标签:失败 over 函数式 baseline position test 移植 width file
本周课程主要是讲解了文件操作和函数的相关知识,现整理如下:
文件操作
文件操作包括以下内容:1、创建文件
2、打开文件
3、文件读取
4、文件写入
5、文件删除
6、文件指针移动
7、获取命令行
1、open()
open函数以指定模式返回一个file对象,如: file_object = open(filename,access_mode=’r’,buffering=-1),默认是以r模式打开文件。
filename:表示要打开文件名(字符串),可以是绝对路径或相对路径
access_mode:文件打开的模式(字符串), 常用的模式有’r’,’w’,’a’,不是很常用的还有’u’和’b’
‘r’模式:以读方式打开,不能进行写操作,文件必须是已经存在的
‘r+’模式:以读写方式打开,文件必须是已经存在的
‘w’模式:以写方式打开,不能进行读操作,若文件存在,则先清空,然后重新创建;若不存在,则创建文件
‘w+’模式:以读写方式打开,若文件存在,则先清空,然后重新创建;若不存在,则创建文件
‘a’模式:以追加方式打开,不能进行读操作,把数据追加到文件的末尾;若不存在,则创建文件
‘a+’模式:以读写方式打开,把数据追加到文件的末尾;若不存在,则创建文件
‘b’模式:以二进制模式打开,不能作为第一个字符出现,需跟以上模式组合使用,如’rb’,’rb+’等,
‘u’模式:表示通用换行符支持,文件必须是已经存在的
buffering:表示访问文件采用的缓冲方式,0表示不缓冲,1表示缓冲一行数据,其他大于1的值表示使用给定值作为缓冲区大小,负数表示使用系统默认缓冲机制,默认是-1,一般使用系统默认方式。
2、read()、readline()、readlines()
read():读取指定数目个字节到字符串中,负数将读取至文件末尾,默认是-1
>>> file_obj = open(‘test.txt‘,‘r‘)>>> file_obj.read()‘dfdff\n‘>>> file_obj.seek(0)>>> file_obj.read(0)‘‘>>> file_obj.read(1)‘d‘>>> file_obj.read(2)‘fd‘>>> file_obj.read(-1)‘ff\n‘>>> file_obj.seek(0)>>> file_obj.read(1000)‘dfdff\n‘>>> file_obj.seek(0)>>> file_obj.read(-5)‘dfdff\n‘>>> file_obj = open(‘test.txt‘,‘r‘)>>> file_obj.readline()‘dfdff\n‘>>> file_obj.readline(2)‘al‘>>> file_obj.readline(-1)‘exzhou\n‘>>> file_obj.seek(0)>>> file_obj.readlines()[‘dfdff\n‘, ‘alexzhou\n‘, ‘zhoujianghai\n‘]>>> file_obj = open(‘test.txt‘,‘w+‘)>>> file_obj.write(‘alexzhou‘)>>> file_obj.write(‘ python‘)>>> file_obj.seek(0)>>> file_obj.readline()‘alexzhou python‘>>> l = [‘my‘,‘name‘,‘is‘,‘zhoujianghai‘]>>> l = ‘ ‘.join(l)>>> file_obj.writelines(l)>>> file_obj.seek(0)>>> file_obj.readline()‘alexzhou pythonmy name is zhoujianghai‘>>> file_obj.write(‘hello \n‘)>>> file_obj.write(‘world \n‘)>>> file_obj.seek(0)>>> file_obj.readline()‘alexzhou pythonmy name is zhoujianghaihello \n‘>>> file_obj.readline()‘world \n‘>>> file_obj.seek(0)>>> file_obj.tell()0>>> file_obj.seek(5)>>> file_obj.tell()5 >>> file_obj.seek(5,1)>>> file_obj.tell()10>>> file_obj.seek(5,2)>>> file_obj.tell()57>>> file_obj.seek(5,0)>>> file_obj.tell()5>>> file_obj = open(‘test.txt‘,‘w+‘)>>> file_obj.write(‘hello \n‘)>>> file_obj.write(‘world \n‘)>>> file_obj.seek(0)>>> for eachline in file_obj:... print eachline,...helloworld>>> file_obj.close()>>> import os>>> os.sep‘/‘>>> os.linesep‘\n‘>>> os.pathsep‘:‘>>> os.curdir‘.‘>>> os.pardir‘..‘import sys commands = sys.argvprint commandsdef 函数名(参数): ... 函数体 ...函数的定义主要有如下要点:
def:表示函数的关键字
函数名:函数的名称,日后根据函数名调用函数
函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
参数:为函数体提供数据
返回值:当函数执行完毕后,可以给调用者返回数据。
以上要点中,比较重要有参数和返回值:
1、返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def 发送短信(): 发送短信的代码... if 发送成功: return True else: return False while True: # 每次执行发送短信函数,都会将返回值自动赋值给result # 之后,可以根据result来写日志,或重发等操作 result = 发送短信() if result == False: 记录日志,短信发送失败... |
2.参数
函数的有三中不同的参数:
普通参数
默认参数
动态参数
普通参数:
普通参数的传递并没有个数和数据类型的限制,可以传递字符串,数字,列表和字典。也不限定个数,需要注意的是:函数需要多少参数,调用的时候就要按照它定义时的顺序和数据类型传递过去。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def argtest(name,age,fruit_lst,hobby_dic): print ‘Hello,me name is %s,i\‘m %d year\‘s old‘%(name,age) print ‘My favorite fruits are : %s‘%‘.‘.join(fruit_lst) print ‘My hobbies:‘ 5 for hobby in hobby_dic: print ‘\t%s‘%hobby_dic[hobby] lst = [‘www‘,‘biyao‘,‘com‘] dic = {‘hobby one‘:‘read‘,‘hobby two‘:‘sport‘} argtest(‘Bruce‘,18,lst,dic)输出内容:Hello,me name is Bruce,i‘m 18 year‘s oldMy favorite fruits are : www.biayo.comMy hobbies: read sport |
默认参数:
默认参数是给参数加上一个默认的值,但我们调用函数的时候,如果传递了这个参数,那么使用我们传递过来的值;如果不传则使用默认的值,默认参数可以有多个,但是必须放在所有参数的最后。当我们有多个默认参数的时候,调用函数的时候可以使用参数名指定其中的某一个参数,以保证参数能准确的传递给被调用的函数。
|
1
2
3
4
5
6
7
8
9
10
|
def argvtest(argv1,argv2 = ‘aaa‘,argv3 = ‘bbb‘): print ‘argv1:‘,argv1 print ‘argv2:‘,argv2 print ‘argv3:‘,argv3 argvtest(‘a1‘,argv3 = ‘a2‘)输出的内容:argv1: a1argv2: aaaargv3: a2 |
动态参数:
def func(*args) 接受多个参数,内部自动构造元组,序列前加*,避免内部构造元组
def func(**kwargs) 接收多个参数,内部自动构造字典,序列前加**,直接传递字典
def func(*args,**kwargs):接受多个参数,既可以自动构造元组,又可以自动构造字典。
下图从左至右展示了自动构造元组,自动构造字典及前两者综合的参数传递方式:
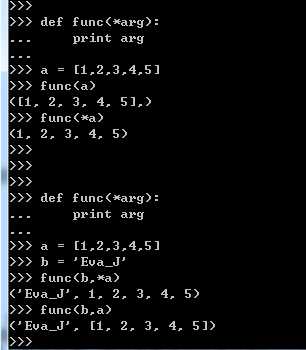
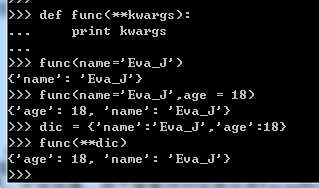
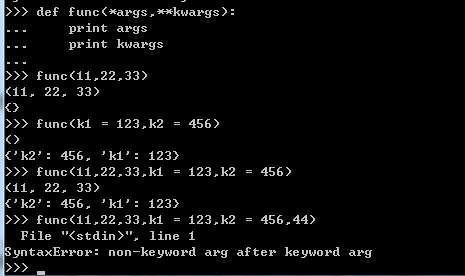
标签:失败 over 函数式 baseline position test 移植 width file
原文地址:http://www.cnblogs.com/lidaxian/p/7196867.html