标签:desire abi input click 保存 main 购物 locate 界面
做风险控制和个人征信,需要做数据挖掘,第一步就是要爬到消费记录,当然还有很多其他项包括收货地址 宝贝收藏 快速退款额度 芝麻信用 绑定的手机等等,先要爬到数据才能分析。
淘宝直接请求登录接口不可行,不知道post参数加密规则,(大公司安全就是做得好),用selenium操作浏览器来登录得到driver的cookie,然后requests携带cookie去爬订单。如果全部都由selenium爬取无疑很慢,所以selenium负责登录就行。
上代码。
#coding=utf-8 import time,random,requests,json from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.webdriver.common.desired_capabilities import DesiredCapabilities class Taobao(object): def __init__(self,name,password): self.name=name self.password=password self.login_url=‘https://login.taobao.com/member/login.jhtml?redirectURL=https%3A%2F%2Fwww.taobao.com%2F‘ self.order_url=‘https://buyertrade.taobao.com/trade/itemlist/asyncBought.htm?action=itemlist/BoughtQueryAction&event_submit_do_query=1&_input_charset=utf8‘ self.num=0 self.cost=0 def login(self):
###如果用phantomjs浏览器就用这个 # dcap = dict(DesiredCapabilities.PHANTOMJS) # dcap["phantomjs.page.settings.userAgent"] = (‘Mozilla/5.0(WindowsNT6.1;WOW64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/59.0.3071.115Safari/537.36x-requested-with:XMLHttpRequest‘)#(random.choice(agents)) # dcap["phantomjs.page.settings.loadImages"] = True # driver = webdriver.PhantomJS(executable_path=‘C:\\Python27\\phantomjs.exe‘,desired_capabilities=dcap) driver=webdriver.Chrome() driver.get(self.login_url) driver.find_element_by_id(‘J_Quick2Static‘).click() WebDriverWait(driver, 30, 0.5).until(EC.presence_of_element_located((By.ID, ‘TPL_username_1‘))) driver.find_element_by_id(‘TPL_username_1‘).send_keys(self.name) driver.save_screenshot(‘1.jpg‘) ##用phantomjs无界面浏览器最好需要截图 driver.find_element_by_id(‘TPL_password_1‘).send_keys(self.password) driver.save_screenshot(‘2.jpg‘) driver.find_element_by_id(‘J_SubmitStatic‘).click() time.sleep(10) driver.save_screenshot(‘3.jpg‘) self.cookies={} for dictx in driver.get_cookies(): self.cookies[dictx[‘name‘]]=dictx[‘value‘] driver.quit() def get_orders(self,p,flag): if flag==0: self.login() print self.cookies datax={‘pageNum‘:p+1, ‘pageSize‘:15, ‘prePageNo‘:p, } header = {‘origin‘: ‘https://buyertrade.taobao.com‘, ###origin和refere一定需要,否则会请求不到订单数据 ‘referer‘:‘https://buyertrade.taobao.com/trade/itemlist/list_bought_items.htm‘, ‘user-agent‘:‘Mozilla/5.0(WindowsNT6.1;WOW64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/59.0.3071.115Safari/537.36x-requested-with:XMLHttpRequest‘, #‘cookie‘:‘miid=387872062667523128; thw=cn;xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.....‘, ##如果不用浏览器登录,可以在headrs中携带字符串形式的cookie } resp=requests.post(self.order_url,data=datax,cookies=self.cookies,headers=header) #resp=requests.post(self.order_url,data=datax,headers=header) #print resp.content.decode(‘gbk‘) orders_dictx = json.loads(resp.content.decode(‘gbk‘)) pages=orders_dictx[‘page‘][‘totalPage‘] for order in orders_dictx[‘mainOrders‘]: self.num+=1 self.cost+=float(order[‘payInfo‘][‘actualFee‘]) print self.num,‘ ‘,order[‘subOrders‘][0][‘itemInfo‘][‘title‘],‘ 价格是: ‘,order[‘payInfo‘][‘actualFee‘],‘元 交易状态是:‘,order[‘statusInfo‘][‘text‘],self.cost if flag==0: for p in range(1,pages+1): self.get_orders(p,1) if __name__=="__main__": pass tb=Taobao(‘369xxxx@qq.com‘,‘123xxxxxxxx‘) tb.get_orders(0,0)
运行后爬到的订单。
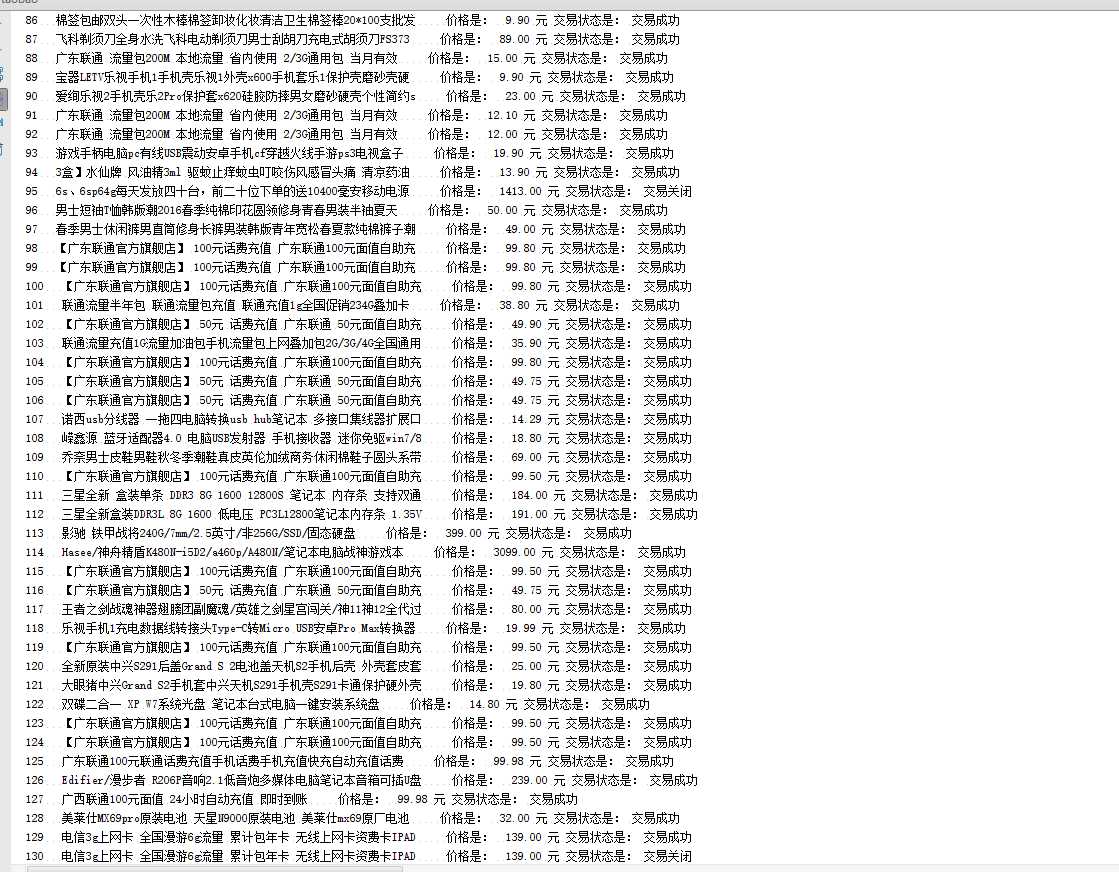
要爬很多项,已购买宝贝只是其中之一,账号 密码要做成做接口传过来触发爬虫。然后保存各项数据,做数据挖掘用。
根据统计,我在淘宝购物了205次,花费了28613.53元。
标签:desire abi input click 保存 main 购物 locate 界面
原文地址:http://www.cnblogs.com/ydf0509/p/7164026.html