标签:mat 查找 路由协议 http 等等 desc bgp 产生 增量
原文地址:http://mp.weixin.qq.com/s?src=3×tamp=1500043305&ver=1&signature=XwiIVVLHaVK5kzRNQKR1dkOzl1DR375P-R9g998sGTpT8WF20P9REPkYOfS85KOlI2h8RnHL3jvJvFu6gu*CNceX8Ky1iJXeGkX1NGYyMFruvBNS1XsJUv3RHgtEpGEIdMN4UZfKkUcdQQ6b9ZbvkqUaAcyanc3bhd8mwKfeHTM=
本文讲述 BGP,最终还是为了讲述 MP-BGP MPLS VPN,还是为了 MPLS VPN 与 Neutron Network 的对比分析。如果您对 BGP 比较熟悉,可以略过本章节。
路由协议分为两类,IGP(Interior Gateway Protocol,内部网关协议)和 EGP(Exterior Gateway Protocol,外部网关协议)。
IGP 并不是一个协议,而是一类协议的统称,包括 RIP(Routing Information Protocol,路由信息协议), ISIS(Intermediate system to intermediate system,中间系统到中间系统), OSPF(Open Shortest Path First,开放式最短路径优先) 等等。
EGP 也是同理,其并不是一个协议,也是一类协议的统称,包括 EGP(这个时候,它是一个协议的名称。这个协议现在已经被淘汰,不再使用)和 BGP(Border Gateway Protocol,边界网关协议)。
本文假设读者对 IGP 有一定的了解。
【注】EGP 有时候表示的一类协议的统称,有时候表示的是一个具体的协议。作为一个具体的协议时,EGP 已经被淘汰。作为一个协议的统称时,EGP 与 IGP 相对应,不可或缺。现在 EGP 这类协议中,真正使用的就是 BGP。
笔者再啰嗦一遍,本文假设您对 IGP 有一定的了解。
全世界的互联网上的路由器(不包括您家里的无线路由器,^_^)有几万台(我没有查找到具体的数据,几万台,是 Cisco 的一篇培训文档给出的数字)。如果我们假设这几万台路由器在一个系统里,也没有什么 BGP,都运行着一种 IGP(比如 OSPF),那么其情形会是这样:
图1 几万台路由器示例(其实只画了几百台)
上图中,我只画了几百台路由器,而且路由器之间也没有连线,不过这已经让人感觉不舒服了,尤其对于有密集恐惧症的童鞋而言。
不过路由器中的问题,倒不是密集恐惧症,而是如下两个:
(1)每个路由器的路由表项,将达到几十万乃至几百万的条目,这是当前路由器的能力所不能承受的(或者说,要想达到如此多的路由表项,其价格,是用户所不能承受的)。
(2)每个路由器都有可能有个头疼脑热(接口 down 了之类的),这会引发全网的路由通告。几万个路由器,一会这个路由器出点毛病,一会那个路由器出点毛病,那么整个互联网也不用干别的了,就是传输这些全网的路由通告信息了。这也是不能接受的。
为了解决这些问题,大神们给出的解决方案是:自治系统(autonomous system)。
自治系统,简单地说,就是把互联网(里面的路由器)划片,划成一个一个片区,这些 IGP 协议,不能出片区。

图2 自治系统示意图
我查了一下百度百科和维基百科,两者关于 AS(autonomous system)的解释,我不敢说他写得不对,我只能说,写得有点晦涩难懂。(关于 AS, 百度百科实际上是翻译的维基百科)。笔者结合各种资料,给出一个 AS 的解释吧(是解释,不是定义):
l 在一个 AS 内,只运行一种 IGP(如果说,就是要运行两种 IGP,这属于抬杠。如果一个 AS 内运行两种 IGP,并且相安无事,那是 IGP 的本事,如果出现了问题,那也是 IGP 的问题。抛开抬杠这一想法,那么,一个 AS 内,就是只运行一种 IGP)
l 在一个 AS 内运行的 IGP,与其他 AS 内的路由器无关。也就是说,在 IGP 这个层面,不同 AS 的路由器,老死不相往来。
l 在一个 AS 内,除了有相同的 IGP(因为只有一种,所以相同)外,还可以制定自己独立的路由策略和安全策略,与其他 AS 无关。
换个角度说,如果没有 BGP(后面我们会讲述 BGP),那么一个个 AS,就是一个个网络孤岛:内部有自己独立的 IGP 和路由策略、安全策略,外部不与其他 AS 交往。
关于 BGP 如何解决 AS 孤岛问题,我们会在下面讲述,这里暂时不要着急,先看看 AS 有关的信息。
区分不同 AS 的是 AS ID(或者叫 AS 号码)。AS 号码的分配,是由 Internet Assigned Number Authority (IANA) 机构来统一规划和分配。在 2009 年 1 月之前,只能使用最多 2 字节 长度的 AS 号码,即 1-65535,在 2009 年 1 月之后,(IANA)决定使用 4 字节长度 AS, 范围是 65536 -4294967295。当前,通常还是使用 2 字节长度的 AS,也就是 1-65535。
AS 号码划分为公有 AS 和私有 AS,公有 AS 的范围是 1-64511,私有 AS 范围是 64512-65534;公有 AS 只能 用于互联网,并且全球唯一,不可重复,而私有 AS 可以在得不到合法 AS 的企业网 络使用,可以重复。很显然,因为私有 AS 可以被多个企业网络重复使用,所以这 些私有 AS 不允许传入互联网,ISP 在企业用户边缘,需要过滤掉带有私有 AS 号码 的路由条目。
IANA 分配给中国的 AS 号有一百多个(117个?),我们随便举几个例子:
|
AS 号 |
AS 名称 |
|
AS17739 |
HAPLINK-CN-AP上海电信恒联网络有限公司 |
|
AS18238 |
PDONLINE人民日报编辑部 |
|
AS3460 |
Institute of High Energy Physics中科院高能物理研究所 |
|
AS3717 |
Beijing University of Chemical Technology北京化工大学 |
|
CHINANET-BACKBONE电信骨干 |
|
|
AS4538 |
ERX-CERNET-BKB教育网骨干 |
表1 AS 的例子
我们再看一张图,对 AS 加深一下直观的认识:

图3 AS 的例子
您也可以直接访问 https://cyber.harvard.edu/netmaps/country_detail.php/?cc=CN,以获取更多信息。
上一小节说了,如果 BGP,那么一个个 AS,就是一个个孤岛。那么,BGP 是如何连接这些孤岛的呢?
笔者再次啰嗦:读者需要有一定的 IGP 知识。
我们知道,IGP 最终目的,是为了构建路由表。每个路由器里,都有一个路由表。路由器在做 IP 转发时,所依据的就是这个路由表。路由表的大概的表结构如下:
|
目的网络 |
网络掩码 |
网关 |
出接口 |
|
12.1.1.0 |
255.255.255.0 |
12.1.1.2 |
12.1.1.1, 0/0/0.1 (伪码,表示:出接口是0框0板0端口1子接口,出接口 IP 是 12.1.1.1) |
|
13.1.1.0 |
255.255.255.0 |
13.1.1.3 |
13.1.1.1, 0/0/1.1 |
表2 一个路由表的表结构示意
针对上表,我们给出对应的一个组网示意图(上表给出的 R1 的路由表):
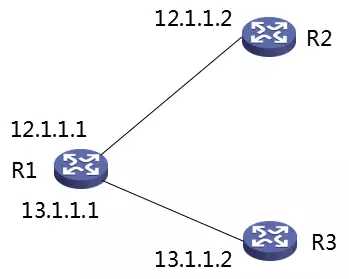
图4 一个简单路由器组网图
而 BGP 跟 IGP 不一样,它并不能自己构建路由表,它只是传播路由:我不生产路由,我只是路由的搬运工!
在讲述 BGP 如何搬运路由之前,我们先定义一下 BGP 相关的角色。BGP 是一个协议,协议就是一张纸(不是有句话吗,叫撕毁协议,撕的就是纸,^_^)。要想让 BGP 发挥作用,还需要路由器——运行 BGP 协议的路由器。一个运行 BGP 协议的路由器,叫作 BGP Speaker。
这些运行 BGP 协议的路由器,互相交互,从而达到搬运路由的目的。
不是任意两个 BGP Speaker 就能互相交互,互相搬运路由。两个 BGP Speaker 必须组成一对(BGP peer,BGP 对等体),才能互相交互、搬运路由。
通信世界里,有很多地方涉及到 peer 这个概念(比如 MPLS LDP peer),有的对等体是自动发现的(每个家伙对着人群吼一嗓子(广播),hello,今晚有约炮的吗,如果有对上眼的,那么这两个家伙就组成 peer)。不过 BGP 的对等体并不是自动发现,而是靠人工指定(路由器有对应的命令行,两个路由器互相指定对方的 IP是自己的对等体)。
如果组成 BGP peer 的两个路由器,分属两个 AS,那么这样的 BGP 就称作 eBGP(External Border Gateway Protocol);如果两个路由器,同属一个 AS,那么这样的 BGP 就称作 iBGP(Internal Border Gateway Protocol)。如下图所示:
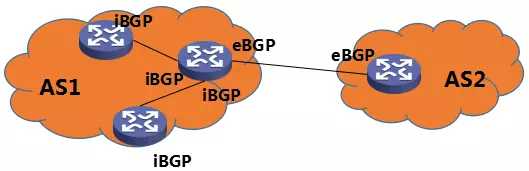
图5 eBGP 与 iBGP
eBGP 与 iBGP,只是在一些地方有所不同,其他绝大部分是一样的,我们会在后面的介绍中涉及这些信息。
我们前面说过,BGP 是为了解决 AS 孤岛的问题,是为了在 AS 间传递路由,那么 AS 内为什么也需要 BGP 呢?这个我们也会在后面讲述,这里暂时不用纠结。
人工指定 BGP peer 以后,也并不是说这个 peer 就建立了。两个路由器还需要进行一定的交互,才能最终建立 BGP peer。BGP peer 建立以后,才能后续的路由互相通告,才能将一个个 AS 孤岛连接起来。
BGP 的具体消息格式与消息内容,我们下面会讲解。这里只须知道 BGP 各种消息都是承载在 TCP 协议上的(端口号是 179)。这就引发了一个有趣的现象:
iBGP peer,我们前面介绍,是在一个 AS 内的。而一个 AS 内,因为有 IGP 的存在,所以 iBGP peer 并不要求两个路由器是直连路由,只要两者能建立 TCP 连接即可。
而 eBGP peer,分属两个 AS。我们知道,在 BGP 协议(建立 peer,通告路由)运行之前,两个 AS 其实是两个孤岛,其实是不通的。现在 eBGP peer 却要求首先建立 TCP 连接,这必须要求:eBGP peer 必须是直连路由。虽然有的资料说,eBGP peer 必须是直连路由,是 BGP 协议的规定,不过笔者以为,这不是什么协议规定的问题,而是必须如此的问题。否则,就陷入“先有鸡还是先有蛋”的问题中了:要想建立 BGP,必须要 TCP 先连通;要想 TCP 先连通,必须先建立 BGP。
下图是一个示意:
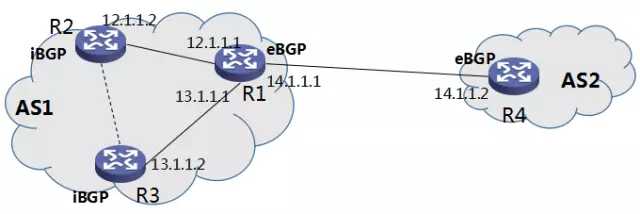
图6 BGP peer 示例
图中有很多文字互相干扰,建议您仔细瞅一瞅。
在上图中,R1 与 R4 互相组成 eBGP peer,我们看到,建立 BGP peer 的 IP 分别是:14.1.1.1 与 14.1.1.2,属于同一个网段,直连路由。
而 R2 与 R3 互相组成 iBGP peer,我们看到,建立 BGP peer 的 IP 分别是:12.1.1.2 与 13.1.1.2,并不属于同一个网段,因为它们之间可以通过 IGP 进而建立 TCP 连接。
这里有个细节要注意,一个路由器有很多子接口,每个子接口都可以有一个 IP 地址,也就是说,一个路由器可以有很多 IP 地址。我们在指定 BGP peer 时,要注意到底是要选择哪个 IP 地址。
了解 loopbak 子接口的童鞋都知道,象这种选择一个子接口的 IP 地址作为某某某代表的情况(比如代表一个路由器/RouterID,比如这里选择一个 IP,与对方 IP 组成 BGP peer),最合适的是 loopback 子接口的 IP 地址。(loopback 为什么最合适,由于篇幅原因,笔者在这里就不啰嗦了。)
说到 loopback 子接口 IP 地址,笔者提请读者注意:直连路由,并不意味着就是同一个网段,虽然在上图中,笔者给出的例子是同一网段。
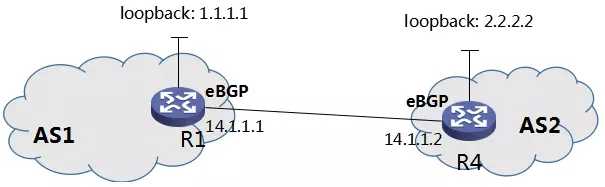
图7 loopback 子接口 IP 组成 eBGP peer
上图中,我们可以配置两个路由的 loopback IP 互相组成 eBGP peer,两个 IP 地址分别为“1.1.1.1”和“2.2.2.2”,虽然不是同一个网段,但是仍然可以分别通过各自的子接口(IP 地址分为别为“14.1.1.1”和“14.1.1.2”)建立直连路由。
BGP 路由通告,就是 BGP peer,互相把自己知道的路由表信息,告诉对方。
为了方便讲述,我们先以两个 AS/eBGP 为例,如下图所示:
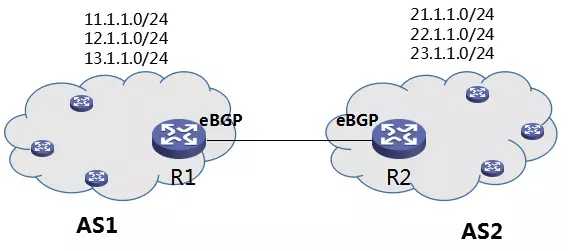
图8 BGP 路由通告示例
图中,两个 AS,分为为 AS1,AS2。R1,R2 组成 eBGP peer。A1 通过 IBGP,各个路由器都建立了到达“11.1.1.0/24, 12.1.1.0/24, 13.1.1.0/24”网段的路由表,A2 通过 IBGP,各个路由器都建立了到达“21.1.1.0/24, 22.1.1.0/24, 23.1.1.0/24”网段的路由表。
现在我们的问题是,R1 和 R2 如何将自己知道的路由信息(路由表),告知对方。
路由器中有 N 张路由表,这 N 张路由表,分为两类:一类是核心表,或者说是转发表,路由器的转发就靠的这张表;另一类是各个路由协议自身所有的路由表。
各个路由协议的路由表信息,会同步到核心路由表中,供转发使用(如何同步,就不必在意了,反正各个路由器的代码会做这件事情)。
在运行 BGP 协议的路由器中,它会有 IGP 路由表,BGP 路由表,当然也会有核心路由表。假设 IGP 是 OSPF,其路由表示例,如下图所示:
图9 路由器中路由表示例
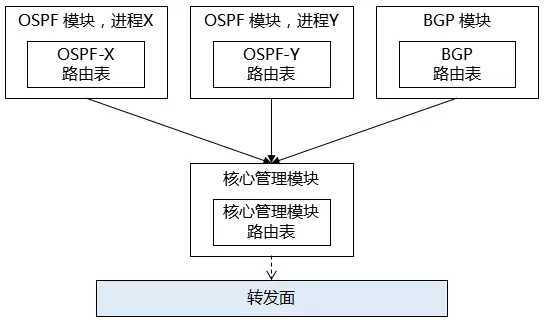
通过前面介绍,我们知道路由器中有 N 张路由表,而 eBGP peer 之间互相通告的就是自己的 BGP 路由表信息,双方互相把自己的 BGP 路由表内容告知对方。
IGP 的路由表,会通过 IGP 协议而学习建立(当然,也可以通过人工配置静态路由)。但是,BGP 并不能象 IGP 一样自动学习建立 BGP 路由表。所以,一个 BGP 路由器,它的 BGP 路由表,初始化时是空的。
是空的,是空的,是空的。
是空的,还玩个屁啊。大家的路由表都是空的,那还互相告知对方自己的路由表内容,这不就跟某些会议是一样的吗?表面上高大上,其实就是闹着玩!闹着玩也就算了,还太他娘的烦人,浪费时间!
客官别急,^_^。
BGP 路由表的内容的来源有几种:
l 人工输入。直接人工添加 BGP 路由表。
l 从 IGP 路由表引入。通过命令行配置了相关引入规则后,IGP 路由表中相应的路由表项会自动进入 BGP 路由表,以后 IGP 路由表发生变化,相应的表项也会自动进入 BGP 路由表。
l 从 EBGP 路由导入(因为 EBGP 路由协议基本废弃,所以这个可以忽略)
l IGP 路由重分布(redistribute)进入 BGP 路由。
有了上述的基础,BGP 路由表里已经有内容了,这时候,BGP peer 就可以互相通告了。BGP 路由器收到对端发过来的路由通告以后,就可以填入自己的路由表中(当然还有一些细节要处理,这里我们先忽略)。
eBGP 收到对等体发送过来的路由通告以后,除了填入自己的路由表中,还会再通告给它的另一个对等体(如果有的话),如下图所示:
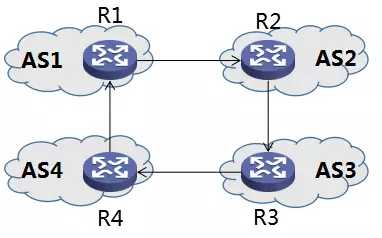
图10 eBGP 路由通告
图中,R1/R2, R3/R4,R4/R1 互相都是eBGP peer。R1 通告给 R2 的路由,R2 会继续通告给 R3,R3 也会继续通告给 R4,R4 也会通告给 R1。
需要说明的是,R1->R2->R3->R4,这样的通告链,是没有问题的。但是,R1->R2->R3->R4->R1 这个通告链,即 R1 的路由,绕了一圈,又通告给自己,这会形成路由环路。BGP 是有办法解决这个问题的,这个我们放在下面讲述。
全世界的 AS,就是通过 eBGP peer 即路由通告,互相连通,从而避免形成一个个 AS 孤岛。(当然,还需要 iBGP,下一小节会描述)
我们首先来看看为什么需要 iBGP。上一小节说过,全世界的 AS,就是通过 eBGP peer 及路由通告,互相连通,从而避免形成一个个 AS 孤岛。真的是这样吗?
我们看下图:
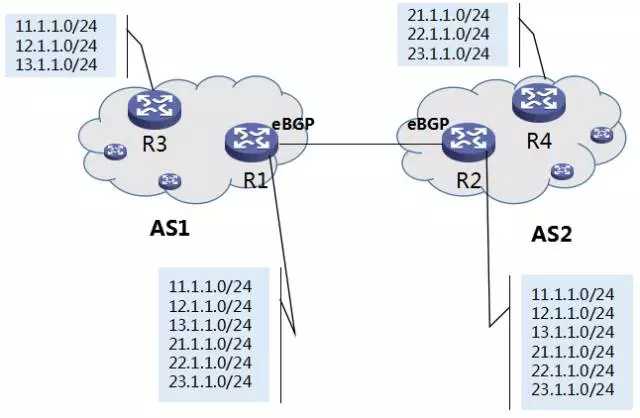
图11 如果没有 iBGP
图中,R1 与 R2,通过 eBGP 路由通告,都具有到达两个 AS 域的路由信息。但是,其他路由器,还是只知道各自域内的路由信息,比如图中的 R3、R4。这样,R3 到 R4 的路由其实是不通的。
那么,我们说通过 eBGP peer 及路由通告就能把一个个 AS 孤岛连起来,看起来还远远不够。
解决这个问题的思路,其实很简单,比如在 AS1 内,就是想办法把 R1 知道的路由信息告知域内其他路由器。AS2也是同理,所有域都是同理处理即可。
那么用什么方法达到这个目的呢?
一种方法是路由重分布(redistribute,个人觉得这个应该翻译为“重发布”更好),即域内其他路由器还是只运行 IGP 协议,BGP Speaker(比如上图中的 R1),使用路由重分布的方法,将其自身的路由信息,告知其他路由器。这个方法非常不好(由于篇幅和文章主题的原因,笔者就再详细描述这个方法为什么不好了),基本是被抛弃的方法。
另一种方法是利用 BGP。是的,在同一个域内也运行 BGP(称为 iBGP),利用 BGP 的路由通告功能,从而达到目的。(还记得我们前面的问题吗?为什么域内需要 iBGP?)
eBGP 的路由通告规则是,一个 eBGP Speaker 接到路由通告后,可以再通告给它的 另一个 eBGP peer,然后一直通告下去。
但是,iBGP 的只能通告一跳,如下图所示:
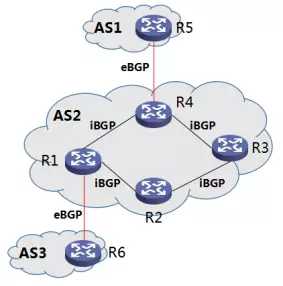
图12 iBGP 路由通告只能通告一跳
R1/R6,R4/R5 是 eBGP peer,R1/R2,R2/R3,R3/R4,R4/R1 是 iBGP peer。
R6 通告给 R1 的路由,R1 可以通告给 R2(一跳),但是 R2 不会再通告给 R3(超过一跳)。
R6 通告给 R1 的路由,R1 可以通告给 R4(一跳),R4 可以通告给 R5(是 eBGP,不受 iBGP 一跳的限制),但是 R4 不会再通告给 R3(超过一跳)。
R5 通告给 R4 的路由,同理。
iBGP 路由通告只有一跳,也可以换一种表述(如果在数学里,这个叫推论):一台 BGP 路由器从 iBGP 邻居收到的路由,不能传递给其它 iBGP 邻 居,只能传给 eBGP 邻居。
iBGP 路由通告为什么只能是一跳,官方说法是:为了防止路由环路。在 上一小节中我们看到,eBGP 通告的跳数没有限制,但是会出现环路——eBGP 通过在路由通告中带上 AS 路径信息(后面会详细解释)来解决这个问题。而 iBGP 的路由通告里没有附带 AS 路径信息,从而无法避免环路。所以,iBGP 的协议规定,只能是通告一跳。
以上是官方的说法,如果让我说,它的原因就是:太任性。iBGP 路由通告中带上 AS 路径信息,与 eBGP 一样,又会怎样?eBGP 没有问题,难道 iBGP 就会有问题?!
No zui No die!
iBGP 这个特性(通告只能一跳),引发了很多问题,而为了解决这些引发的问题,又得引入新的方案。而新的方案,可能又有新的问题,又得再引入新的方案。
本来,由于篇幅和文章主题的原因,笔者不打算再继续介绍下去。不过笔者写到这里,心里非常不舒服,理解不了 iBGP 搞了这么一个任性且作死的方案,那就继续展开介绍一些内容吧。
一、iBGP “全”互联
我们前面介绍,为了解决 AS 孤岛问题,引入了 eBGP, iBGP 的解决方案。不过,我们也看到,由于 iBGP 路由通告只能是一跳的特(wen)性(ti),造成事实上还是“半孤岛”存在,如下图所示:
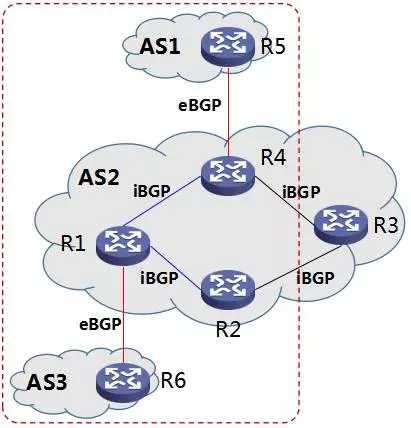
图13 “半孤岛”示意图
图中,R3 与 R6 就无法连通。而且,R2 与 R5 也无法连通。
为了解决这个问题,必须要“全互联”。这个“全互联”我是打引号的,因为并不是真正的全互联。“全互联”解释如下:
所有承担 eBGP Speaker 角色的路由器,必须与其他所有 iBGP 路由器建立“互联”。所谓“互联”就是建立 iBGP peer。
假设一个 AS 里有 N 台路由器,极端情况下,这 N 台路由器都是 eBGP Speaker,那么,这个时候,可就真正的是全互联了——真正的全互联,不用打引号——此时,互联的个数是:N * (N - 1) / 2,即需要 N * (N - 1) / 2 对 iBGP peer。如果 N = 1000,那么就是 499500(四十九万千五百) 对 iBGP peer,这个数量影响网络效率!
即使不是全部的路由器都是 eBGP Speaker,这个数量也不小。
为了解决这个问题,需要引入路由反射器(Router Reflector),这个我们放到后面在介绍。
二、路由黑洞
上述的“半孤岛”问题,有时候,可能是有意为之,如上图所示,有时候,就是特意设计为 R3/R6 不互通。这个还有一个高大上的名字,叫作:BGP 水平分割。
好吧,BGP 水平分割,一个高大上的名字,把 iBGP 的“半孤岛”问题变成了优点。但是这个所谓的优点,是有代价的,那就是有可能引发“路由黑洞”。
我们举一个更简单的例子,来说明这个问题,如下图所示:
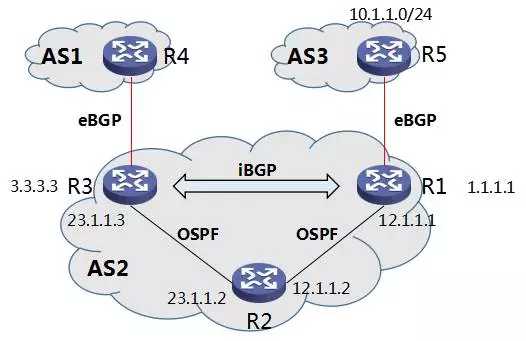
图14 路由黑洞的例子
首先说明一下图中的组网:
l R3/R4,R1/R5 分别组成 eBGP peer
l R1/R3 组成 iBGP peer
l R2 并没有运行 BGP,即 R2 不是 iBGP Speaker
l R1,R2,R3 运行 OSPF
l R1 与 R3 之间,并没有直连路由,即 R1 与 R3 之间的互联(比如 iBGP 所需要的 TCP 连接),是通过 R2 转发实现的。
这里我们看到,R2 实际上是与 R4、R5 不通的(实际上也是与 AS1,AS3 不通)。因为 R1,R3 分别从 R5,R4 所获得的 eBGP 通告路由,根本不会通告给 R2。这个不是因为 iBGP 路由通告只有一跳的问题,而是根本就没法通告,因为 R2 根本就没有运行 BGP 协议。这个说的好听点,也可以叫作“水平分割”,说的难听点,就是“半孤岛”,看你怎么说。不过,这个不是我们的重点,我们的重点是“路由黑洞”。
图中,R5 通过 eBGP 把路由(图中的例子是:目的网段是 10.1.1.0/24)通告给 R1,R1 再通过 iBGP 通告给 R3,R3 再通过 eBGP 通告给 R4。那么,R4 认为它是可以访问 10.1.1.0/24 网段的。
但是,实际上 R4 访问该网段时,其路由是:R4-R3-R2-R1-R5。但是,当报文到达 R2 时,根据前面分析,R2 实际上是访问不了 R5 的。所以,报文到达 R2 时,会被 R2 丢弃。
这就是路由黑洞。
路由黑洞问题产生的原因,可以这样总结:当通过 BGP 收到的路由信息,在实际路由转发时,经过了一个路由器,如果这个路由器没有 相应的 BGP 路由(或者是由于没有运行 BGP 协议,根本接收不到 BGP 路由,或者是由于 iBGP 路由通告只有一跳的原因,而无法收到相应的 BGP 路由),那么这个路由器就会引发路由黑洞。(本文举的例子是“这个路由器根本就没有运行 BGP 协议”)
为了解决路由黑洞问题,又引入了“iBGP 与 IGP 路由同步”的解决方案。
请原谅,笔者又要吐槽。很多(90% 以上)资料,关于这个解决方案,只说了一半,这真让人崩溃。他们说的一半是:
在 BGP 路由传递中,有以下一条规则:当 BGP 要将从 iBGP 邻居学习到的路由信息传递给其它邻居之前(这个邻居通常是 eBGP 邻居),这些路由必须在 IGP 路由表中也能学到,否则认为此 路由无效而不能发给其它邻居。
这个有点拗口,需要解释一下。还是如上图所示,当 R3 将要把目的网段是“10.1.1.0/24”的路由通告给 R4 时,它会做两个判断:
l (1)这个路由是从 iBGP peer 学习到的吗?
l ------是的。是从 R1 学习到的
l (2)这个路由在 IGP 路由表中存在吗?
l ------不存在。因为在 IGP(图中是 OSPF) 路由学习中,根本就没有“10.1.1.0/24”任何信息(从图中可以看到,10.1.1.0/24,实际上是位于另外一个域 AS3 中)。
这两个条件都满足,那么对不起,这个路由就不通告给 R4 了。
很多资料,就说了这一半。单就这一半而言,并没有错误,但是并没有什么用啊。这样做,是不会造成“路由黑洞”了,但是我们也看到,AS1 与 AS3 也通不了啊,永远通不了,路由黑洞是没有了,彻底变成孤岛了!
受不了这些写资料的人!
那么,剩下的一半是什么呢?那就是:路由重分布(redistribute)。通过路由重分布,把 BGP 的路由重发布给 IGP。
路由重分布,并不是一个好的方案。这相当于为了解决一个问题,而引入一个方案,而这个方案又有新的问题......要了亲命了,O(∩_∩)O哈哈~。所以,这个“iBGP 与 IGP 路由同步”,默认都是关闭的。
可是,默认关闭,也没有解决问题啊,这不是陷入死循环了吗?
这我们就要重新捋一捋问题的来龙去脉。
我们在上一小节,介绍了 iBGP 方案的一些问题和解决方法,不过有的方法并不尽如人意。
我们看本质需求,本质需要并不是 iBGP 如何如何,而是“eBGP 路由需要导入域内所有路由器(有些路由器特意设计为不导入 eBGP 路由除外)”。
为了实现这个本质需求,我们给出了一些方案。而这些方案,又引发了新的问题。为了解决这些新问题,又引入了新的方案......
我们总结梳理如下:
图15 eBGP 路由导入域内的方法及问题梳理
上一节介绍了 BGP 的基本机制,这一节我们看看 BGP 的报文格式。本小节如无特别说明,所有内容都是覆盖 eBGP 和 iBGP。
BGP 一共有四种消息类型:
l Open: 用于建立BGP对等体之间的连接关系
l Keepalive: 周期性地向BGP对等体发出Keepalive消息, 用来保持连接的有效性
l Update: 携带的是路由更新(删减、增加)信息
l Notification: 当BGP检测到错误状态时, 就向对等体发出Notification消息, 之后BGP连接会立即被关闭
我们在前面章节的介绍中,涉及到了两种消息:Open 与 Update,只不过当时我们是从基本运行机制的角度所做的讲述。
BGP 的报文,承载在 TCP 连接上,其端口号是 179,如下图所示:
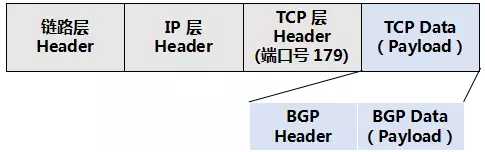
图16 BGP 承载在 TCP 上
BGP 所有消息的报文头,都是一样的格式,如下图所示:
图17 BGP Header 报文格式
关于这些字段的解释,我犹豫了一下,还是决定,直接 copy RFC 4271,必要的地方我加些注释吧。
l Marker: This 16-octet field is included for compatibility; it MUST be set to all ones.(全设置为1,其余不用管)
l Length: This 2-octet unsigned integer indicates the total length of the message, including the header in octets. Thus, it allows one to locate the (Marker field of the) next message in the TCP stream. The value of the Length field MUST always be at least 19 and no greater than 4096, and MAY be further constrained, depending on the message type. "padding" of extra data after the message is not allowed. Therefore, the Length field MUST have the smallest value required, given the rest of the message.(整个的报文长度,包括报文头长度在内。)
l Type: This 1-octet unsigned integer indicates the type code of the message. This document defines the following type codes:(报文类型,一共四种)
1 - OPEN
2 - UPDATE
3 - NOTIFICATION
4 - KEEPALIVE
BGP 四种消息,笔者以为,其余三种都不是重点,我们只须关注 Update 消息。因为这个就是著名的路由消息通告的消息。
BGP 将自身所知道的路由信息(存放在 BGP 路由表中),通过 Update 消息,通告给它的邻居(peer)。值得一提的是,由于 BGP 是基于 TCP 协议,所以它每次只是通告“增量”路由消息,而不是全量。这意味着:第一次将自己所有 BGP 路由信息告知对端以后,以后再通告,只须通告“变化”的路由信息即可。
笔者在网上看到一道题,我们一起来做一下:
在 BGP 协议中,每隔()时间向邻居发送路由更新信息
A. 30 秒
B. 60 秒
C. 120 秒
D. 无固定周期
BGP 是在什么时机向邻居发送路由更新信息的呢?
......
下面我们来看看 BGP Update 消息的报文格式,如下图所示:
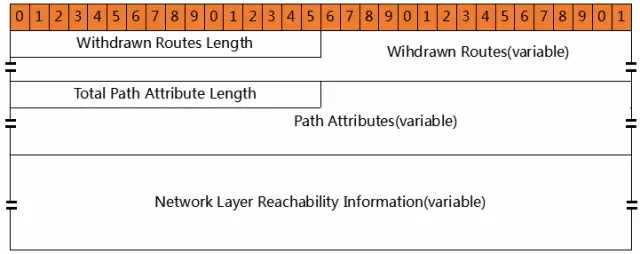
图18 BGP Update 消息报文格式
这个报文结构,分为三部分:
l 撤销的路由信息。包含两个字段:Withdrawn Routes Length,Withdrawn Routes。当上次通告的路由,有些路由无效时,需要靠这两个字段撤销(取消)。(已经无效的路由,得通知别人啊)
l 新增路由的属性。包含两个字段:Total Path Attribute Length,Path Attributes。新增的路由,除了目的网段以外,还有许多其他相关的信息。(这个我们会在下一节专门描述)
l 新增路由的信息。包含一个字段:Network Layer Reachability Information。表达的是目的网段信息。意思是,这些网段的路由是可达的。
路由属性比较复杂,我们放在下一小节专门描述。本小节,只讲述另外两个。
前面说过,路由通告,通告的是变化信息。消息类型(Update)本身,也明确了这一点。既然是变化信息,就有可能是增加,也有可能是删减。当有些路由无效时,那么告知对方的变化信息就是“删减”。BGP 使用“Withdrawn Routes Length,Withdrawn Routes”这两个字段告知邻居路由的删减信息。
我们先贴一下 RFC 4271 的官方说明文字:
l Withdrawn Routes Length:
? This 2-octets unsigned integer indicates the total length of the Withdrawn Routes field in octets. Its value allows the length of the Network Layer Reachability Information field to be determined, as specified below.
? A value of 0 indicates that no routes are being withdrawn from service, and that the WITHDRAWN ROUTES field is not present in this UPDATE message.
l Withdrawn Routes:
? This is a variable-length field that contains a list of IP address prefixes for the routes that are being withdrawn from service. Each IP address prefix is encoded as a 2-tuple of the form <length, prefix>, whose fields are described below:(图不贴了,我下面会另外贴图)
? The use and the meaning of these fields are as follows:
ü a) Length: The Length field indicates the length in bits of the IP address prefix. A length of zero indicates a prefix that matches all IP addresses (with prefix, itself, of zero octets).
ü b) Prefix: The Prefix field contains an IP address prefix, followed by the minimum number of trailing bits needed to make the end of the field fall on an octet boundary. Note that the value of trailing bits is irrelevant.
因为 Withdrawn Routes 是个变长的字段,所以首先需要一个字段“Withdrawn Routes Length”来表示 Withdrawn Routes 字段的长度。如果长度为0,则表示没有需要撤销的路由。
而 Withdrawn Routes Length,是一个列表,包含 N 个二元组(Length, Prefix),它的报文结构如下图所示:

图19 Withdrawn Routes 报文结构
Length 的长度是 1 字节,而 Prefix 的长度是变长的。
对于二元组,<Length, Prefix>,如果我们首先类比理解为“网段 + 掩码”,就比较好理解了,比如:1.1.1.0/24。这个只不过是反过来表示罢了。1.1.1.0/24,用这种方法表示是<24(length), 1.1.1(prefix)>,当然“1.1.1”要用bit的形式表示:111111100000000111111111(1 * 2553 + 1 * 2552 + 1 * 255)
如果 Length = 0(Prefix 也就不用填写了,也没地方填写了),那么意味着所有路由都撤销。
新增路由信息,用了一个高大上的名字:Network Layer Reachability Information(NLRI),其实其数据结构与 Withdrawn Routes 是一样的,也是一个 list,包含 N 个二元组<Length, Prefix>。
如果 BGP Update,只有这两类内容,一个是撤销路由信息,一个是新增路由信息,唉,世界多么美好。并不是!
对于新增路由信息,不能仅仅是告知一些目的网段(list<length, prefix>)这么简单,还需要告知这些目的网段的属性。属性非常复杂,我们放在下一节专门讲述。
深度探索 OpenStack Neutron:BGP(1) 【转载】
标签:mat 查找 路由协议 http 等等 desc bgp 产生 增量
原文地址:http://www.cnblogs.com/wanglm/p/7173035.html