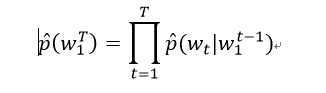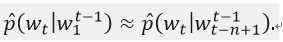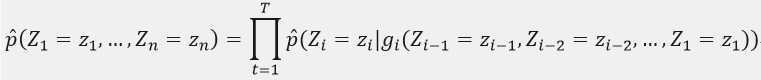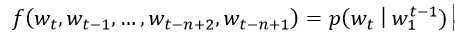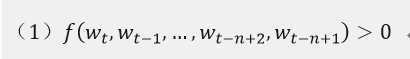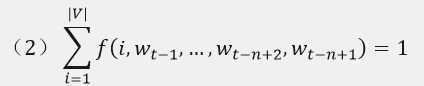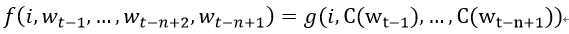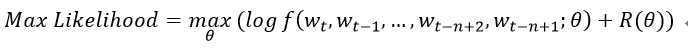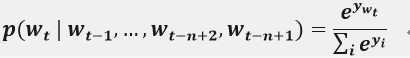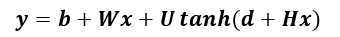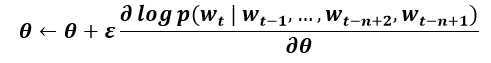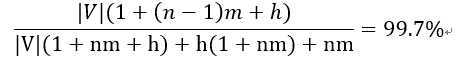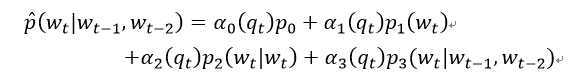标签:style blog http io 使用 strong ar 数据 2014
A Neural Probabilistic Language Model,这篇论文是Begio等人在2003年发表的,可以说是词表示的鼻祖。在这里给出简要的译文
A Neural Probabilistic Language Model
一个神经概率语言模型
摘 要
统计语言模型的一个目标是学习一种语言的单词序列的联合概率函数。因为维数灾难,这是其本质难点:将被模型测试的单词序列很可能是与在训练中见过的所有单词的序列都不相同。传统的但非常成功的基于n-gram的方法通过将出现在训练集很短的重叠序列连接得到泛化。为了解决维数灾难的问题,我们提出学习词的分布式表示,这种方法允许每一个训练语句给模型提供关于语义相邻句子的指数级别数量的信息。根据刚才的描述,该模型同时学习(1)每个词的分布式表示与(2)词序列的概率函数。模型可以得到泛化是因为一个从未出现的词序列,如果它是由与它相似的词(在其附近的一个代表性的意义上)组成过已经出现的句子的话,那么它获得较高的概率。在合理的时间内训练这样的大型模型(以百万计的参数)本身就是一个显著的挑战。我们报告基于神经网络的概率函数的实验,显示出在两个文本语料库,该方法显著改进了最先进的n-gram模型,而且该方法允许利用较长的上下文优势。
关键词:统计语言模型, 人工神经网络, 分布式表示, 维数灾难
使语言建模和其他学习问题困难的一个根本的问题是维数灾难。当一个人想对很多离散随机变量(如在句子中的单词或者数据挖掘任务中的离散分布)建立联合分布模型时,这个问题尤其明显。例如,如果一个人想要对自然语言中单词表大小为100000的10个相连的词建立联合分布模型,将会有100 00010 − 1 = 1050 – 1个自由参数。当对连续变量建立模型时,我们更容易得到泛化(如光滑的类的函数像多层神经网络或Gaussian混合模型),因为要学习的函数可以被期望将有一些LO- CAL的平滑性。对于离散的空间,泛化结构并不明显:这些离散随机变量的任何变化可能对要估计的函数的值产生极大的影响,并且当每个离散的变量取值范围很大时,大多数观察到的对象在汉明距离上是几乎无穷远的。
一个统计语言模型可以表示成给定前面词后面一个词出现的条件概率:
其中,wt代表第t个词,把子序列写成wij。这种语言模型已经被发现在很多自然语言处理领域有作用,例如语音识别,语言翻译,信息检索。统计语言模型性能的提升因此能够对这些应用有显著的影响。
在建立统计语言模型时,一个可以考虑的降低模型困难的方法是词序列中更靠近的词更加具有依赖性。因此,n-gram模型建立了一个给定前n-1个词,第n个词的条件概率表示:
我们只考虑在训练集中出现的连续词的组合,或者出现足够频繁的词。当在语料中未见过的n个词的新组合出现时,将发生什么?我们不想为它们分配为0的概率,因为这样的组合确实有可能发生。一个简单的解决办法是使用更小的上下文,即使用tri-gram或者平滑后的tri-gram。本质上来说,一个新的词序列是通过“粘合”非常短的重叠的在训练语料中出现频繁的字片段组成。获得下一个片段的概率的规则是隐式的回退或者打折后的n-gram算法。研究者使用典型的n=3的tri-gram,并且获得了世界领先水平的结果。显然的是直接出现在词前面的序列携带的信息要比仅仅之前的一小段序列携带的信息多。我们在本论文中提出的方法至少在两个特点上面显著的提高了上面的问题。第一点,上面的方法没有考虑超过1或2个词的上下文;第二点,上面的方法没有考虑词与词之间的相似性。例如,在语料库中已经观测到了序列“The cat is walking in the bedroom”,可以帮助我们生成序列“A dog was running in a room”,因为“dog”和“cat”有相似的语义和语法角色。
有很多被提出来的方法可以解决这两个问题,我们在1.2节给出简洁的解释。我们首先将讨论被提出方法的基本思想。更加形式化的介绍将在2节中给出。这些思想的实现使用的是同享参数的多层神经网络。这篇论文的另一个贡献是介绍了对大量数据训练如此大的神经网络的高效方法。最后,一个重要的贡献是说明了训练如此大规模的模型是昂贵但是值得的。
这片论文的很多运算使用矩阵符号,使用小写字母v代表列向量,v’代表它的转置,Aj表示矩阵A的第j行,x.y代表x’y。
1.1 使用分布式表示解决维数灾难
简单来讲,本方法的思想可以被概括成以下3个步骤:
1. 为在词表中的每一个词分配一个分布式的词特征向量
2. 词序列中出现的词的特征向量表示的词序列的联合概率函数
3.学习词特征向量和概率函数的参数
词特征向量代表了词的不同的方面:每个词关联向量空间的一个点。特征的数量远远小于词表的大小。概率函数被表达成给定前面的词后面一个词的条件概率的乘积(例如,在实验中,使用多层神经网络,给定前面的词预测下一个词)。这个函数有一些参数,可以通过迭代的方式调整这些参数来最大化对数似然函数。这些与词关联的特征向量可以被学习得当,但是他们可以使用先验的语义特征知识来初始化。
为什么这样有效?在前面的例子中,如果我们知道 “ dog”和“cat”扮演相似的角色(语义的或者句法的),类似的对于(the,a),(bedroom,room),(is,was),(running,walking),我们自然地可以由
The cat is walking in the bedroom
生成
A dog was running in a room
或者
The cat is runing in a room
A dog is walking in a bedroom
The dog was walking in the room
…
或者更多的其他组合。在本模型中,这些可以被生成因为相似的词被期望有相似的特征向量,也因为概率函数是一个这些特征值的平滑的函数,在特征中的小的改变将在概率中产生小的变化。因此,上述这些句子其中一个在语料库中的出现,将增加这些句子的概率。
1.2 与前面工作的关系
使用神经网络对高维离散分布建模已经被发现可以有效的学习其联合概率。在这个模型中,联合概率被分解为条件概率的乘积
其中,g(x)是被左到右结构神经网络表示的函数。第i个输出块gi计算表达给定之前Z,Zi的条件概率的参数。在四个UCI数据集上的实验证明了这个方法可以工作的很好。这里我们必须处理可变长度的数据,像句子,因此上面的方法必须被变形。
2. 一个神经模型
训练集是一个词序列w1,…,wT,其中wt∈V,词表V是一个大但是有限的集合。模型的目标是要学到一个好的函数来估计条件概率:
需要满足的约束为:
其中,wt表示词序列的第t个词;V表示词表,|V|表示词表的大小。通过条件概率的成绩可以获得词序列的联合概率。
我们把函数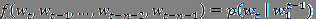 分解为两个部分:
分解为两个部分:
1. 一个映射C,从词表中的任意元素i到实向量C(i)∈Rm。它代表关联词表中词的分布特征向量。在实践中,C被表示成一个|V|×m的自由参数矩阵。
2. 词上的概率函数,用C表达:一个函数g,从输入序列的词的上下文特征向量,(C(wt-n+1),…,C(wt-1)),到词表中下一个词i的条件概率分布。g的输出是一个向量,向量的第i个元素估计概率
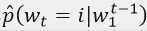 ,如下图
,如下图
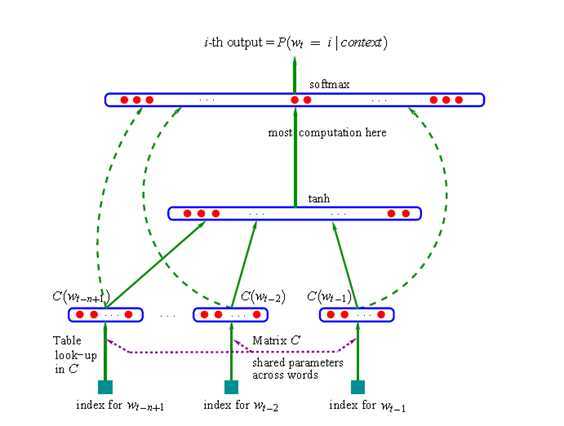
图1 神经网络语言模型结构图
函数f是这两个映射C和g的组合。这两个映射都关联一些参数。映射C的参数就是特征向量本身,被表示成一个|V|×m的矩阵C,C的第i行是词i的特征向量。函数g可以被一个前馈神经网络或者卷积神经网络实现或者其他的参数化函数实现。
训练的被实现为寻找θ使得训练数据的对数似然函数最大化
其中θ为参数,R(θ)为正则项,例如,在我们的实验中,R是一个权重的惩罚,仅仅是神经网络的权重和矩阵C。
在上述的模型中,自由参数的数量是词表V大小的线性函数。自由参数的数量也是序列长度n的线性函数。
在下面的大多数实验中,神经网络有一个隐藏层,隐藏成在词特征映射的前面,直接连接词特征到输出层。因此,实际上是由两个隐藏层:共享词特征层C和双曲正切隐藏层。
输出层采用softmax函数:
其中yi是每个输出词i的未归一化log概率,计算如下:
其中b,W,U,d和H都是参数,x为输入,则θ=(b, W, U, d,H)。双曲正切被一个元素接一个元素的作用域向量中。当神经网络中隐藏单元的数目为h,词表大小为|V|时,b是|V|维的列向量,W是|V|×(n-1)m的矩阵,U是|V|×h的矩阵,d是h维的列向量,H是h×(n-1)m的矩阵。需要注意的是,一般的神经网络输入是不需要优化,而在这里,x=(C(wt-1 ),C(wt-2 ),…,C(wt-n+1)),也是需要优化的参数。在图4-1中,如果下层原始输入 x 不直接连到输出的话,可令W=0。
自由参数的数量是|V|(1+nm+h)+h(1+(n-1)m).其中的主要因子是|V|(nm+h)。
如果采用随机梯度算法的话,梯度更新的法则为:
其中ε为学习速度(learning rate)。需要注意的是,一般神经网络的输入层只是一个输入值,而在这里,输入层x也是参数(存在C中),也是需要优化的。优化结束之后,语言模型训练完成。
3. 并行化的实现
即使参数的数量是输入窗口大小n和词表大小|V|的线性函数,即已经被限制的很好,但是计算的总量还是远远大于n-gram。主要原因是在n-gram模型中,获得特定的p(wt|wt-1,…,wt-n+1)不需要计算词表中所有的概率,因为简单的归一化。神经网络计算的瓶颈主要是在输出层。运行模型(在训练和测试时)在一个并行化的计算机中是减少计算时间的方法,我们在两种平台上探索了并行化:贡献内存处理器和Linux集群。
3.1 数据并行处理
在共享内存处理器的条件下,并行是很容易实现的,这归功于非常低的通信开销。在这种情况下,我们选择数据并行化的实现方式,每个处理器工作在不同的数据子集。每个处理器计算它拥有的训练样例的梯度,执行随机梯度下降算法更新内存中共享的参数。我们的第一个实现是很低速,因为采用了同步算法来避免写写冲突。处理器的大多数时间浪费在了等待其他处理器上。
取而代之,我们选择异步实现方式,每个处理器可以在任意时间向共享的内存中写数据。有时一些更新因为写写冲突而丢失,这导致了参数更新的一些小噪声的产生。然而,这种噪声是很微不足道的。
不幸的是,大型共享内存计算机是很昂贵的,并且它们的处理器的速度倾向于比CPU集群落后。因此我们可以在高速的网络集群上得到更快的训练。
3.2 参数并行处理
如果并行计算机是一个CPU的网络,我们通常支付不起过于频繁的参数交换的开销,因为参数的规模是百兆级别的,这将消耗大量的时间。取而代之我们选择参数并行处理,特别的,参数是输出单元的参数,因为这是在我们的架构中绝大多数计算发生的地方。每个CPU负责计算一个未正则化概率的输出子集。这种策略允许我们实现一个通信开销微不足道的并行的随机梯度下降算法。CPU本质上需要交换两种数据:(1)输出层的正则化因子,(2)隐藏层的梯度和词特征层。所有的CPU都复制在输出层之前的计算,然而这些计算比起总的计算量是微不足道的。
举例来说,考虑在AP news上的实验:词表大小|V|=17964,隐藏层单元数量h=60,序列长度n=6,词特征向量维数m=100,单个训练样例的计算量是|V|(1+nm+h)+h(1+nm)+nm。在这个例子中,在输出层需要的计算量占总计算量的分数为
这个计算是近似的,因为实际的CPU时间随着计算的种类的不同而不同,但是它显示出并行计算输出层是具有积极影响的。所有的CPU都要复制非常少量的因子,这对总的计算时间影响并不大。如果隐藏层单元的数据巨大,并行化计算也是有益的,我们在这里不做实验证明了。
下面用到的符号中“.”代表笛卡尔积,“‘”代表矩阵转置,CPUi(i取值范围是0~M-1)负责计算输出单元起始号为starti=i×⌈|V|/M⌉, 长度为 min(⌈|V|/M⌉,|V|-starti)的输出层块。

权重惩罚正则化没有在上面显示,但是可以简单的被实现。需要注意的是参数的更新是立即的而不是通过一个参数梯度向量,这样做可以提高速度。
在前向计算阶段,会出现一些问题,其中一个问题是pj可以全部为0,或者他们的其中一个非常大而不能进行指数运算。为了避免这个问题,通常的解决方案是在计算指数运算之前,减去yj中最大的数。因此我们可以在计算pj之前加上一个Allreduce运算去在M个处理器间共享yj的最大值。
在低速度的集群上,仍然可以获得有效的并行化。与其在每个训练样例计算时通信,不如在每K个训练样例计算时通信。这需要保存神经网络的K个激活和梯度。在K个训练样例的前向阶段后,概率的和必须共享给处理器。然后K后向阶段被初始化。在交换了这些梯度向量之后,每个处理器可以完成后向阶段并更行参数。如果K过大,将会导致不收敛的问题。
4. 实验结果
在Brwon语料库上的1181041个词序列上进行了对比实验。前800000个词用来训练,接下来的200000个词用来调整模型的参数,剩下的181041用来测试。不同的词的数量是47587。词的频率![]() 3的被合并成为一项。把词表的大小缩小到了|V|=16383。
3的被合并成为一项。把词表的大小缩小到了|V|=16383。
一个实验也在1995和1996的AP news的文本数据上运行。训练集是大约1400万的序列,发展集的大小大约是100万的序列,测试集也是100的序列。数据有148721个不同的词,我们把词表缩小到|V|=17964,使用的方法是保留高频率的词,把大写字母转化为小写字母,把数字和特殊字符合并等。
对于神经网络,初始的学习速率被设置为ε0=0.001,并且逐渐的采用公式εt=ε0/(1+rt)缩小,其中t代表已经被更新的参数数量,r是衰减因子,取值为10-8。
4.1 N-Gram模型
第一个对照的对象是使用插值法和平滑法的trigram模型。模型的条件概率表示为
其中,条件权重αi(qt)>0,∑iαi(qt)=1。p0=1/|V|,p1(wt)是unigram,p2 (wt|wt-1)是bigram, p3 (wt│wt-1 ,wt-2)是trigram。αi可以通过EM算法求得,大约需要5次迭代。
4.2 结果
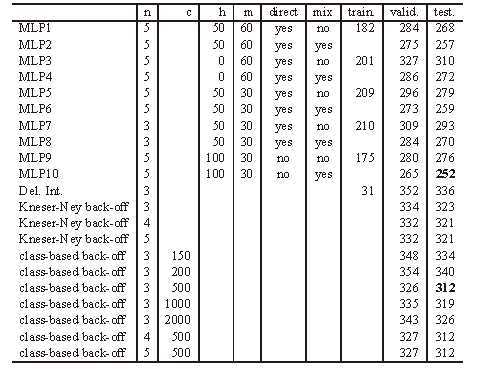
下图为基于困惑度的对不同模型的测试结果。
可以看到神经网络语言模型比最好的n-gram性能要好。
5. 结论
实验在两个语料库上进行,一个具有超过一百万的训练样例,另一个更大有一千五百万词。实验显示了本论文提出的方法获得了比先进的trigram好很多的困惑度值。
我们相信主要的原因是该方法允许学习分布表示来解决维数灾难的问题。这个模型可能有更多的可以改进的地方,在模型的架构方面,计算效率方面和先验知识的运用方面等。将来的优先研究点应该是提高训练速度。一个简单的想法来利用时间结构并扩展输入窗口的大小的方法是利用卷积神经网络。更一般的在这里介绍的工作打开了提高统计语言模型方法的大门,用基于分布表示的更加平滑的表示方法代替条件概率表。鉴于统计语言模型研究的很多努力工作都花费在了限制和总结条件变量上,来防止过拟合问题,在本论文中介绍的方法转移了这个困难:更多的计算被需要,但是计算和内存需求规模都是线性的,而不是条件变量的指数级别。
A Neural Probabilistic Language Model
标签:style blog http io 使用 strong ar 数据 2014
原文地址:http://www.cnblogs.com/Dream-Fish/p/3950024.html