标签:地方 under 数据 ica 刷新 evel 关系图 too 处理器
perf
perf
Performance analysis tools for Linux.
Performance counters for Linux are a new kernel-based subsystem that provide a framework for all things
performance analysis. It covers hardware level (CPU/PMU, Performance Monitoring Unit) features and
software features (software counters, tracepoints) as well.
Perf是内置于Linux内核源码树中的性能剖析(profiling)工具。
它基于事件采样原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析。
常用于性能瓶颈的查找与热点代码的定位。
CPU周期(cpu-cycles)是默认的性能事件,所谓的CPU周期是指CPU所能识别的最小时间单元,通常为亿分之几秒,
是CPU执行最简单的指令时所需要的时间,例如读取寄存器中的内容,也叫做clock tick。
Perf是一个包含22种子工具的工具集,以下是最常用的5种:
perf-list
perf-stat
perf-top
perf-record
perf-report
perf-list
Perf-list用来查看perf所支持的性能事件,有软件的也有硬件的。
List all symbolic event types.
perf list [hw | sw | cache | tracepoint | event_glob]
(1) 性能事件的分布
hw:Hardware event,9个
sw:Software event,9个
cache:Hardware cache event,26个
tracepoint:Tracepoint event,775个
sw实际上是内核的计数器,与硬件无关。
hw和cache是CPU架构相关的,依赖于具体硬件。
tracepoint是基于内核的ftrace,主线2.6.3x以上的内核版本才支持。
(2) 指定性能事件(以它的属性)
-e <event> : u // userspace
-e <event> : k // kernel
-e <event> : h // hypervisor
-e <event> : G // guest counting (in KVM guests)
-e <event> : H // host counting (not in KVM guests)
(3) 使用例子
显示内核和模块中,消耗最多CPU周期的函数:
# perf top -e cycles:k
显示分配高速缓存最多的函数:
# perf top -e kmem:kmem_cache_alloc
perf-top
对于一个指定的性能事件(默认是CPU周期),显示消耗最多的函数或指令。
System profiling tool.
Generates and displays a performance counter profile in real time.
perf top [-e <EVENT> | --event=EVENT] [<options>]
perf top主要用于实时分析各个函数在某个性能事件上的热度,能够快速的定位热点函数,包括应用程序函数、
模块函数与内核函数,甚至能够定位到热点指令。默认的性能事件为cpu cycles。
(1) 输出格式
# perf top
第一列:符号引发的性能事件的比例,默认指占用的cpu周期比例。
第二列:符号所在的DSO(Dynamic Shared Object),可以是应用程序、内核、动态链接库、模块。
第三列:DSO的类型。[.]表示此符号属于用户态的ELF文件,包括可执行文件与动态链接库)。[k]表述此符号属于内核或模块。
第四列:符号名。有些符号不能解析为函数名,只能用地址表示。
(2) 常用交互命令
h:显示帮助
UP/DOWN/PGUP/PGDN/SPACE:上下和翻页。
a:annotate current symbol,注解当前符号。能够给出汇编语言的注解,给出各条指令的采样率。
d:过滤掉所有不属于此DSO的符号。非常方便查看同一类别的符号。
P:将当前信息保存到perf.hist.N中。
(3) 常用命令行参数
-e <event>:指明要分析的性能事件。
-p <pid>:Profile events on existing Process ID (comma sperated list). 仅分析目标进程及其创建的线程。
-k <path>:Path to vmlinux. Required for annotation functionality. 带符号表的内核映像所在的路径。
-K:不显示属于内核或模块的符号。
-U:不显示属于用户态程序的符号。
-d <n>:界面的刷新周期,默认为2s,因为perf top默认每2s从mmap的内存区域读取一次性能数据。
-G:得到函数的调用关系图。
perf top -G [fractal],路径概率为相对值,加起来为100%,调用顺序为从下往上。
perf top -G graph,路径概率为绝对值,加起来为该函数的热度。
(4) 使用例子
# perf top // 默认配置
# perf top -G // 得到调用关系图
# perf top -e cycles // 指定性能事件
# perf top -p 23015,32476 // 查看这两个进程的cpu cycles使用情况
# perf top -s comm,pid,symbol // 显示调用symbol的进程名和进程号
# perf top --comms nginx,top // 仅显示属于指定进程的符号
# perf top --symbols kfree // 仅显示指定的符号
perf-stat
用于分析指定程序的性能概况。
Run a command and gather performance counter statistics.
perf stat [-e <EVENT> | --event=EVENT] [-a] <command>
perf stat [-e <EVENT> | --event=EVENT] [-a] - <command> [<options>]
(1) 输出格式
# perf stat ls
输出包括ls的执行时间,以及10个性能事件的统计。
task-clock:任务真正占用的处理器时间,单位为ms。CPUs utilized = task-clock / time elapsed,CPU的占用率。
context-switches:上下文的切换次数。
CPU-migrations:处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU
迁移到另一个CPU。
page-faults:缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内
存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常。另外TLB不命中,页面访问权限不匹配
等情况也会触发缺页异常。
cycles:消耗的处理器周期数。如果把被ls使用的cpu cycles看成是一个处理器的,那么它的主频为2.486GHz。
可以用cycles / task-clock算出。
stalled-cycles-frontend:略过。
stalled-cycles-backend:略过。
instructions:执行了多少条指令。IPC为平均每个cpu cycle执行了多少条指令。
branches:遇到的分支指令数。branch-misses是预测错误的分支指令数。
(2) 常用参数
-p:stat events on existing process id (comma separated list). 仅分析目标进程及其创建的线程。
-a:system-wide collection from all CPUs. 从所有CPU上收集性能数据。
-r:repeat command and print average + stddev (max: 100). 重复执行命令求平均。
-C:Count only on the list of CPUs provided (comma separated list), 从指定CPU上收集性能数据。
-v:be more verbose (show counter open errors, etc), 显示更多性能数据。
-n:null run - don‘t start any counters,只显示任务的执行时间 。
-x SEP:指定输出列的分隔符。
-o file:指定输出文件,--append指定追加模式。
--pre <cmd>:执行目标程序前先执行的程序。
--post <cmd>:执行目标程序后再执行的程序。
(3) 使用例子
执行10次程序,给出标准偏差与期望的比值:
# perf stat -r 10 ls > /dev/null
显示更详细的信息:
# perf stat -v ls > /dev/null
只显示任务执行时间,不显示性能计数器:
# perf stat -n ls > /dev/null
单独给出每个CPU上的信息:
# perf stat -a -A ls > /dev/null
ls命令执行了多少次系统调用:
# perf stat -e syscalls:sys_enter ls
perf-record
收集采样信息,并将其记录在数据文件中。
随后可以通过其它工具(perf-report)对数据文件进行分析,结果类似于perf-top的。
Run a command and record its profile into perf.data.
This command runs a command and gathers a performance counter profile from it, into perf.data,
without displaying anything. This file can then be inspected later on, using perf report.
(1) 常用参数
-e:Select the PMU event.
-a:System-wide collection from all CPUs.
-p:Record events on existing process ID (comma separated list).
-A:Append to the output file to do incremental profiling.
-f:Overwrite existing data file.
-o:Output file name.
-g:Do call-graph (stack chain/backtrace) recording.
-C:Collect samples only on the list of CPUs provided.
(2) 使用例子
记录nginx进程的性能数据:
# perf record -p `pgrep -d ‘,‘ nginx`
记录执行ls时的性能数据:
# perf record ls -g
记录执行ls时的系统调用,可以知道哪些系统调用最频繁:
# perf record -e syscalls:sys_enter ls
perf-report
读取perf record创建的数据文件,并给出热点分析结果。
Read perf.data (created by perf record) and display the profile.
This command displays the performance counter profile information recorded via perf record.
(1) 常用参数
-i:Input file name. (default: perf.data)
(2) 使用例子
# perf report -i perf.data.2
More
除了以上5个常用工具外,还有一些适用于较特殊场景的工具, 比如内核锁、slab分配器、调度器,
也支持自定义探测点。
perf-lock
内核锁的性能分析。
Analyze lock events.
perf lock {record | report | script | info}
需要编译选项的支持:CONFIG_LOCKDEP、CONFIG_LOCK_STAT。
CONFIG_LOCKDEP defines acquired and release events.
CONFIG_LOCK_STAT defines contended and acquired lock events.
(1) 常用选项
-i <file>:输入文件
-k <value>:sorting key,默认为acquired,还可以按contended、wait_total、wait_max和wait_min来排序。
(2) 使用例子
# perf lock record ls // 记录
# perf lock report // 报告
(3) 输出格式
Name:内核锁的名字。
aquired:该锁被直接获得的次数,因为没有其它内核路径占用该锁,此时不用等待。
contended:该锁等待后获得的次数,此时被其它内核路径占用,需要等待。
total wait:为了获得该锁,总共的等待时间。
max wait:为了获得该锁,最大的等待时间。
min wait:为了获得该锁,最小的等待时间。
最后还有一个Summary:
perf-kmem
slab分配器的性能分析。
Tool to trace/measure kernel memory(slab) properties.
perf kmem {record | stat} [<options>]
(1) 常用选项
--i <file>:输入文件
--caller:show per-callsite statistics,显示内核中调用kmalloc和kfree的地方。
--alloc:show per-allocation statistics,显示分配的内存地址。
-l <num>:print n lines only,只显示num行。
-s <key[,key2...]>:sort the output (default: frag,hit,bytes)
(2) 使用例子
# perf kmem record ls // 记录
# perf kmem stat --caller --alloc -l 20 // 报告
(3) 输出格式
Callsite:内核代码中调用kmalloc和kfree的地方。
Total_alloc/Per:总共分配的内存大小,平均每次分配的内存大小。
Total_req/Per:总共请求的内存大小,平均每次请求的内存大小。
Hit:调用的次数。
Ping-pong:kmalloc和kfree不被同一个CPU执行时的次数,这会导致cache效率降低。
Frag:碎片所占的百分比,碎片 = 分配的内存 - 请求的内存,这部分是浪费的。
有使用--alloc选项,还会看到Alloc Ptr,即所分配内存的地址。
最后还有一个Summary:
probe-sched
调度模块分析。
trace/measure scheduler properties (latencies)
perf sched {record | latency | map | replay | script}
(1) 使用例子
# perf sched record sleep 10 // perf sched record <command>
# perf report latency --sort max
(2) 输出格式
TASK:进程名和pid。
Runtime:实际的运行时间。
Switches:进程切换的次数。
Average delay:平均的调度延迟。
Maximum delay:最大的调度延迟。
Maximum delay at:最大调度延迟发生的时刻。
perf-probe
可以自定义探测点。
Define new dynamic tracepoints.
使用例子
(1) Display which lines in schedule() can be probed
# perf probe --line schedule
前面有行号的可以探测,没有行号的就不行了。
(2) Add a probe on schedule() function 12th line.
# perf probe -a schedule:12
在schedule函数的12处增加一个探测点。
Reference
[1]. Linux的系统级性能剖析工具系列,by 承刚
[2]. http://www.ibm.com/developerworks/cn/linux/l-cn-perf1/
[3]. http://www.ibm.com/developerworks/cn/linux/l-cn-perf2/
[4]. https://perf.wiki.kernel.org/index.php/Tutorial
Perf主要用途:
1. 基于时间的性能分析
包括了可以再程序热点查找(最频繁执行的热点代码);在周期性中断应用采样;函数处理器利用。
2. 基于事件的性能分析
针对时间无关的性能指标(哪个函数/指令触发了最多的cache missing哪个程序使用的系统调用数最多等)
性能计数器(ISR记录当前进程的采样信息:PC,PID,TID性能计数器积累到一定数值(采样周期)时触发中断);热点进程热点函数热点指令
Perf跟踪性能事件,可分为以下三种:

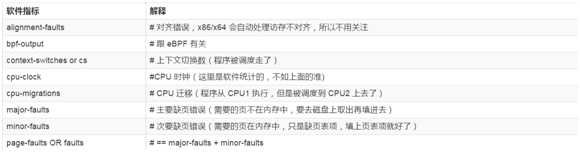
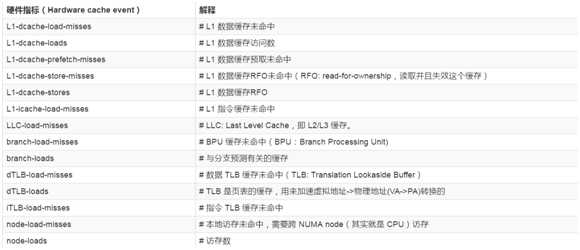
【实战:打破困境直达核心】
了解perf的功能和独特优势之后,让我们一起回归到本文开篇的情境中,让Perf施展一下自己拳脚吧。
(1)perf top打头阵–实时显示系统/进程的性能统计信息

先用 perf top看看CPU实时热点情况,对资源的整体消耗有一个基本了解,并对照源码做一个基本定位。
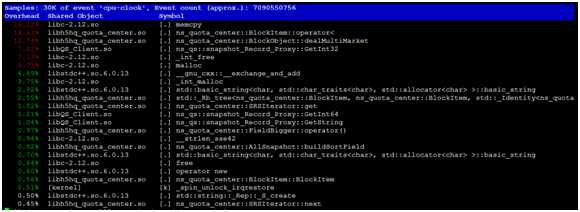
选择 Annotate,找出热点(可以精确到 CPU 指令):
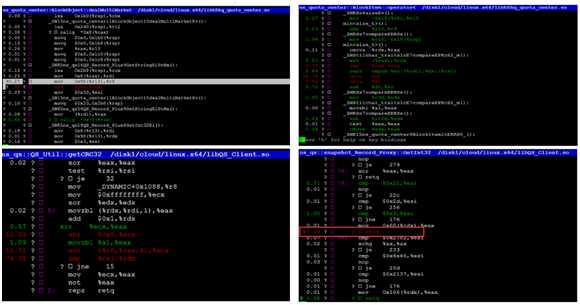
从跟踪情况可以看到CPU主要消耗在,MOV ,CMP,SETB,RETQ 等指令上面,而尤其CMP和RETQ指令在链表功能中使用时资源耗费最多,基于该处的怀疑,我们用 Perf stat 来对程序/线程进行分析。
(2) perf stat来统计–用于分析指定程序/线程的性能概况


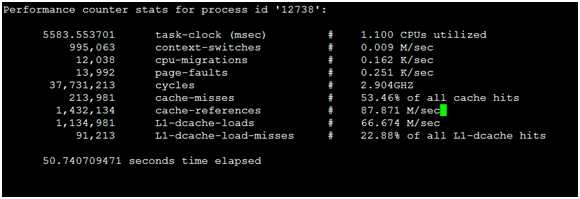
▲perf stat 输出解读如下
? task-clock
用于执行程序的CPU时间,单位是ms(毫秒)。第二列中的CPU utillized则是指这个进程在运行perf的这段时间内的CPU利用率,该数值是由task-clock除以最后一行的time elapsed再除以1000得出的。
? context-switches
进程切换次数,记录了程序运行过程中发生了多少次进程切换,应该避免频繁的进程切换。
? cpu-migrations
程序在运行过程中发生的CPU迁移次数,即被调度器从一个CPU转移到另外一个CPU上运行。
? page-faults
缺页。指当内存访问时先根据进程虚拟地址空间中的虚拟地址通过MMU查找该内存页在物理内存的映射,没有找到该映射,则发生缺页,然后通过CPU中断调用处理函数,从物理内存中读取。
? Cycles
处理器时钟,一条机器指令可能需要多个 cycles。
? Cache-references
cache 命中的次数。
? Cache-misses
cache 失效的次数。
? L1-dcache-load-missed
一级数据缓存读取失败次数。
? L1-dcache-loads
一级数据缓存读取次数。
从 Perf stat 输出数据可以看到CPU的迁移次数较多, 程序上下文切换比较频繁,Cache命中率不是很理想,内存缺页也比较多 ,对照源码定位到本次问题是因为为保证数据一致性在获取数据时增加了CRC码校验过程,只有当CRC码校验正确的情况下才进行后续工作,该处单线程处理,且有锁操作,导致程序频繁上下文切换、内存缺页严重。
当问题已经被准确找到,你会发现修改过程其实并不困难。下面我们再将解放方案做的更完善一下,对跟踪数据进行图形化,让大家更直观的体会一下程序。
(3) FlameGraph来出图
首先我们用 perf record 获取基础数据,perf record 命令主要是用来记录一段时间内系统/进程的性能事件,如下:
我们首先执行 perf record -a -g -p ‘PID’ --sleep 60 来收集数据,其次我们用 perf script 调用扩展脚本生成可跟踪信息。
总的来说,perf script 可以用来做以下两件事情:
• 查看perf的数据文件(perf.data)
• 执行基于python/perl的扩展功能(需要python环境)
我们执行FlameGraph的扩展脚本perf script |FlameGraph-master/stackcollapse-perf.pl
最后用 FlameGraph 生成火焰图,Flame Graph是Brendan Gregg开发的一个小工具能够将perf等剖析工具采到的call stack数据转换为svg图执行** FlameGraph-master/flamegraph.pl > flame-h5.svg** 生成火焰图
结果如下:
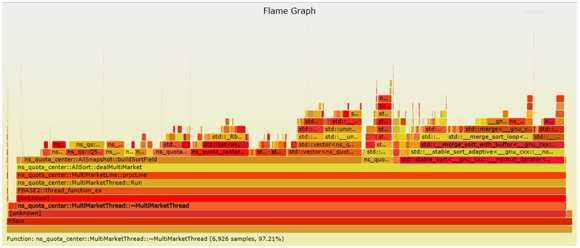
通过此图,相信你能够直观高效地判断出到底是谁消耗了您珍贵的服务器资源,找准根源,困境将不攻自破。
【学无止境】
除了Perf外,还有 SystemTap,google-perftools,DTrace 我这里统称性能跟踪优化四大帅),如果您能熟练掌握各个工具的特点及使用方法,那么90%的性能问题在您这里将不再是问题。
1. SystemTap
systemtap 是利用Kprobe 提供的API来实现动态地监控和跟踪运行中的Linux内核的工具,相比Kprobe,systemtap更加简单,提供给用户简单的命令行接口,以及编写内核指令的脚本语言。
Systemtap 工作原理是通过将脚本语句翻译成C语句,编译成内核模块。模块加载之后,将所有探测的事件以钩子的方式挂到内核上,当任何处理器上的某个事件发生时,相应钩子上句柄就会被执行。最后,当systemtap会话结束之后,钩子从内核上取下,移除模块。
2. google-perftools
google-perftools 是一款针对 C/C++ 程序的性能分析工具,使用该工具可以对 CPU 时间片、内存使用情况进行“画像”,通过它所输出的结果,我们可以对程序中各个函数(得到函数之间的调用关系)耗时情况一目了然.最后可以生成类似下面的gif图片,够清晰炫酷吧。
3. DTrace
DTrace(全称Dynamic Tracing),也称为动态跟踪,是由 Sun™ 开发的一个用来在生产和试验性生产系统上找出系统瓶颈的工具,可以对内核(kernel)和用户应用程序(user application)进行动态跟踪并且对系统运行不构成任何危险的技术。在任何情况下它都不是一个调试工具, 而是一个实时系统分析寻找出性能及其他问题的工具。 DTrace 是个特别好的分析工具,带有大量的帮助诊断系统问题的特性。还可以使用预先写好的脚本利用它的功能。 用户也可以通过使用 DTrace D 语言创建他们自己定制的分析工具,以满足特定的需求。
标签:地方 under 数据 ica 刷新 evel 关系图 too 处理器
原文地址:http://www.cnblogs.com/Oliver.net/p/7160141.html