标签:之间 逻辑或 inpu 编译 models 感知器 add http 类型
神经网络非线性能力即原理
1. 感知器与逻辑门
2. 强大的空间非线性切分能力
3. 网络表达能力与过拟合问题
4. BP算法与SDG
Café主要是用于图像的主流框架
Tensflow框架,灵活的网络,工程上做训练,常用库TF-learning,TensorLayer
Kreas框架 搭建常用网络
深度学习应用:
图像上的应用:给照片打标签;对相册分类;拍立淘;自动驾驶
NLP上的应用:模仿小四的文笔;google中英文翻译
综合应用:看图说话 ;问答系统
一点基础:线性分类器(在样本点空间找到分割面,最简单的叫线性分割,在二维空间中找到直线分割这些点,三维空间就是一个平面…)
针对图像,就是去找到一个合适的映射函数,通过这个函数映射到一个10个类别的得分向量。
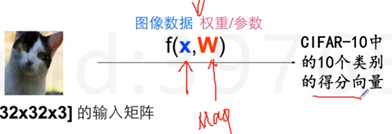
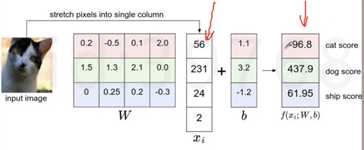
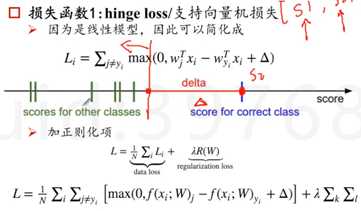
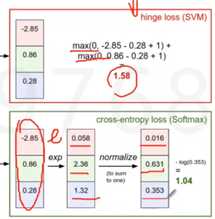
损失函数:可以调整参数或权重W,使得映射结果和实际类别吻合,损失函数用来衡量吻合度。损失函数1:hinge loss/支持向量机损失 标准答案的得分,比那些错误分类的得分都高出一个安全的delta。假设正确答案是猫,看所有非猫的答案和s2(猫的得分)之间的差距,在安全距离之外,损失则为0,超过安全距离,则给惩罚加到最后的Loss
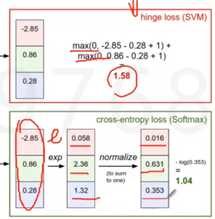
损失函数2:交叉熵损失(softmax分类器)
熵描述混乱程度的
互熵描述两个分布之间的关系
假设分类是狗猫大象,实际是猫,所以标准答案的概率向量[0,1,0] ,另一个是算出来的得分的概率向量[0.9, 0.05, 0.5] (将得分取e,然后归一化,取log,乘法取Log可以变成加法,使得可以在计算机的精度范围内进行计算)。评估这两个概率向量的差异的一个方式就是交叉熵,可以从最大似然的角度理解,猫是正确答案,则希望log(P猫)最大,则最小化-log(P猫)。为什么不用MSE,因为是非凸的函数。

通用的学习框架
在不同的数据类型上去学习的结构,隐层可能是局部的特征抽取,交叉和组合
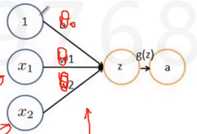
逻辑回归是很简单的线性分类器,从逻辑回归到神经元感知器,θ0是偏置项。添加少量隐层,浅层神经网络。
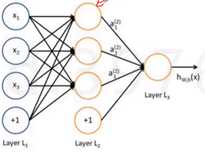
有时候线性分类器是分不开我们的类别,这时候我们的决策边界要是曲面的,而神经元可以完成类似于【逻辑与】,中间加一隐藏层(如下图,g(Θx)),只有x1,x2同时满足等于1的情况下,g(θx)才取值为1,类别判别为×,x1,x2可以认为是线性决策边界(逻辑回归),同时满足两个的才能选出×,这样就完成了平面的非线性切分。神经元也可以完成【逻辑或】操作。
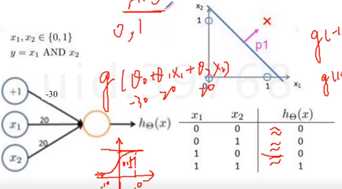
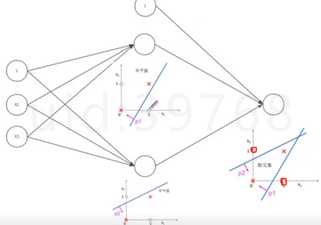
对线性分类器的AND和OR的组合,完美的对平面的样本点分布进行分类。如下图,把绿色的那块用若干的线性分类器抠出来,然后用AND组合起来,就能把这块区域抠出来。
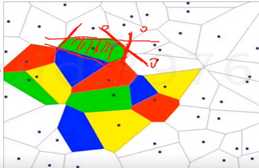
一个隐藏肯定可以完成AND的操作,and可以把若干个决策边界组合,开凸区域或者闭凸区域都可以抠出来;双隐层可以任意形状,可以把刚刚抠出来的区域求OR。
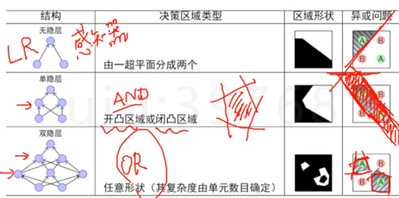

过多的隐藏层和神经元节点,会带来过拟合问题。不要试图通过降低神经网络数量来缓解过拟合,用正则化或dropout。
神经网络的结构:隐层就是对我上一层的数据做一些交叉组合,形象点就是在抽特征。
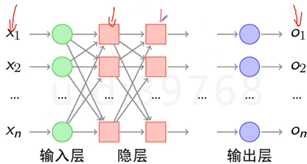
神经网络之传递函数(激活函数):
对每一层的输出有个非线性的处理。S函数(sigmoid)VS双S函数。相当于wx+b外面加一个非线性映射。
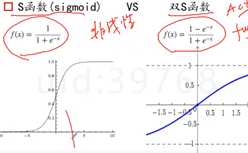
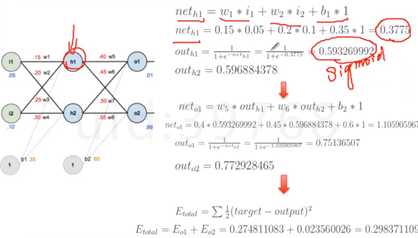
神经网络之BP算法:
“正向传播”求损失,“反向传播”回传误差,根据误差信号修正每层的权重。

神经网络之SDG
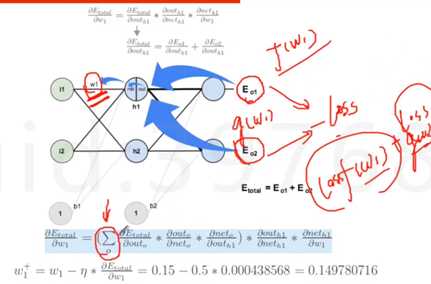
Error是权重W的函数,我们需要找到使得函数最小值的W
应用了复合函数的链式求导法则,下面第一个公式就是对w1求导,第二就是原则求导的梯度方向走。
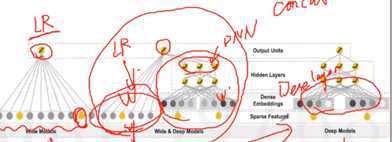
Google wide&&Deep Model代码:
Import pandas as pd
From keras.models import Sequential #序贯模型,从底向上搭积木
From keras.layers import Dense, Merge #dense层(全连接)和merge层(拼接操作)
From sklearn.preprocessing import MinMaxScaler
def main():
df_train = load(‘adult.data‘)
df_test = load(‘adult.test‘)
df = pd.concat([df_train, df_test])
train_len = len(df_train)
X, y = preprocess(df)
X_train = X[:train_len]
y_train = y[:train_len]
X_test = X[train_len:]
y_test = y[train_len:]
#Wide部分
wide = Sequential() #初始化左边的wide部分
wide.add(Dense(1, input_dim=X_train.shape[1]))
#Deep部分
deep = Sequential()
# TODO: 添加embedding层
deep.add(Dense(input_dim=X_train.shape[1], output_dim=100, activation=‘relu‘)) #一个全连接
#deep.add(Dense(100, activation=‘relu‘))#一个激活函数
deep.add(Dense(input_dim=100, output_dim=32, activation=‘relu‘)) #再加第二次
#deep.add(Dense(50, activation=‘relu‘))#一个激活函数
deep.add(Dense(input_dim=32, output_dim=8))
deep.add(Dense(1, activation=‘sigmoid‘)) #1是最后输出1个节点 过一个sigmoid
#Wide和Deep拼接
model = Sequential()
model.add(Merge([wide, deep], mode=‘concat‘, concat_axis=1)) #左边和右边的连接在一起
model.add(Dense(1, activation=‘sigmoid‘)) #最后输出一个全连接
#编译模型
model.compile(
optimizer=‘rmsprop‘, #可以用SGD
loss=‘binary_crossentropy‘,
metrics=[‘accuracy‘]
)
#模型训练
model.fit([X_train, X_train], y_train, nb_epoch=10, batch_size=32)
标签:之间 逻辑或 inpu 编译 models 感知器 add http 类型
原文地址:http://www.cnblogs.com/fionacai/p/7171990.html