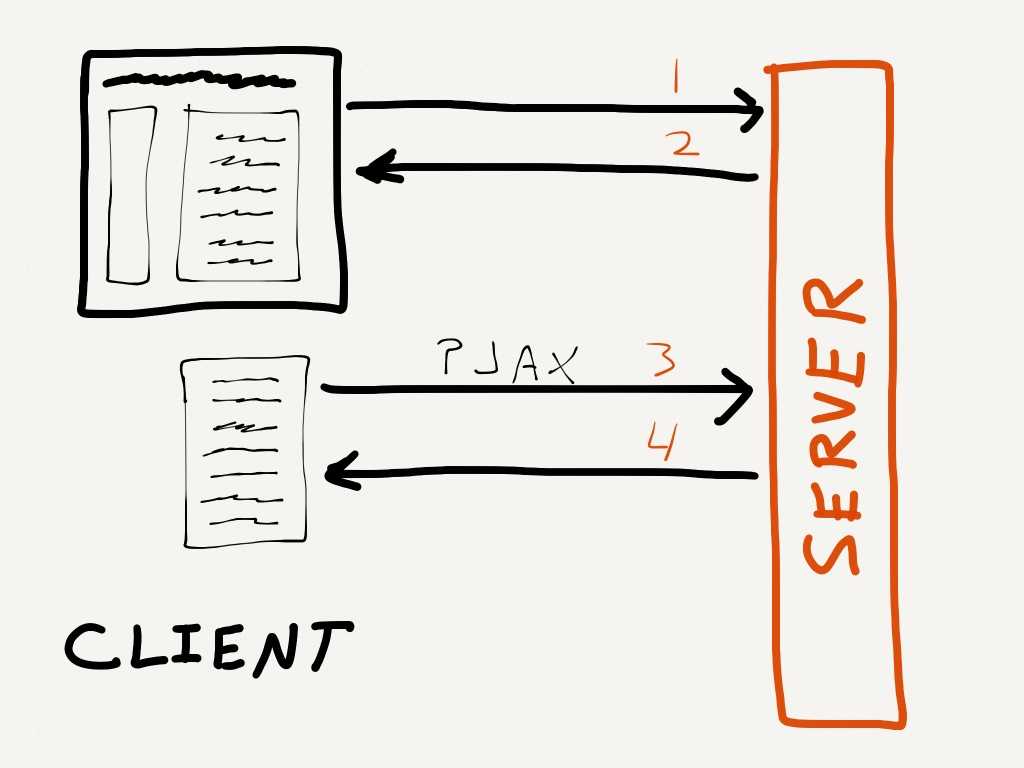
客户端向服务器发送一个普通的请求(1),其实也就是点击了一个链接,服务器会相应这个请求(2),返回一个html文档。客户端向服务器发送一个有PJAX标志的请求(3),此时服务器只返回一个html碎片(4)。但是这两次请求都让客户端的URL变化了,希望上面的说明可以让你明白了PAJX和AJAX的区别了。
先看一个小DEMO吧,这个DEMO也写了我半个多小时,看之前先说明一下,打开你的现代浏览器(chrome,Firefox,opera,IE9+等),进入gallery页面,查看图片的时候注意观察浏览器的title和url变化,点击前进后退按钮也注意查看其变化。我已经在浏览历史管理中push了三条历史记录。
DEMO地址:http://qianduannotes.duapp.com/demo/PJAX/index.html
如果你还没有理解上面说的PJAX和AJAX的区别,看完这个demo,你应该有所领悟吧!在URL变化之后,页面并没有刷新,而是继续完成自己的动画(demo中为fadeOut)。
在HTML4,Histroy对象有下面属性方法:
length:历史堆栈中的记录数。back():返回上一页。forward():前进到下一页。go([delta]):delta是个数字,如果不写或为0,则刷新本页;如果为正数,则前进到相应数目的页面;若为负数,则后退到相应数目的页面。在HTML5中,新增了两个方法:
pushState(data, title [, url]):往历史堆栈的顶部添加一条记录。data为一个对象或null,它会在触发window的popstate事件(window.onpopstate)时,作为参数的state属性传递过去;title为页面的标题,但当前所有浏览器都忽略这个参数;url为页面的URL,不写则为当前页。replaceState(data, title [, url]):更改当前页面的历史记录。参数同上。这种更改并不会去访问该URL。当点击“上一张”、“下一张”这两个链接的时候,首先通过pushState修改URL以及修改document.title,那这个时候你就可以当做文档已经进入了另外一个链接了,然后该干什么干什么。demo中是让图片fadeOut,fadeOut完了之后让浏览器去加载资源,这个步骤就是正常的AJAX操作啦,没有什么特殊之处了~
因为只准备了三张图片,所有后台写的也比较简单:
<?php
error_reporting(false);
$num = $_GET[‘num‘];
if(array_key_exists(‘HTTP_X_PJAX‘, $_SERVER) && $_SERVER[‘HTTP_X_PJAX‘] === ‘true‘){
if($num == 1) {
?>
<div class="imgwrap">
<img src="./images/1.jpg" />
</div>
<span><a href="num=2" class="next">下一张>></a></span>
<?php
} else if ($num == 2) {
?>
<div class="imgwrap">
<img src="./images/2.jpg" />
</div>
<span><a href="num=1" class="previous"><<上一张</a>
<a href="num=3" class="next">下一张>></a></span>
<?php
} else {
?>
<div class="imgwrap">
<img src="./images/3.jpg" />
</div>
<span><a href="num=2" class="previous"><<上一张</a></span>
<?php
}
}
?>
上面那张图中,我们看到了,并不是每个连接都使用PJAX来加载,如果有X_PJAX标识,我们才会添加相应的处理。js中稍加注意可以看到:
$.ajax({
"url": "./interface.php",
"data": {
"num": num
},
"dataType": "html",
"headers": {
"X_PJAX": true
}
});
请求中:
Accept:text/html, */*; q=0.01 Accept-Encoding:gzip,deflate,sdch Connection:keep-alive Host:qianduannotes.duapp.com User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36 X-Requested-With:XMLHttpRequest X_PJAX:true
我在请求的header中加了一个X_PJAX的头,而后台在处理的时候也做了判断:
function is_pjax(){
return array_key_exists(‘HTTP_X_PJAX‘, $_SERVER)
&& $_SERVER[‘HTTP_X_PJAX‘] === ‘true‘;
}
并不是一定要求在header头部中加入X_PJAX的信息,你也可以在url中加入相关的参数,比如:http://example.com?pjax=1,或者其他方式,只要前后端达到一个共识就行。
已经有人对这个东西做了封装,我就不重复造轮子了。
并不是页面中所有的链接都需要使用PJAX加载,所有在需要这个东西的a标签上加一个属性,如data-pjax=true,然后统一添加事件。
标签:概念 解析 方法 keep hang 封装 erro 请求 targe
原文地址:http://www.cnblogs.com/telwanggs/p/7136610.html