标签:logs slam adt 说明 9.png 之间 关联 意义 一个
通过传感器的运动参数来估计运动方程(位姿x),通过相机的照片来估计物体的位置(地图y),都是有噪声的。因为运动参数和照片都有噪声,所以需要进行优化。而过去卡尔曼滤波只关心当前的状态估计,而非线性优化则对所有时刻采集的数据进行状态估计,被认为优于卡尔曼滤波。由于要估计所有的采集数据,所以待估计变量就变成:
x={x1,…,xN,y1,….,yM}
所以对机器人状态的估计,就是求已知输入数据u(传感器参数)和观测数据z(图像像素)的条件下,计算状态x的条件概率分布(也就是根据u和z的数据事件好坏来估计x的优劣事件概率情况,这其中包含着关联,就好像已知一箱子里面有u和z个劣质的商品,求取出x个全是好商品的概率,同样的样本点,但是从不同角度分析可以得出不同的事件,不同的事件概率之间可以通过某些已知数据得出另些事件的概率,通过一系列函数式计算得出):
P(x|z, u)
在不考虑运动方程,只考虑观测照片z的情况下求x(这个过程也称SfM运动恢复),那么就变成P(x|z)。这种根据(已知求未知的情况)可以通过贝叶斯公式求解:P(x|z)=P(x)P(z|x)/P(z)。
贝叶斯法则的分母部分与带估计的状态x无关,所以忽略P(z),得P(x|z)=P(x)P(z|x)
P(x),也就是机器人的位姿在什么地方是不知道的,所以主要求P(z|x)也就是最大似然概率。
最大似然的概率用自然语言描述就是在什么状态下最有可能产生当前的照片结果!

P(x)是不知道的,所以: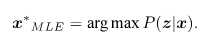
如何求最大似然估计呢?
回顾观测方程,我们知道z与x之间存在一个函数式:zk,j = h(yj, xk)+vk,j
现在要求x导致z出现的概率,要求z的最大概率,由于v是误差,符合高斯分布vk~N(0, Qk,j),所以z也符合高斯分布,即P(zi,k|xk, yj)=N(h(yj, xk), Qk,j)。
为了计算使它最大化的xk, yj,往往使用最小化负对数的方式,来求一个高斯分布的最大似然。
任意的高位高斯分布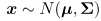 ,概率密度函数展开式:
,概率密度函数展开式:![]() ,对其取负对数:
,对其取负对数:
![]()
对原分布求最大化相当于对负对数求最小化,对上式x进行最小化时,第一项与x无关,略去,只需要最小化右侧的二次型,即![]()
我们发现,该是等价于最小化噪声项(即误差)的平方(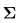 范数意义下)。因此对于所以对于所有的运动和观测
范数意义下)。因此对于所以对于所有的运动和观测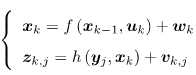 ,定义数据与估计值之间的误差:
,定义数据与估计值之间的误差:![]() ,误差的平方和:
,误差的平方和:![]()
从而得到了一个总体意义下的最小二乘问题,它的最优解等于状态的最大似然估计。
它的意义是说P(z,u|x)表明我们把估计的轨迹和地图(xk,yj)代入SLAM的运动、观测方程中时,它们并不会完美的成立。这时候怎么办呢?我们把状态的估计值进行微调,使得整体的误差下降一些。它一般会到极小值。这就是一个典型的非线性优化过程。
因为它非线性,所以df/dx有时候不好求,那么可以采用迭代法(有极值的话,那么它收敛,一步步逼近):

这样求导问题就变成了递归逼近问题,那么增量△xk如何确定?
这里介绍三种方法:
(1)一阶和二阶梯度法
将目标函数在x附近进行泰勒展开:![]()
其中J为||f(x)||2关于x的导数(雅克比矩阵),而H则是二阶导数(海塞(Hessian)矩阵)。我们可以选择一阶或二阶,增量不同。但都是为了求最小值,使函数值最小。
但最速下降法下降太快容易走出锯齿路线,反而增加了迭代次数。而牛顿法则需要计算目标函数的H矩阵,这在问题规模较大时非常困难,我们通常为了避免求解H。所以,接下来的两种最常用的方法:高斯牛顿法和列文伯格-马夸尔特方法。
(2)高斯牛顿法
将f(x)一阶展开:![]() (1)
(1)
这里J(x)为f(x)关于x的导数,实际上是一个m×n的矩阵,也是一个雅克比矩阵。现在要求△x,使得||f(x+△x)|| 达到最小。为求△ x,我们需要解一个线性的最小二乘问题:
![]()
这里注意变量是△ x,而非之前的x了。所以是线性函数,好求。为此,先展开目标函数的平方项:
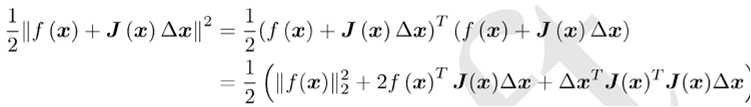
求导,令其等于0从而得到:
![]()
我们称为高斯牛顿方程。我们把左边的系数定义为H,右边定义为g,那么上式变为:
H △x=g
跟第(1)种方法对比可以发现,我们用J(x)TJ(x)代替H的求法,从而节省了计算量。所以高斯牛顿法跟牛顿法相比的优点就在于此,步骤列于下:


但是,还是有缺陷,就是它要求我们所用的近似H矩阵是可逆的(而且是正定的),但实际数据中计算得到的JTJ却只有半正定性。也就是说,在使用Gauss Newton方法时,可能出现JTJ为奇异矩阵或者病态(ill-condition)的情况,此时增量的稳定性较差,导致算法不收敛。更严重的是,就算我们假设H非奇异也非病态,如果我们求出来的步长△x太大,也会导致我们采用的局部近似(1)不够准确,这样一来我们甚至都无法保证它的迭代收敛,哪怕是让目标函数变得更大都是可能的。
所以,接下来的Levenberg-Marquadt方法加入了α,在△x确定了之后又找到了α,从而||f(x+α△x)||2达到最小,而不是直接令α=1。
(3)列文伯格-马夸尔特方法(Levenberg-Marquadt法)
由于Gauss-Newton方法中采用的近似二阶泰勒展开只能在展开点附近有较好的近似效果,所以我们很自然地想到应该给△x添加一个信赖区域(Trust Region),不能让它太大而使得近似不准确。非线性优化中有一系列这类方法,这类方法也被称之为信赖区域方法(Trust Region Method)。在信赖区域里边,我们认为近似是有效的;出了这个区域,近似可能会出问题。
那么如何确定这个信赖区域的范围呢?一个比较好的方法是根据我们的近似模型跟实际函数之间的差异来确定这个范围:如果差异小,我们就让范围尽可能大;如果差异大,我们就缩小这个近似范围。因此,考虑使用:
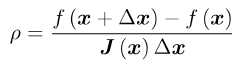
来判断泰勒近似是否够好。ρ的分子是实际函数下降的值,分母是近似模型下降的值。如果ρ接近于1,则近似是好的。如果ρ太小,说明实际减小的值远少于近似减小的值,则认为近似比较差,需要缩小近似范围。反之,如果ρ比较大,则说明实际下降的比预计的更大,我们可以放大近似范围。
于是,我们构建一个改良版的非线性优化框架,该框架会比Gauss Newton有更好的效果。
1. 给定初始值x0,以及初始化半径μ。
2. 对于第k次迭代,求解:
![]()
这里面的限制条件μ是信赖区域的半径,D将在后文说明。
3. 计算ρ。
4. 若ρ>3/4,则μ=2μ;
5. 若ρ<1/4,则μ=0.5μ;
6. 如果ρ大于某阈值,认为近似可行。令xk+1=xk+△xk。
7. 判断算法是否收敛。如不收敛则返回2,否则结束。
最后化简得到:
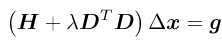
当λ比较小时,接近于牛顿高斯法,当λ比较大时,接近于最速下降法。L-M的求解方式,可在一定程度上避免线性方程组的系数矩阵的非奇异和病态问题,提供更稳定更准确的增量△x。
标签:logs slam adt 说明 9.png 之间 关联 意义 一个
原文地址:http://www.cnblogs.com/Jessica-jie/p/7153014.html
{kind=link}