标签:lis cu2 lnl 理解 思考 3.2 font gps ilo
手头现在有一份福布斯2016年全球上市企业2000强排行榜的数据,但原始数据并不规范,需要处理后才能进一步使用。
本文通过实例操作来介绍用pandas进行数据整理。
照例先说下我的运行环境,如下:
在拿到原始数据后,我们先来看看数据的情况,并思考下我们需要什么样的数据结果。
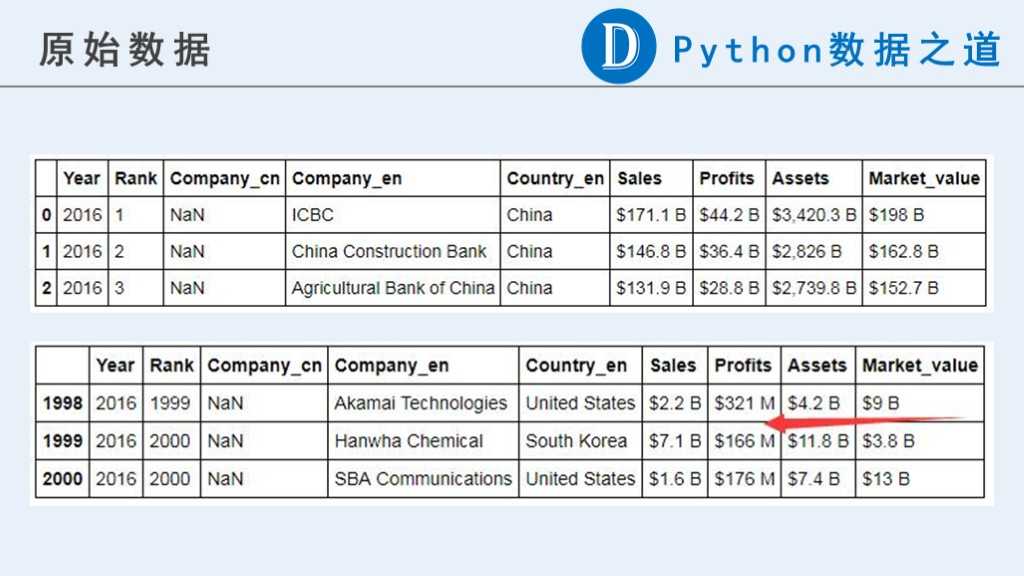
下面是原始数据:
在本文中,我们需要以下的初步结果,以供以后继续使用。
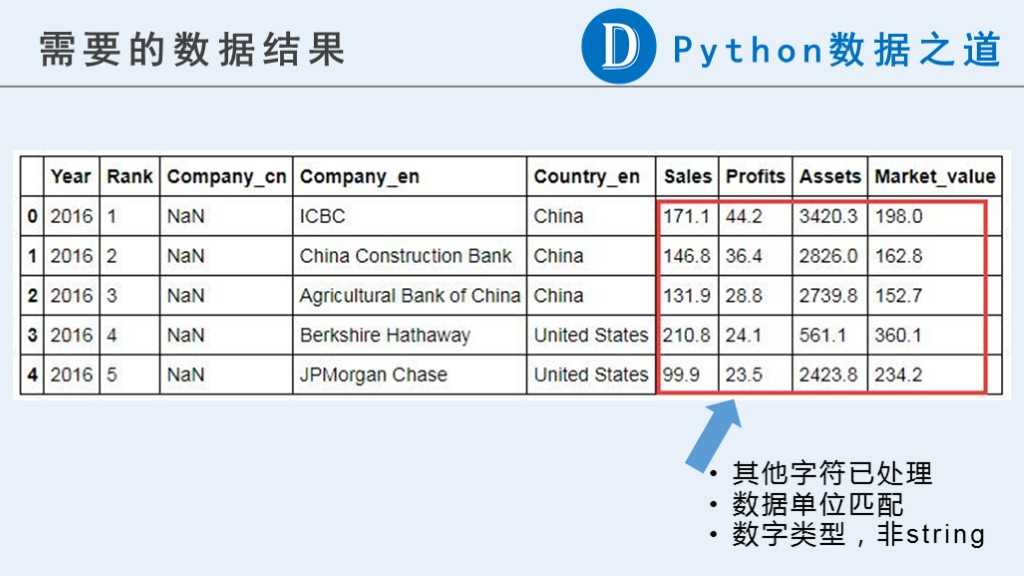
可以看到,原始数据中,跟企业相关的数据中(“Sales”,“Profits”,“Assets”,“Market_value”),目前都是不是可以用来计算的数字类型。
原始内容中包含货币符号”$“,“-”,纯字母组成的字符串以及其他一些我们认为异常的信息。更重要的是,这些数据的单位并不一致。分别有以“B”(Billion,十亿)和“M”(Million,百万)表示的。在后续计算之前需要进行单位统一。
首先想到的处理思路就是将数据信息分别按十亿(’B’)和百万(‘M’)进行拆分,分别进行处理,最后在合并到一起。过程如下所示。
import pandas as pd
df_2016 = pd.read_csv(‘data_2016.csv‘, encoding=‘gbk‘,header=None)
# 更新列名
df_2016.columns = [‘Year‘, ‘Rank‘, ‘Company_cn‘,‘Company_en‘,
‘Country_en‘, ‘Sales‘, ‘Profits‘, ‘Assets‘, ‘Market_value‘]
print(‘the shape of DataFrame: ‘, df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)
# 数据单位为 B的数据(Billion,十亿)
df_2016_b = df_2016[df_2016[‘Sales‘].str.endswith(‘B‘)]
print(df_2016_b.shape)
df_2016_b
# 数据单位为 M的数据(Million,百万)
df_2016_m = df_2016[df_2016[‘Sales‘].str.endswith(‘M‘)]
print(df_2016_m.shape)
df_2016_m
这种方法理解起来比较简单,但操作起来会比较繁琐,尤其是如果有很多列数据需要处理的话,会花费很多时间。
进一步的处理,我这里就不描述了。当然,各位可以试试这个方法。
下面介绍稍微简单一点的方法。
第一步还是加载数据,跟Method-1是一样的。
下面来处理’Sales’列
首先是替换相关的异常字符,包括美元的货币符号’$’,纯字母的字符串’undefined’,以及’B’。 这里,我们想统一把数据的单位整理成十亿,所以’B’可以直接进行替换。而’M’需要更多的处理步骤。
处理含有百万“M”为单位的数据,即以“M”结尾的数据,思路如下:
(1)设定查找条件mask;
(2)替换字符串“M”为空值
(3)用pd.to_numeric()转换为数字
(4)除以1000,转换为十亿美元,与其他行的数据一致
上面两个步骤相关的代码如下:
# 替换美元符号
df_2016[‘Sales‘] = df_2016[‘Sales‘].str.replace(‘$‘,‘‘)
# # 查看异常值,均为字母(“undefined”)
# df_2016[df_2016[‘Sales‘].str.isalpha()]
# 替换异常值“undefined”为空白
# df_2016[‘Sales‘] = df_2016[‘Sales‘].str.replace(‘undefined‘,‘‘)
df_2016[‘Sales‘] = df_2016[‘Sales‘].str.replace(‘^[A-Za-z]+$‘,‘‘)
# 替换符号十亿美元“B”为空白,数字本身代表的就是十亿美元为单位
df_2016[‘Sales‘] = df_2016[‘Sales‘].str.replace(‘B‘,‘‘)
# 处理含有百万“M”为单位的数据,即以“M”结尾的数据
# 思路:
# (1)设定查找条件mask;
# (2)替换字符串“M”为空值
# (3)用pd.to_numeric()转换为数字
# (4)除以1000,转换为十亿美元,与其他行的数据一致
mask = df_2016[‘Sales‘].str.endswith(‘M‘)
df_2016.loc[mask, ‘Sales‘] = pd.to_numeric(df_2016.loc[mask, ‘Sales‘].str.replace(‘M‘, ‘‘))/1000
df_2016[‘Sales‘] = pd.to_numeric(df_2016[‘Sales‘])
print(‘the shape of DataFrame: ‘, df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)
用同样类似的方法处理其他列
可以看到,这个方法比第一种方法还是要方便很多。当然,这个方法针对DataFrame的每列数据都要进行相关的操作,如果列数多了,也还是比较繁琐的。
有没有更方便一点的方法呢。 答案是有的。
插播一条硬广:技术文章转发太多。文章来自微信公众号“Python数据之道”(ID:PyDataRoad)。
在Method-2的基础上,将处理方法写成更通用的数据处理函数,根据数据的结构,拓展更多的适用性,则可以比较方便的处理相关数据。
第一步还是加载数据,跟Method-1是一样的。
参考Method-2的处理过程,编写数据处理的自定义函数’pro_col’,并在Method-2的基础上拓展其他替换功能,使之适用于这四列数据(“Sales”,“Profits”,“Assets”,“Market_value”)。
函数编写的代码如下:
def pro_col(df, col):
# 替换相关字符串,如有更多的替换情形,可以自行添加
df[col] = df[col].str.replace(‘$‘,‘‘)
df[col] = df[col].str.replace(‘^[A-Za-z]+$‘,‘‘)
df[col] = df[col].str.replace(‘B‘,‘‘)
# 注意这里是‘-$‘,即以‘-‘结尾,而不是‘-‘,因为有负数
df[col] = df[col].str.replace(‘-$‘,‘‘)
df[col] = df[col].str.replace(‘,‘,‘‘)
# 处理含有百万“M”为单位的数据,即以“M”结尾的数据
# 思路:
# (1)设定查找条件mask;
# (2)替换字符串“M”为空值
# (3)用pd.to_numeric()转换为数字
# (4)除以1000,转换为十亿美元,与其他行的数据一致
mask = df[col].str.endswith(‘M‘)
df.loc[mask, col] = pd.to_numeric(df.loc[mask, col].str.replace(‘M‘,‘‘))/1000
# 将字符型的数字转换为数字类型
df[col] = pd.to_numeric(df[col])
return df
针对DataFrame的每列,应用该自定义函数,进行数据处理,得到需要的结果。
pro_col(df_2016, ‘Sales‘)
pro_col(df_2016, ‘Profits‘)
pro_col(df_2016, ‘Assets‘)
pro_col(df_2016, ‘Market_value‘)
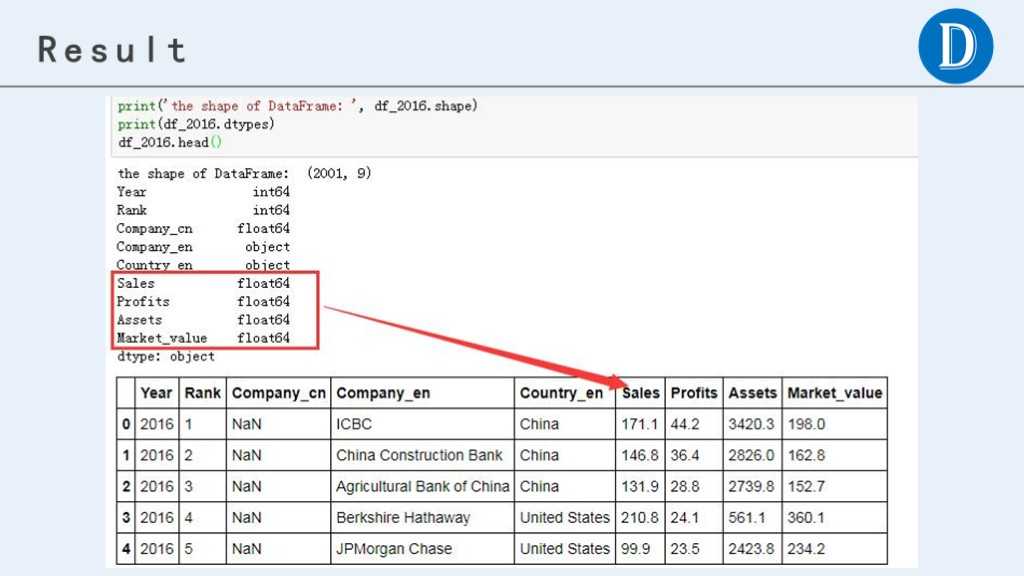
print(‘the shape of DataFrame: ‘, df_2016.shape)
print(df_2016.dtypes)
df_2016.head()
当然,如果DataFrame的列数特别多,可以用for循环,这样代码更简洁。代码如下:
cols = [‘Sales‘, ‘Profits‘, ‘Assets‘, ‘Market_value‘]
for col in cols:
pro_col(df_2016, col)
print(‘the shape of DataFrame: ‘, df_2016.shape)
print(df_2016.dtypes)
df_2016.head()
最终处理后,获得的数据结果如下:
标签:lis cu2 lnl 理解 思考 3.2 font gps ilo
原文地址:http://www.cnblogs.com/lemonbit/p/7147154.html