标签:学习 通过 图像 net pre 添加 over 标签 相对
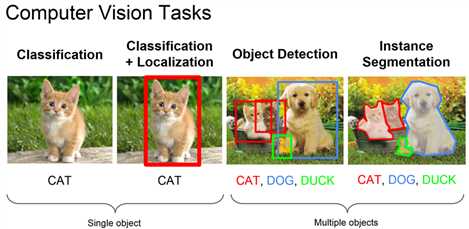
分类,定位,检测,图像分割辨析:
定位:
每张图片只有单个对象(可以有多个类),后面有提到,一般只要是固定个对象即可,不一定是一个(人体姿势判断部分)由于实现相对简单,所以能划分为定位任务时尽量划分为定位任务
检测:
每张图片可以有多个对象和多个类
分割:
不是简单的画框,而是围出轮廓,本节不予讨论
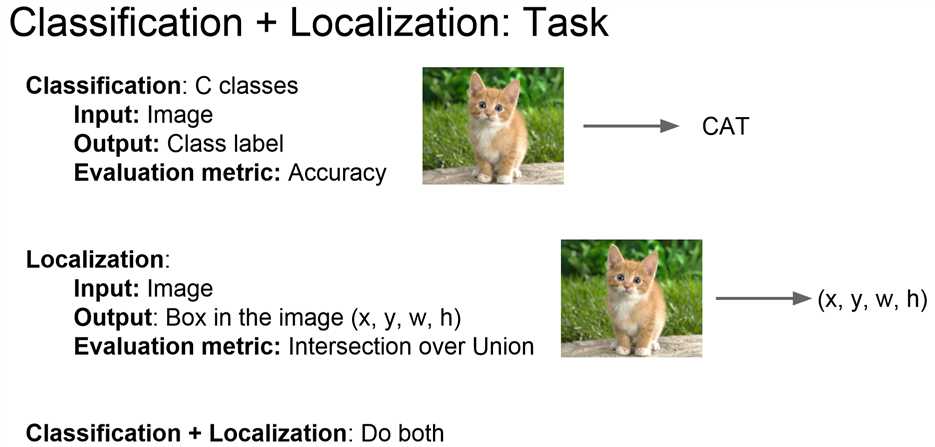
和分类任务输出一个代表类标签的向量不同,定位任务输出的是描述框的四个数字,而网络评估不使用准确率而使用IOU。【注】IOU定义如下:
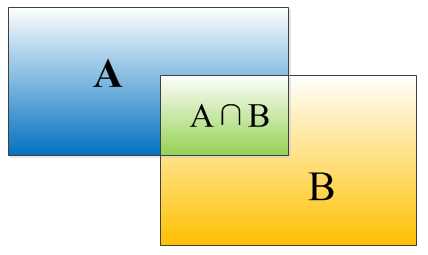
矩形框A、B的一个重合度IOU计算公式为:
IOU=(A∩B)/(A∪B)
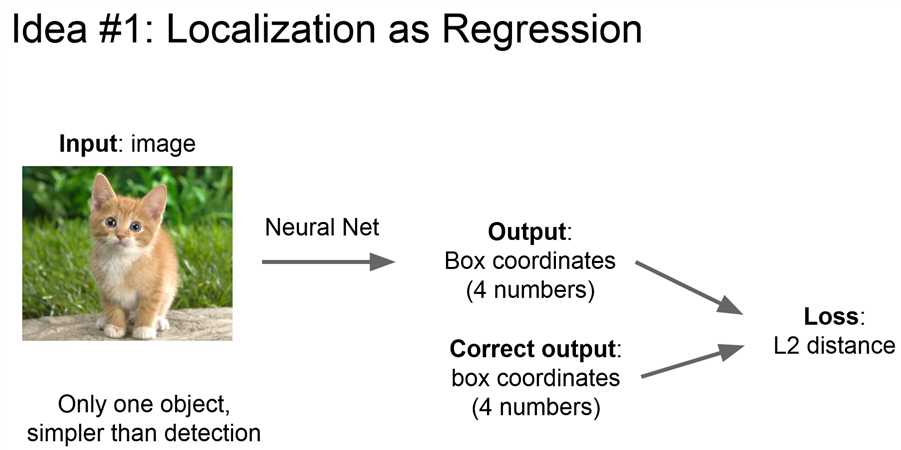
像训练回归任务一样训练定位任务:
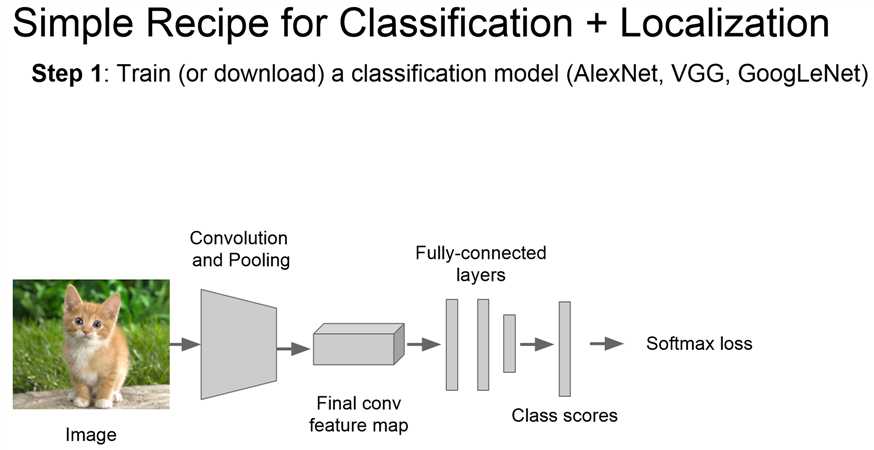
首先训练&下载一个分类模型(使用迁移学习的概念)
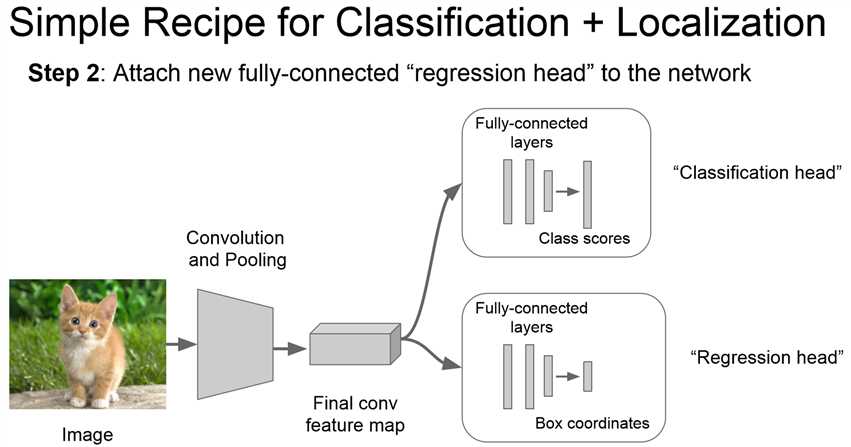
修改全链接层的结构:使N分类的最后一层输出改为输出4个数字。
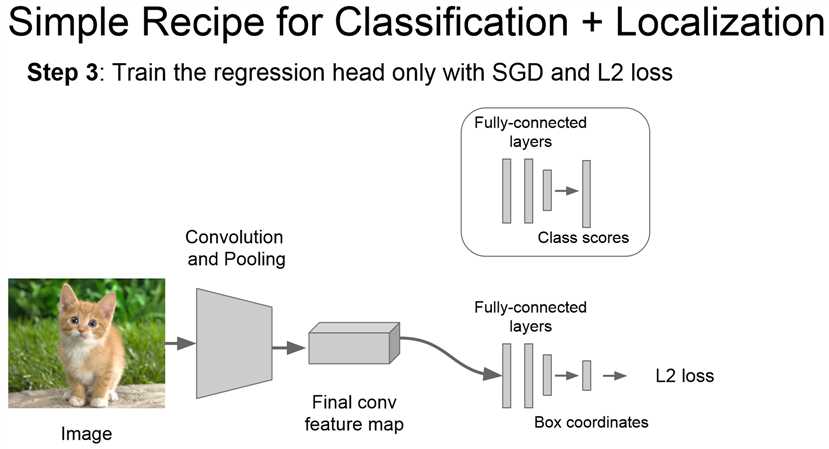
使用数据集训练新的网络。
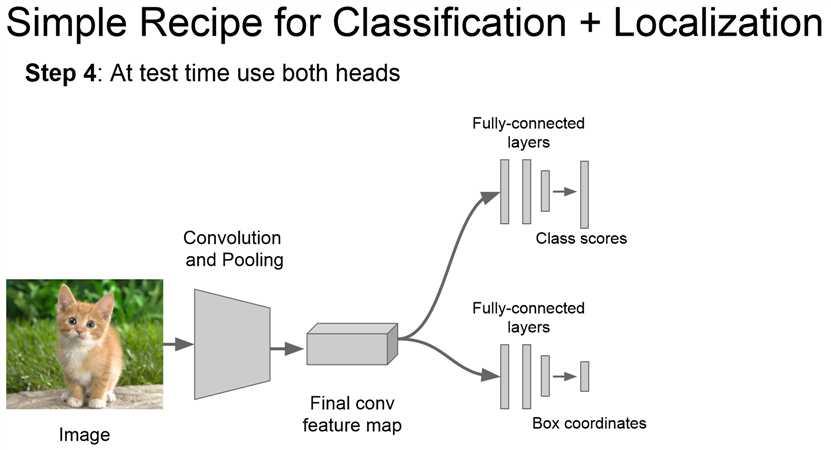
在测试时同时经过两个网络,实现分类&定位。
回归层输出值修改:
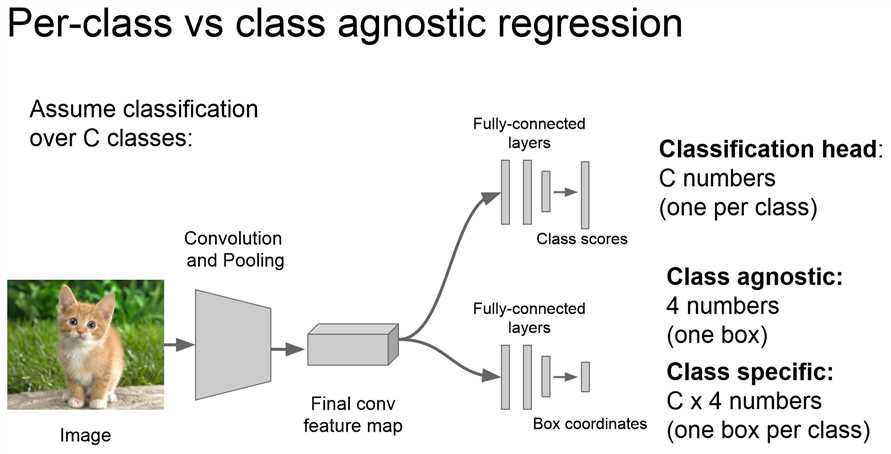
不同的回归层,假设是C分类问题:
回归层位置修改:
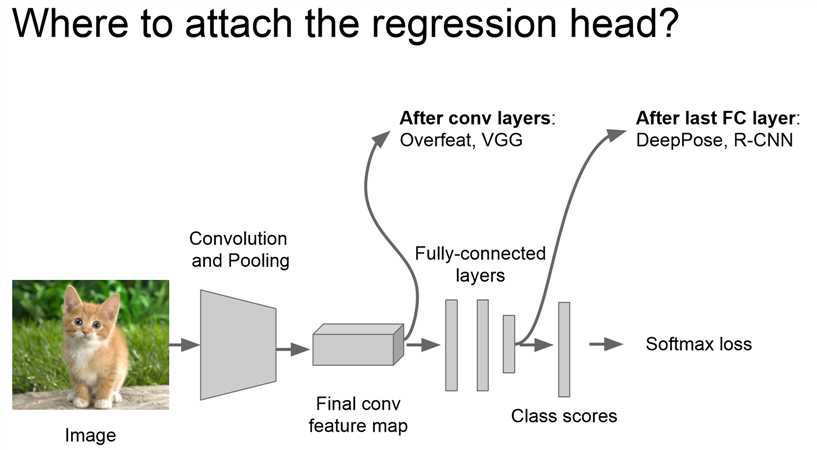
两种思路:
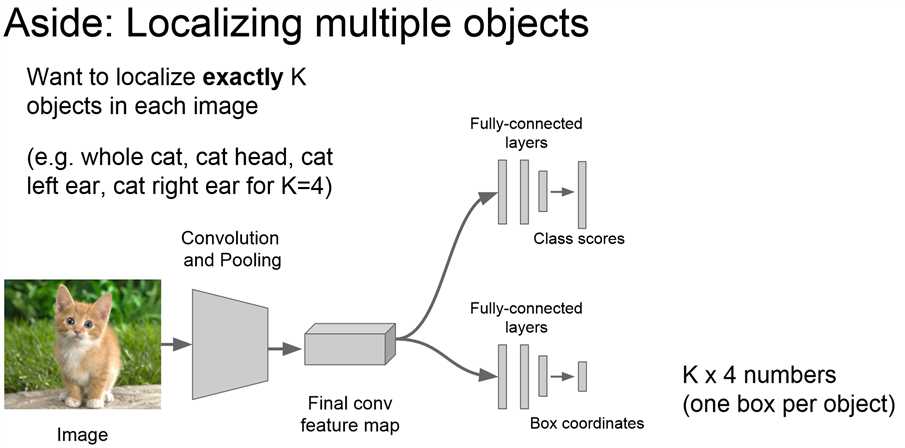
多目标定位:定位一个对象和他的子对象(个人理解是因为一个特定类对象的子对象种类数目是确定的,可以使用简单的定位网络完成,也是定位的思考一的成果)
人体姿势判断

Google的一篇论文,其思想就是使用CNN得到人体各个关节的位置后,对人体的姿势进行判断。

技术思路:
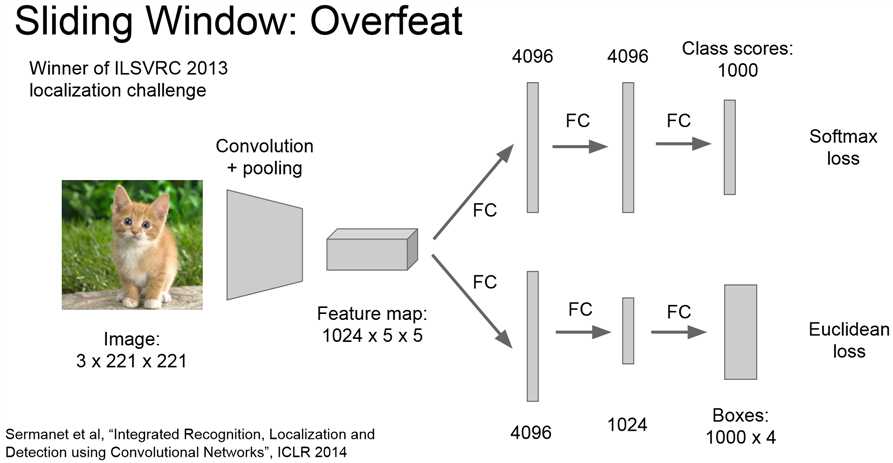
Overfeat网络,使用AlexNet的架构,添加一个定位网络后实现定位功能
经典滑窗定位小猫示意:







注意到有的框都画到滑窗外面去了,老师给出的解释是因为是回归,所以输出值理论可以是任何值,感觉虽然回归的确是这么个道理,但用在这里做解释始终不太信服。
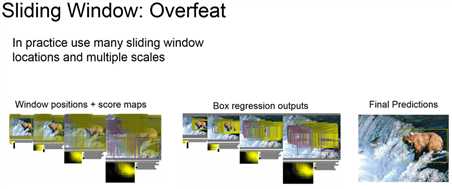
论文示意图:
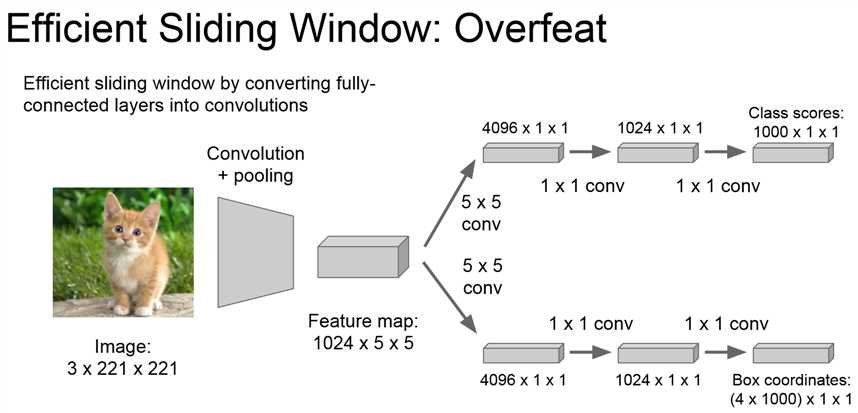
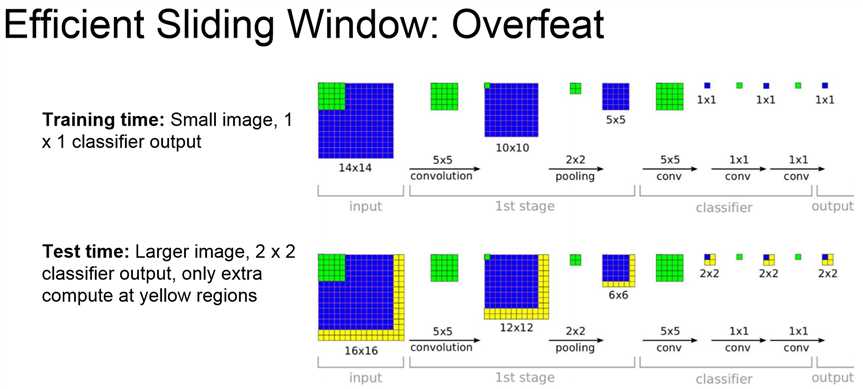
将全连接层替换为卷积层可以大大减少参数量,提升网络效率

标签:学习 通过 图像 net pre 添加 over 标签 相对
原文地址:http://www.cnblogs.com/hellcat/p/7140445.html