标签:man 随机选择 速度 blank default advance cal 表达 near
solver : {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}, default: ‘liblinear’
Algorithm to use in the optimization problem.
- For small datasets, ‘liblinear’ is a good choice, whereas ‘sag’ is
faster for large ones.
- For multiclass problems, only ‘newton-cg’, ‘sag’ and ‘lbfgs’ handle
multinomial loss; ‘liblinear’ is limited to one-versus-rest schemes.
‘newton-cg’, ‘lbfgs’ and ‘sag’ only handle L2 penalty.
Note that ‘sag’ fast convergence is only guaranteed on features with approximately the same scale. You can preprocess the data with a scaler from sklearn.preprocessing. # 故,要归一化
首先,我们推导出一个监督学习问题的公式,并说明它是如何基于上下文和基本假设产生各种优化问题。
然后,我们讨论这些优化问题的一些显著特征,重点讨论 logistic 回归和深层神经网络训练的案例。
本文的后半部分重点介绍几种优化算法,
机器学习以统计学和计算机科学为基础,以数学优化方法为核心。
本文试图概述机器学习学习算法而打破三者之间的理解障碍。
Ref: LIBLINEAR -- A Library for Large Linear Classification
There are some large data for which with/without nonlinear mappings gives similar performances.
Without using kernels, one can quickly train a much larger set via a linear classifier. Document classification is one such application.
In the following example (20,242 instances and 47,236 features; available on LIBSVM data sets), the cross-validation time is significantly reduced by using LIBLINEAR:
% time libsvm-2.85/svm-train -c 4 -t 0 -e 0.1 -m 800 -v 5 rcv1_train.binary
Cross Validation Accuracy = 96.8136%
345.569s
% time liblinear-1.21/train -c 4 -e 0.1 -v 5 rcv1_train.binary
Cross Validation Accuracy = 97.0161%
2.944s // 感觉像直接带入公式计算的结果
Warning:While LIBLINEAR‘s default solver is very fast for document classification, it may be slow in other situations. See Appendix C of our SVM guide about using other solvers in LIBLINEAR.
Warning:If you are a beginner and your data sets are not large, you should consider LIBSVM first.
很多常见的机器学习模型的目标(比如最小二乘做线性回归、逻辑回归)都可以概括成以下这种一般形式:
其中 代表样本
的损失函数,
是模型的参数,
代表正则化项(用于控制模型复杂度或者模型稀疏度等等),有些时候这个正则化项是不平滑的,也就是说它可能不可导。
暂时先不考虑这个正则化项,只考虑样本上的损失,并且对符号做一点简化(),考虑下面这个优化目标:
这个形式非常简单,只要每个都可导,就可以用梯度下降法(Gradient Descent)迭代求解:
其中 表示第 t+1 次更新后的参数。
劣势:那就是每次需要求解所有样本的梯度,样本数多的时候,导致计算量大增,所以实际生产环境中,往往采用随机梯度下降算法(Stochastic Gradient Descent),一般简写做SGD。
SGD每次迭代的时候均匀随机得选择mini-batch (even少到一个样本) 做更新:
优势:就是可以减少每次更新的计算代价;
劣势:收敛速度不如梯度下降,也就是说为了达到同样的精度,SGD需要的总迭代次数要大于梯度下降。
但是,单次迭代的计算量要小得多。从收敛速度分析上看,
- SGD能够在目标函数强凸并且递减步长的情况下做到
的次线性收敛(sublinear convergence),
- 梯度下降则可以在目标函数强凸的情况下做到
(
) 的线性收敛(linear convergence)。
总结起来就是,如果想快速得到一个可以勉强接受的解,SGD比梯度下降更加合适,但是如果想得到一个精确度高的解,应当选择梯度下降。
SGD后来后来也衍生出了非常多的变种,尤其是一类分析regret的online算法,包括Adagrad、Dual Averaging、FTRL等。
但是,始终学术界对于SGD还有一种期待,就是:是否可以把SGD做到和梯度下降一样的线性收敛。直到2012和2013年,SAG[1]与SVRG[2]算法发表在NIPS上,成为近几年SGD类算法的最大突破。
SAG算法:
具体得说,更新的项来自于用新的梯度
替换掉
中的旧梯度
,这也就是
表达的意思。
如此,每次更新的时候仅仅需要计算一个样本的梯度,而不是所有样本的梯度。
计算开销与SGD无异,但是内存开销要大得多。
Roux, Nicolas L., Mark Schmidt, and Francis R. Bach. "A stochastic gradient method with an exponential convergence rate for finite training sets." Advances in Neural Information Processing Systems. 2012.
中已经证明SAG是一种线性收敛算法,这个速度远比SGD快。
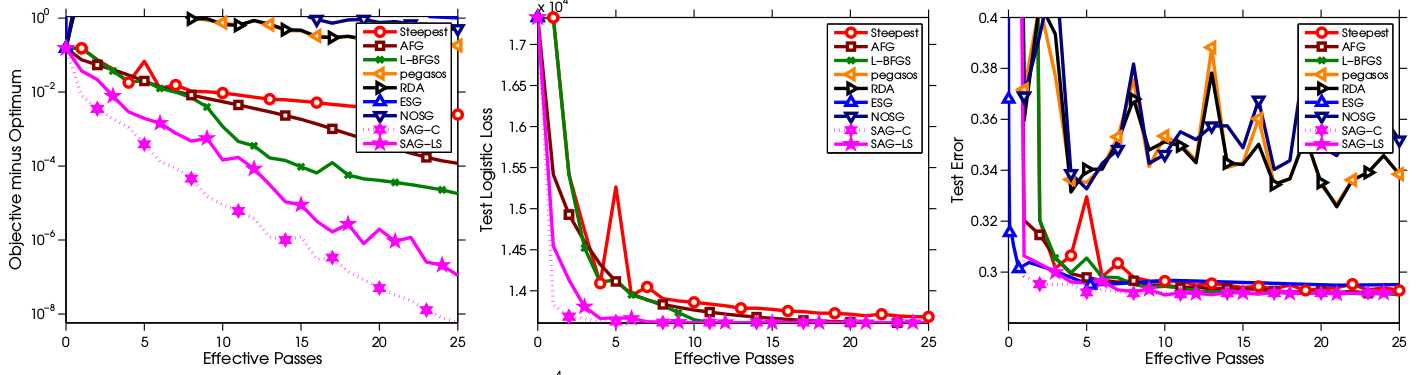
实验目标函数是l2-regularized logistic regression,
注意左一的纵坐标是对数坐标,一般衡量优化算法的速度都会采用对数坐标,因为在对数坐标中可以明显看出一个算法是线性收敛(近乎直线下降)还是次线性收敛(大体是一条向下凸的曲线)。
可以看出SAG是一种线性收敛算法,且相对于其他参与比较的算法有很大的优势。
SVRG的算法思路是:
相对于SAG来说,不需要在内存中为每个样本都维护一个梯度,也就是说节省了内存资源。
此外,SVRG中提出了一个非常重要的概念叫做 variance reduction(方差缩减),这个概念需要联系SGD的收敛性分析来理解,在SGD的收敛性分析中需要假设样本梯度的的方差是有常数上界的,然而正是因为这个常数上界导致了SGD无法线性收敛,
因此SVRG的收敛性分析中利用这种特殊的更新项来让方差有一个可以不断减少的上界,因此也就做到了线性收敛,这一点就是SVRG的核心,SAG的策略其实也与此类似(虽然证明过程不同)。
SVRG显然是线性收敛算法,相对于SGD有非常大的优势,和SDCA具备同阶的速度。
[NN] Stochastic Gradient Descent - SAG & SVRG
标签:man 随机选择 速度 blank default advance cal 表达 near
原文地址:http://www.cnblogs.com/jesse123/p/7157099.html