标签:左右 java type 个数 路径 内容 新一代 汉字 bsp
TCP/IP协议不是TCP和IP这两个协议的合称,而是指因特网整个TCP/IP协议族。
从协议分层模型方面来讲,TCP/IP由四个层次组成:网络接口层、网络层、传输层、应用层。
TCP协议:即传输控制协议,它提供的是一种可靠的数据流服务。当传送受差错干扰的数据,或举出网络故障,或网络负荷太重而使网际基本传输系统不能正常工作时,就需要通过其他的协议来保证通信的可靠。TCP就是这样的协议。TCP采用“带重传的肯定确认”技术来实现传输的可靠性。并使用“滑动窗口”的流量控制机制来高网络的吞吐量。TCP通信建立实现了一种“虚电路”的概念。双方通信之前,先建立一条链接然后双方就可以在其上发送数据流。这种数据交换方式能提高效率,但事先建立连接和事后拆除连接需要开销。
本文主要讲述的是
1、TCP三次握手原理,以及为什么要三次握手,两次握手带来的不利后果。
2、TCP四次挥手原理,为什么要四次挥手。
TCP三次握手原理:
首先,给张图片,建立TCP三次握手的直观印象。
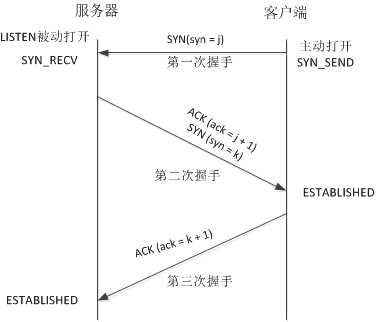
每次握手(发送数据请求或应答)时,发送的数据为TCP报文,TCP段包含了源/目的地址,端口号,初始序号,滑动窗口大小,窗口 扩大因子,最大报文段长度等。还有一些标志位:
(1)SYN:同步序号
(2)ACK:应答回复
(3)RST:复位连接,消除旧有的同步序号
(4)PSH:尽可能的将数据送往接收进程
(5)FIN:发送方完成数据发送
(6)URG
从图中,可以看出三次握手的基本步骤是:
第一次握手:客户端向服务器端发送连接请求包SYN(syn=j),等待服务器回应;
第二次握手:服务器端收到客户端连接请求包SYN(syn=j)后,将客户端的请求包SYN(syn=j)放入到自己的未连接队列,此时服务器需要发送两个包给客户端;
(1)向客户端发送确认自己收到其连接请求的确认包ACK(ack=j+1),向客户端表明已知道了其连接请求
(2)向客户端发送连接询问请求包SYN(syn=k),询问客户端是否已经准备好建立连接,进行数据通信;
即在第二次握手时服务器向客户端发送ACK(ack=j+1)和SYN(syn=k)包,此时服务器进入SYN_RECV状态。
第三次握手:客户端收到服务器的ACK(ack=j+1)和SYN(syn=k)包后,知道了服务器同意建立连接,此时需要发送连接已建立的消息给服务器;
向服务器发送连接建立的确认包ACK(ack=k+1),回应服务器的SYN(syn=k)告诉服务器,我们之间已经建立了连接,可以进行数据通信。
ACK(ack=k+1)包发送完毕,服务器收到后,此时服务器与客户端进入ESTABLISHED状态,开始进行数据传送。
为什么不能只两次握手?
有了三次握手的详细步骤,就可以分析为什么需要三次握手而不是两次握手了。
三次握手的目的:消除旧有连接请求的SYN消息对新连接的干扰,同步连接双方的序列号和确认号并交换TCP 窗口大小信息。
设想:如果只有两次握手,那么第二次握手后服务器只向客户端发送ACK包,此时客户端与服务器端建立连接。在这种握手规则下:
假设:如果发送网络阻塞,由于TCP/IP协议定时重传机制,B向A发送了两次SYN请求,分别是x1和x2,且因为阻塞原因,导致x1连接请求和x2连接请求的TCP窗口大小和数据报文长度不一致,如果最终x1达到A,x2丢失,此时A同B建立了x1的连接,这个时候,因为AB已经连接,B无法知道是请求x1还是请求x2同B连接,如果B默认是最近的请求x2同A建立了连接,此时B开始向A发送数据,数据报文长度为x2定义的长度,窗口大小为x2定义的大小,而A建立的连接是x1,其数据包长度大小为x1,TCP窗口大小为x1定义,这就会导致A处理数据时出错。
很显然,如果A接收到B的请求后,A向B发送SYN请求y3(y3的窗口大小和数据报长度等信息为x1所定义),确认了连接建立的窗口大小和数据报长度为x1所定义,A再次确认回答建立x1连接,然后开始相互传送数据,那么就不会导致数据处理出错了。
TCP释放连接需四次挥手
先看图,直观的了解下:
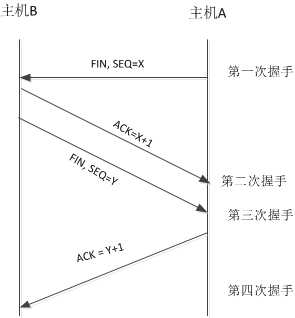
需四次挥手原因:由于TCP的半关闭特性,TCP连接时双全工(即数据在两个方向上能同时传递),因此,每个方向必须单独的进行关闭。这个原则就是:当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向上的连接。当一端收到一个FIN后,它必须通知应用层另一端已经终止了那个方向的数据传送。即收到一个FIN意味着在这一方向上没有数据流动了。
目的:保证服务器与客户端都能完全的接受对方发送的数据。
假设客户机A向服务器B请求释放TCP连接,则:
第一次挥手:主机A向主机B发送FIN包;A告诉B,我(A)发送给你(B)的数据大小是N,我发送完毕,请求断开A->B的连接。
第二次挥手:主机B收到了A发送的FIN包,并向主机A发送ACK包;B回答A,是的,我总共收到了你发给我N大小的数据,A->B的连接关闭。
第三次挥手:主机B向主机A发送FIN包;B告诉A,我(B)发送给你(A)的数据大小是M,我发送完毕,请求断开B->A的连接。
第四次挥手:主机A收到了B发送的FIN包,并向主机B发送ACK包;A回答B,是的,我收到了你发送给我的M大小的数据,B->A的连接关闭。
简单的说就是,用一小段简单的各种字符的组合,即叫做 正则表达式,去实现复杂的:
字符串匹配,查找你到你所需要的内容,以便后期提取出来你所要的内容。
这个听起来很简单,但是很多现实的应用中,所要处理的字符串有千千万万种,各种复杂的字符,而且每个人的需求有无穷尽种,需要提取出的内容也是无穷多。而如果手动处理,写普通的if else语句去一点点判断字符串是否相等,则是无法实现的。
而用正则,就可以实现如此多的,繁杂的,极度复杂的,各种需求。
更多的内容,可以看看我所总结的:
正则表达式学习心得
再举几个实际的例子:
Notepad++正则表达式替换举例1:一次性替换多个文件的后缀
Notepad++正则表达式替换举例2:一次性替换多个路径
Notepad++正则表达式替换举例3:一次性替换多个listitem为sect4
Notepad++正则表达式替换举例4:给每一行都添加AddIcon的前缀
Notepad++正则表达式替换举例5:给book的标题和地址添加html代码
身份证号码的匹配
大陆的居民身份证号码有两种:18位和15位,15位的身份证号码是老一代身份证号码。
18位和15位的区别在于两个部分:第一,18位号码的年份以4位计而15位号码的年份为2位,如1987年在18位号码中为‘1987’而在15位号码中为‘87’,这里1987只是作为一个例子可能1987年及以后根本不存在15位号码;第二处不同在于18位号码的最后一位为数字校验码,15位号码没有数字校验位。
好吧,可能你还不知道身份证号码各个部分代表着什么,那么让我简略地介绍一下。
身份证号码总共有4个部分(15位号码只有3部分),从左向右分别为:第一部分有6位,为居民在办理身份证时户口所在地的地址码(什么是地址码?自己到统计局去找吧,地址如下:http://www.stats.gov.cn/tjbz/index.htm);第二部分有8位(15位号码为6位),为居民出生日期码;第三部分有3位,为数字顺序码,也就是同一天出生的人的一个排序,奇数代表男性而偶数代表女性;第四部分也就是最后一部分有1位,为数字校验码,此部分只有18位号码才有,关于数字校验码怎样计算得出,稍后会详述。
先举个例子吧,假设存在以下身份证号码:35052519870101888X(15位的话为350525870101888),用‘-’号将各部分区分如下:350525-19870101-888-X。其中,350525为地址码,没错,到统计局查询的结果是‘福建省永春县’——一个桃园胜境,算了,不废话;19870101为出生日期码,呵呵,1987年1月1日这一天出生的人肯定是有滴;888为顺序码,估计1987年1月1日第888个出生的人应该没有吧,倘若真的有,那真不是人,是神!!呵呵,估计我党也不会给神这个号码,不多说了,再多说可能要人神共怒了……好吧,那么X是什么呢?怎么有些人的身份证号码最后一位会突然冒出一个X呢,是这些人比较特殊吗?答案是:不是的,也算是吧,倘若有一种个位数等于10,这些人也不用在身份证号码的最后一位被不明不白地加上一个X了,究竟是怎么一回事且听我细细道来^_^
18位居民身份证号码最后一位——数字校验码的计算方法:
1. 将身份证号码的前17位数分别乘以以下系数:7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2;
2. 将以上分别相乘得到的结果相加;
3. 将以上相加的结果除以11,得出余数;
4. 以上得出的余数可能为0 - 10这11个数中的某一个数字。10是一个另类,因为我们的数字校验位只有1位显然需要一种替换方案,用1位将10换下,于是X派上用场了。注意了,数字校验位并不就是余数!!所得的11个余数:
0,1,2,3,4,5,6,7,8,9,10 的数字校验位分别为:
1,0,X,9,8,7,6,5,4,3,2
PS:通过以上的计算,现在应该非常清楚了,身份证号码的最后一位为X是因为在作校验时所得的余数是2,显然这些号码也没什么特别的吗。需要强调一下的是,X并不是英文字母哦,而是罗马数字X,记住,它不是字母而是数字,但是,呵呵,我们一般用英文大写字母X来表示罗马数字X,囧nz……
让我花点时间来校验以上的身份证号码:35052519870101888X是否正确吧,先声明倘若证实可用千万别拿去做假证,一切本人概不负责!
1.前17位分别乘以相应系数:3*7+5*9+0*10+5*5+2*8+5*4+1*2+9*1+8*6+7*3+0*7+1*9+0*10+1*5+8*8+8*4+8*2=333(假如没算错的话^_^)
2.将以上所得结果333除以11,得出余数:3
3.呵呵35052519870101888X这个号码不是有效的身份证号码,有效号码应该为350525198701018889
好了,知道了居民身份证号码各部分的意思后,我们终于可以动手寻求号码验证的解决方案了。
假设我们的系统并不知道输入号码之人的任何信息(如果系统还要求输入籍贯和出生日期,还可以进一步进行检验真伪喔^_^)
首先,地址码的前2位是省级的编号,到统计局去查询得知第1位非0,并且目前的范围为1-9,9是国外的身份证号码。第2位的范围为0-7。统计局一般每一年都会公布一次更新的地址码,但对比多年来的地址码可以看出地址码基本上是不变的(要是变了,现有的身份证号码岂不是都没用了^_^)。我们的地址码的正则表达式可以这样写:/^[1-9][0-7]\d{4}/,其实,这么写不够精确,倘若要就目前的地址码写出精确的表达式,应该这么写/^((1[1-5])|(2[1-3])|(3[1-7])|(4[1-6])|(5[0-4])|(6[1-5])|71|(8[12])|91)\d{4}/,这样写显然精确多了,但表达式长了很多,当然为求精确表达式长一点是可以接受的,但是假如统计局修改了省级地址码,那么该表达式要根据实际情况稍作改动,所幸省级地址码应该是不会变的,呵呵,所以选择哪一种表达式都是可以的,我这就不写那么长的表达式了,所以选择/^[1-9][0-7]\d{4}/吧。
接下来就是日期了喔,呵呵,貌似之前写过的日期匹配可以借鉴来用一下,当时的那个表达式如下:
/^((((19|20)\d{2})-(0?[13-9]|1[012])-(0?[1-9]|[12]\d|30))|(((19|20)\d{2})-(0?[13578]|1[02])-31)|(((19|20)\d{2})-0?2-(0?[1-9]|1\d|2[0-8]))|((((19|20)([13579][26]|[2468][048]|0[48]))|(2000))-0?2-29))$/
这个表达式可以匹配1900-2099年的日期,还支持闰年。
我们的表达式不需要匹配那么长的时间,能够匹配二十世纪的就够了,什么,不知道二十世纪?1900-1999总该知道吧^_^为什么匹配了这个范围就够了呢?去查一下居民身份证的历史吧,我敢打保票1900-1999的范围还太大了。至于二十一世纪的新一代,呵呵,就算他是2000年出生的,目前也就15岁(有些算法是14岁,囧),这些人的号码应该还打印在户口簿里,拿出手也不会产生什么作用,再说,二十一世纪的人也不屑于我目前所写的匹配^_^
好吧,废话太多了,开始匹配日期吧。稍微修改了以上表达式:
/((19\d{2}(0[13-9]|1[012])(0[1-9]|[12]\d|30))|(19\d{2}(0[13578]|1[02])31)|(19\d{2}02(0[1-9]|1\d|2[0-8]))|(19([13579][26]|[2468][048]|0[48])0229))/
正则表达式里没有计算验证的能力,所以对于顺序码,我们除了基本的匹配外无力于做什么,所以顺序码的表达式为:/\d{3}/
最后一位数字验证码——/(\d|X|x)?$/。之所以那么写是因为,最后一位可能值为数字或X,但有些人可能习惯将X写成小写的x,我们必须视为正确,而最后的?是为了与15位号码兼容,此时只需将15位号码的年份用4位表示即可用我们以下整合的表达式进行匹配了——
/^[1-9][0-7]\d{4}((19\d{2}(0[13-9]|1[012])(0[1-9]|[12]\d|30))|(19\d{2}(0[13578]|1[02])31)|(19\d{2}02(0[1-9]|1\d|2[0-8]))|(19([13579][26]|[2468][048]|0[48])0229))\d{3}(\d|X|x)?$/
地址码精确一点的表达式:
/^((1[1-5])|(2[1-3])|(3[1-7])|(4[1-6])|(5[0-4])|(6[1-5])|71|(8[12])|91)\d{4}((19\d{2}(0[13-9]|1[012])(0[1-9]|[12]\d|30))|(19\d{2}(0[13578]|1[02])31)|(19\d{2}02(0[1-9]|1\d|2[0-8]))|(19([13579][26]|[2468][048]|0[48])0229))\d{3}(\d|X|x)?$/
区号+座机号码+分机号码:regexp="^(0[0-9]{2,3}/-)?([2-9][0-9]{6,7})+(/-[0-9]{1,4})?$"
手机(中国移动手机号码):regexp="^((/(/d{3}/))|(/d{3}/-))?13[456789]/d{8}|15[89]/d{8}"
所有手机号码:regexp="^((/(/d{3}/))|(/d{3}/-))?13[0-9]/d{8}|15[89]/d{8}"(新添加了158,159两个号段)
((/d{11})|^((/d{7,8})|(/d{4}|/d{3})-(/d{7,8})|(/d{4}|/d{3})-(/d{7,8})-(/d{4}|/d{3}|/d{2}|/d{1})|(/d{7,8})-(/d{4}|/d{3}|/d{2}|/d{1}))$)
匹配格式:
11位手机号码
3-4位区号,7-8位直播号码,1-4位分机号
如:12345678901、1234-12345678-1234
1.用正则表达式限制只能输入全角字符: onkeyup="value=value.replace(/[^/uFF00-/uFFFF]/g,‘‘)" onbeforepaste="clipboardData.setData(‘text‘,clipboardData.getData(‘text‘).replace(/[^/uFF00-/uFFFF]/g,‘‘))"
2.用正则表达式限制只能输入数字:onkeyup="value=value.replace(/[^/d]/g,‘‘) "onbeforepaste="clipboardData.setData(‘text‘,clipboardData.getData(‘text‘).replace(/[^/d]/g,‘‘))"
3.用正则表达式限制只能输入数字和英文:onkeyup="value=value.replace(/[/W]/g,‘‘) "onbeforepaste="clipboardData.setData(‘text‘,clipboardData.getData(‘text‘).replace(/[^/d]/g,‘‘))"
4.计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
String.prototype.len=function(){return this.replace([^/x00-/xff]/g,"aa").length;}
5.javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现,如下:
String.prototype.trim = function()
{
return this.replace(/(^/s*)|(/s*$)/g, "");
}
利用正则表达式分解和转换IP地址:
6.下面是利用正则表达式匹配IP地址,并将IP地址转换成对应数值的Javascript程序:
function IP2V(ip)
{
re=/(/d+)/.(/d+)/.(/d+)/.(/d+)/g //匹配IP地址的正则表达式
if(re.test(ip))
{
return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4*1
}
else
{
throw new Error("不是一个正确的IP地址!")
}
}
不过上面的程序如果不用正则表达式,而直接用split函数来分解可能更简单,程序如下:
var ip="10.100.20.168"
ip=ip.split(".")
alert("IP值是:"+(ip[0]*255*255*255+ip[1]*255*255+ip[2]*255+ip[3]*1))
正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些常用的表达式收集于此,以备不时之需。
匹配中文字符的正则表达式: [/u4e00-/u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^/x00-/xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:/n/s*/r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(/S*?)[^>]*>.*?<//1>|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^/s*|/s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:/w+([-+.]/w+)*@/w+([-.]/w+)*/./w+([-.]/w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^/s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:/d{3}-/d{8}|/d{4}-/d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]/d{5}(?!/d)
评注:中国邮政编码为6位数字
匹配身份证:/d{15}|/d{18}
评注:中国的身份证为15位或18位
匹配ip地址:/d+/./d+/./d+/./d+
评注:提取ip地址时有用
匹配特定数字:
^[1-9]/d*$ //匹配正整数
^-[1-9]/d*$ //匹配负整数
^-?[1-9]/d*$ //匹配整数
^[1-9]/d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]/d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]/d*/./d*|0/./d*[1-9]/d*$ //匹配正浮点数
^-([1-9]/d*/./d*|0/./d*[1-9]/d*)$ //匹配负浮点数
^-?([1-9]/d*/./d*|0/./d*[1-9]/d*|0?/.0+|0)$ //匹配浮点数
^[1-9]/d*/./d*|0/./d*[1-9]/d*|0?/.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]/d*/./d*|0/./d*[1-9]/d*))|0?/.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^/w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
评注:最基本也是最常用的一些表达式
匹配中文字符的正则表达式: [/u4e00-/u9fa5]
匹配双字节字符(包括汉字在内):[^/x00-/xff]
匹配空行的正则表达式:/n[/s| ]*/r
匹配HTML标记的正则表达式:/<(.*)>.*<///1>|<(.*) //>/
匹配首尾空格的正则表达式:(^/s*)|(/s*$)
匹配Email地址的正则表达式:/w+([-+.]/w+)*@/w+([-.]/w+)*/./w+([-.]/w+)*
匹配网址URL的正则表达式:http://([/w-]+/.)+[/w-]+(/[/w- ./?%&=]*)?
^/d+$ //匹配非负整数(正整数 + 0)
^[0-9]*[1-9][0-9]*$ //匹配正整数
^((-/d+)|(0+))$ //匹配非正整数(负整数 + 0)
^-[0-9]*[1-9][0-9]*$ //匹配负整数
^-?/d+$ //匹配整数
^/d+(/./d+)?$ //匹配非负浮点数(正浮点数 + 0)
^(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*))$ //匹配正浮点数
^((-/d+(/./d+)?)|(0+(/.0+)?))$ //匹配非正浮点数(负浮点数 + 0)
^(-(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*)))$ //匹配负浮点数
^(-?/d+)(/./d+)?$ //匹配浮点数
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^/w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
^[/w-]+(/.[/w-]+)*@[/w-]+(/.[/w-]+)+$
"^/d+$" //非负整数(正整数 + 0)
"^[0-9]*[1-9][0-9]*$" //正整数
"^((-/d+)|(0+))$" //非正整数(负整数 + 0)
"^-[0-9]*[1-9][0-9]*$" //负整数
"^-?/d+$" //整数
"^/d+(/./d+)?$" //非负浮点数(正浮点数 + 0)
"^(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数
"^((-/d+(/./d+)?)|(0+(/.0+)?))$" //非正浮点数(负浮点数 + 0)
"^(-(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点
数
"^(-?/d+)(/./d+)?$" //浮点数
"^[A-Za-z]+$" //由26个英文字母组成的字符串
"^[A-Z]+$" //由26个英文字母的大写组成的字符串
"^[a-z]+$" //由26个英文字母的小写组成的字符串
"^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串
"^/w+$" //由数字、26个英文字母或者下划线组成的字符串
"^[/w-]+(/.[/w-]+)*@[/w-]+(/.[/w-]+)+$" //email地址
"^[a-zA-z]+://(/w+(-/w+)*)(/.(/w+(-/w+)*))*(/?/S*)?$" //url
/^13/d{9}$/gi手机号正则表达式
public static bool IsValidMobileNo(string MobileNo)
{
const string regPattern = @"^(130|131|132|133|134|135|136|137|138|139)/d{8}$";
return Regex.IsMatch(MobileNo, regPattern);
}
正则表达式--验证手机号码:13[0-9]{9}
实现手机号前带86或是+86的情况:^((/+86)|(86))?(13)/d{9}$
电话号码与手机号码同时验证:(^(/d{3,4}-)?/d{7,8})$|(13[0-9]{9})
提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *= *(‘|")?(/w|//|//|/.)+(‘|"| *|>)?
提取信息中的邮件地址:/w+([-+.]/w+)*@/w+([-.]/w+)*/./w+([-.]/w+)*
提取信息中的图片链接:(s|S)(r|R)(c|C) *= *(‘|")?(/w|//|//|/.)+(‘|"| *|>)?
提取信息中的IP地址:(/d+)/.(/d+)/.(/d+)/.(/d+)
提取信息中的中国手机号码:(86)*0*13/d{9}
提取信息中的中国固定电话号码:(/(/d{3,4}/)|/d{3,4}-|/s)?/d{8}
提取信息中的中国电话号码(包括移动和固定电话):(/(/d{3,4}/)|/d{3,4}-|/s)?/d{7,14}
提取信息中的中国邮政编码:[1-9]{1}(/d+){5}
提取信息中的中国身份证号码:/d{18}|/d{15}
提取信息中的整数:/d+
提取信息中的浮点数(即小数):(-?/d*)/.?/d+
提取信息中的任何数字 :(-?/d*)(/./d+)?
提取信息中的中文字符串:[/u4e00-/u9fa5]*
提取信息中的双字节字符串 (汉字):[^/x00-/xff]*
物体运动原理:通过改变物体的位置,而发生移动变化。
方法:
1.运动的物体使用绝对定位
2.通过改变定位物体的属性(left、right、top、bottom)值来使物体移动。例如向右或左移动可以使用offsetLeft(offsetRight)来控制左右移动。
步骤:
1、开始运动前,先清除已有定时器 (因为:是连续点击按钮,物体会运动越来越快,造成运动混乱)
2、开启定时器,计算速度
3、把运动和停止隔开(if/else),判断停止条件,执行运动
一.定时器
在javascritp中,有两个关于定时器的专用函数,它们是:
1.倒计定时器:timename=setTimeout("function();",delaytime);
2.循环定时器:timename=setInterval("function();",delaytime);
function()是定时器触发时要执行的是事件的函数,可以是一个函数,也可以是几个函数,或者javascript的语句也可以,单要用;隔开;delaytime则是间隔的时间,以毫秒为单位。
倒计时定时器就是在指定时间后触发事件,而循环定时器就是在间隔时间到来时反复触发事件,其区别在于:前者只是作用一次,而后者则不停地作用。
倒计时定时器一般用于页面上只需要触发一次的的情况,比如点击某按钮后页面在一定时间后跳转到相应的站点,也可以用于判断一个浏览者是不是你的站点上的“老客”,如果不是,你就可以在5秒或者10秒后跳转到相应的站点,然后告诉他以后再来可以在某个地方按某一个按钮就可以快速进入。
循环定时器一般用于站点上需要从复执行的效果,比如一个javascript的滚动条或者状态栏,也可以用于将页面的背景用飞雪的图片来表示。这些事件需要隔一段时间运行一次。
有时候我们也想去掉一些加上的定时器,此时可以用clearTimeout(timename) 来关闭倒计时定时器,而用clearInterval(timename)来关闭循环定时器。
标签:左右 java type 个数 路径 内容 新一代 汉字 bsp
原文地址:http://www.cnblogs.com/z123123/p/7143680.html