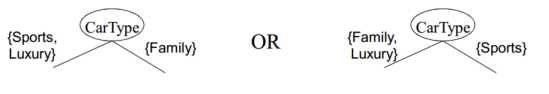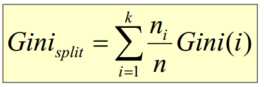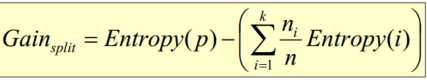标签:简单的 span 计算 大数 nbsp blog c4.5 需要 类型
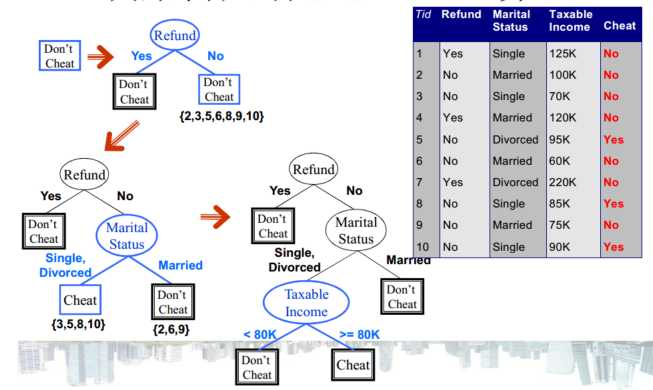
– 标称属性– 序数属性– 连续属性/数值属性
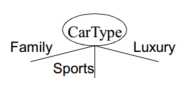
– 二路划分:将属性值划分成两个子集,如果基于数值属性,则将属性离散化为序数属性(有静态划分和动态划分2种方式),– 多路划分: 输出个数取决于该属性不同属性值的个数,如果是基于数值属性,则考虑所有的划分点,寻找最佳划分点(A<v)or(A>v);
②有3种不纯性度的量度:
- Gini指标(Gini Index)p(j | t) 是类j在结点t的出现概率Gini指标的取值范围
max 1 - 1/nc,出现的情况是t对应的记录集在所有类中均匀分布min 0,出现的情况是t对应的所有记录都属于同一个类
- 熵(Entropy)熵的取值范围
max log2 nc,出现的情况是t对应的记录集在所有类中均匀分布;min 0,出现的情况是t对应的所有记录都属于同一个类;
- 误分率(Misclassification error)误分率的取值范围max 1 - 1/nc,出现的情况是t对应的记录集在所有类中均匀分布min 最小0,出现的情况是t对应的所有记录都属于同一个类
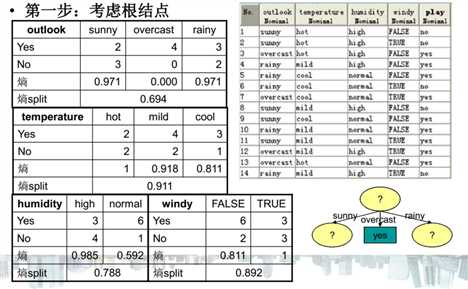
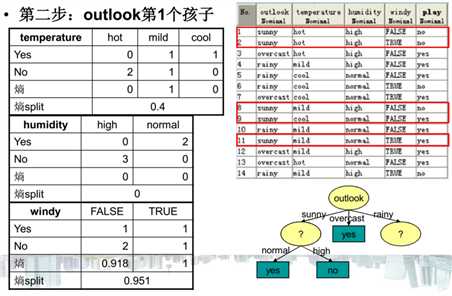
- 基于Gini指标的划分(使用于CART, SLIQ, SPRINT)当一个结点p输出k个子女时,该划分的总Gini指标计算为:ni = 子女结点i对应的记录个数,n = 结点p对应的记录个数- 基于信息的划分(ID3算法引入)结点p输出k个子女;ni 是第i个子女对应的记录个数由于划分导致熵减少;选择熵减少量最大的划分点,即信息增益最大的划分点

标签:简单的 span 计算 大数 nbsp blog c4.5 需要 类型
原文地址:http://www.cnblogs.com/Al-assad/p/7183789.html