标签:ret container down cin 团队 总结 产生 功能 pycha
很对人都不理解编程中的面向对象的概念,那我们先来说说面向对象的引子,由这个引子带领我们更好的理解面向对象的概念。
你现在是一家游戏公司的开发人员,现在需要你开发一款叫做<人狗大战>的游戏,你就思考呀,人狗作战,那至少需要2个角色,一个是人, 一个是狗,且人和狗都有不同的技能,比如人拿棍打狗, 狗可以咬人,怎么描述这种不同的角色和他们的功能呢?你搜罗了自己掌握的所有技能,写出了下面的代码来描述这两个角色:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def person(name,age,sex,job): data = { ‘name‘:name, ‘age‘:age, ‘sex‘:sex, ‘job‘:job } return data def dog(name,dog_type): data = { ‘name‘:name, ‘type‘:dog_type } return data |
上面两个方法相当于造了两个模子,游戏开始,你得生成一个人和狗的实际对象吧,怎么生成呢?
|
1
2
3
4
5
|
d1 = dog("李磊","京巴") p1 = person("严帅",36,"F","运维") p2 = person("林海峰",27,"F","Teacher") |
两个角色对象生成了,狗和人还有不同的功能呀,狗会咬人,人会打狗,对不对? 怎么实现呢,。。想到了, 可以每个功能再写一个函数,想执行哪个功能,直接 调用 就可以了,对不?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
def bark(d): print("dog %s:wang.wang..wang..."%d[‘name‘]) def walk(p): print("person %s is walking..." %p[‘name‘])d1 = dog("李磊","京巴")p1 = person("严帅",36,"F","运维")p2 = person("林海峰",27,"F","Teacher")walk(p1)bark(d1) |
上面的功能实现的简直是完美!但是仔细玩耍一会,你就不小心干了下面这件事:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
def person(name,age,sex,job): def walk(p): print("person %s is walking..." % p[‘name‘]) data = { ‘name‘:name, ‘age‘:age, ‘sex‘:sex, ‘job‘:job, ‘walk‘:walk } return data def dog(name,dog_type): def bark(d): print("dog %s:wang.wang..wang..."%d[‘name‘]) data = { ‘name‘:name, ‘type‘:dog_type, ‘bark‘:bark } return datad1 = dog("李磊","京巴")p1 = person("严帅",36,"F","运维")p2 = person("林海峰",27,"F","Teacher")d1[‘bark‘](p1) #把人的对象传给了狗的方法 |
你是如此的机智,这样就实现了限制人只能用人自己的功能啦。但,我的哥,不要高兴太早,刚才你只是阻止了两个完全 不同的角色 之前的功能混用, 但有没有可能 ,同一个种角色,但有些属性是不同的呢? 比如 ,大家都打过cs吧,cs里有警察和恐怖份子,但因为都 是人, 所以你写一个角色叫 person(), 警察和恐怖份子都 可以 互相射击,但警察不可以杀人质,恐怖分子可以,这怎么实现呢? 你想了说想,说,简单,只需要在杀人质的功能里加个判断,如果是警察,就不让杀不就ok了么。 没错, 这虽然 解决了杀人质的问题,但其实你会发现,警察和恐怖分子的区别还有很多,同时又有很多共性,如果 在每个区别处都 单独做判断,那得累死。
总结:需要通过面向对象的知识解决更为复杂的一些关系描述。
编程是 程序 员 用特定的语法+数据结构+算法组成的代码来告诉计算机如何执行任务的过程 , 一个程序是程序员为了得到一个任务结果而编写的一组指令的集合,正所谓条条大路通罗马,实现一个任务的方式有很多种不同的方式, 对这些不同的编程方式的特点进行归纳总结得出来的编程方式类别,即为编程范式。 不同的编程范式本质上代表对各种类型的任务采取的不同的解决问题的思路, 大多数语言只支持一种编程范式,当然也有些语言可以同时支持多种编程范式。 两种最重要的编程范式分别是面向过程编程和面向对象编程。
Procedural programming uses a list of instructions to tell the computer what to do step-by-step. 面向过程编程依赖 - 你猜到了- procedures,一个procedure包含一组要被进行计算的步骤, 面向过程又被称为top-down languages, 就是程序从上到下一步步执行,一步步从上到下,从头到尾的解决问题 。基本设计思路就是程序一开始是要着手解决一个大的问题,然后把一个大问题分解成很多个小问题或子过程,这些子过程再执行的过程再继续分解直到小问题足够简单到可以在一个小步骤范围内解决。
①举个典型的面向过程的例子, 数据库备份, 分三步,连接数据库,备份数据库,测试备份文件可用性,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def db_conn(): print("connecting db...") def db_backup(dbname): print("导出数据库...",dbname) print("将备份文件打包,移至相应目录...") def db_backup_test(): print("将备份文件导入测试库,看导入是否成功") def main(): db_conn() db_backup(‘my_db‘) db_backup_test() if __name__ == ‘__main__‘: main() |
这样做的问题也是显而易见的,就是如果你要对程序进行修改,对你修改的那部分有依赖的各个部分你都也要跟着修改, 举个例子,如果程序开头你设置了一个变量值 为1 , 但如果其它子过程依赖这个值 为1的变量才能正常运行,那如果你改了这个变量,那这个子过程你也要修改,假如又有一个其它子程序依赖这个子过程 , 那就会发生一连串的影响,随着程序越来越大, 这种编程方式的维护难度会越来越高。 所以我们一般认为, 如果你只是写一些简单的脚本,去做一些一次性任务,用面向过程的方式是极好的,但如果你要处理的任务是复杂的,且需要不断迭代和维护 的, 那还是用面向对象最方便了。
OOP(Object-Oriented Programming)编程是利用“类”和“对象”来创建各种模型来实现对真实世界的描述,使用面向对象编程的原因一方面是因为它可以使程序的维护和扩展变得更简单,并且可以大大提高程序开发效率 ,另外,基于面向对象的程序可以使它人更加容易理解你的代码逻辑,从而使团队开发变得更从容。
一个类即是对一类拥有相同属性的对象的抽象、蓝图、原型。在类中定义了这些对象的都具备的属性(variables(data))、共同的方法。
一个对象即是一个类的实例化后实例,一个类必须经过实例化后方可在程序中调用,一个类可以实例化多个对象,每个对象亦可以有不同的属性,就像人类是指所有人,每个人是指具体的对象,人与人之前有共性,亦有不同。
在类中对数据的赋值、内部调用对外部用户是透明的,这使类变成了一个胶囊或容器,里面包含着类的数据和方法。
封装的作用:
一个类可以派生出子类,在这个父类里定义的属性、方法自动被子类继承。
通过父类-->子类的方式以最小代码量的方式实现,不同角色的共同点和不同点的同时存在。
多态是面向对象的重要特性,简单点说:“一个接口,多种实现”,指一个基类中派生出了不同的子类,且每个子类在继承了同样的方法名的同时又对父类的方法做了不同的实现,这就是同一种事物表现出的多种形态。
编程其实就是一个将具体世界进行抽象化的过程,多态就是抽象化的一种体现,把一系列具体事物的共同点抽象出来, 再通过这个抽象的事物, 与不同的具体事物进行对话。
对不同类的对象发出相同的消息将会有不同的行为。比如,你的老板让所有员工在九点钟开始工作, 他只要在九点钟的时候说:“开始工作”即可,而不需要对销售人员说:“开始销售工作”,对技术人员说:“开始技术工作”, 因为“员工”是一个抽象的事物, 只要是员工就可以开始工作,他知道这一点就行了。至于每个员工,当然会各司其职,做各自的工作。
多态允许将子类的对象当作父类的对象使用,某父类型的引用指向其子类型的对象,调用的方法是该子类型的方法。这里引用和调用方法的代码编译前就已经决定了,而引用所指向的对象可以在运行期间动态绑定。
对于编程语言的初学者来讲,OOP不是一个很容易理解的编程方式,大家虽然都按老师讲的都知道OOP的三大特性是继承、封装、多态,并且大家也都知道了如何定义类、方法等面向对象的常用语法,但是一到真正写程序的时候,还是很多人喜欢用函数式编程来写代码,特别是初学者,很容易陷入一个窘境就是“我知道面向对象,我也会写类,但我依然没发现在使用了面向对象后,对我们的程序开发效率或其它方面带来什么好处,因为我使用函数编程就可以减少重复代码并做到程序可扩展了,为啥子还用面向对象?”。 对于此,我个人觉得原因应该还是因为你没有充分了解到面向对象能带来的好处,今天我就写一篇关于面向对象的入门文章,希望能帮大家更好的理解和使用面向对象编程。
无论用什么形式来编程,我们都要明确记住以下原则:
暂不考虑开发场地等复杂的东西,我们先从人物角色下手, 角色很简单,就俩个,恐怖份子、警察,他们除了角色不同,其它基本都 一样,每个人都有生命值、武器等。 咱们先用非OOP的方式写出游戏的基本角色
|
1
2
3
4
5
6
7
8
9
10
11
|
#role 1name = ‘Alex‘role = ‘terrorist‘weapon = ‘AK47‘life_value = 100 #rolw 2name2 = ‘Jack‘role2 = ‘police‘weapon2 = ‘B22‘life_value2 = 100 |
上面定义了一个恐怖份子Alex和一个警察Jack,但只2个人不好玩呀,一干就死了,没意思,那我们再分别一个恐怖分子和警察吧,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#role 1name = ‘Alex‘role = ‘terrorist‘weapon = ‘AK47‘life_value = 100money = 10000 #rolw 2name2 = ‘Jack‘role2 = ‘police‘weapon2 = ‘B22‘life_value2 = 100money2 = 10000 #role 3name3 = ‘Rain‘role3 = ‘terrorist‘weapon3 = ‘C33‘life_value3 = 100money3 = 10000 #rolw 4name4 = ‘Eric‘role4 = ‘police‘weapon4 = ‘B51‘life_value4 = 100money4 = 10000 |
4个角色虽然创建好了,但是有个问题就是,每创建一个角色,我都要单独命名,name1,name2,name3,name4…,后面的调用的时候这个变量名你还都得记着,要是再让多加几个角色,估计调用时就很容易弄混啦,所以我们想一想,能否所有的角色的变量名都是一样的,但调用的时候又能区分开分别是谁?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
roles = { 1:{‘name‘:‘Alex‘, ‘role‘:‘terrorist‘, ‘weapon‘:‘AK47‘, ‘life_value‘: 100, ‘money‘: 15000, }, 2:{‘name‘:‘Jack‘, ‘role‘:‘police‘, ‘weapon‘:‘B22‘, ‘life_value‘: 100, ‘money‘: 15000, }, 3:{‘name‘:‘Rain‘, ‘role‘:‘terrorist‘, ‘weapon‘:‘C33‘, ‘life_value‘: 100, ‘money‘: 15000, }, 4:{‘name‘:‘Eirc‘, ‘role‘:‘police‘, ‘weapon‘:‘B51‘, ‘life_value‘: 100, ‘money‘: 15000, },} print(roles[1]) #Alexprint(roles[2]) #Jack |
我们可以把每个功能写成一个函数,类似如下:
|
1
2
3
4
5
6
7
8
9
10
11
|
def shot(by_who): #开了枪后要减子弹数 passdef got_shot(who): #中枪后要减血 who[‘life_value’] -= 10 passdef buy_gun(who,gun_name): #检查钱够不够,买了枪后要扣钱 pass... |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class Role(object): def __init__(self,name,role,weapon,life_value=100,money=15000): self.name = name self.role = role self.weapon = weapon self.life_value = life_value self.money = money def shot(self): print("shooting...") def got_shot(self): print("ah...,I got shot...") def buy_gun(self,gun_name): print("just bought %s" %gun_name) r1 = Role(‘Alex‘,‘police‘,‘AK47’) #生成一个角色r2 = Role(‘Jack‘,‘terrorist‘,‘B22’) #生成一个角色 |
之前我们说关于python中的类,都一脸懵逼,都想说,类这么牛逼到底是什么,什么才是类?下面我们就来讲讲,什么是类?它具有哪些特性。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class dog(object): #用class定义类 "dog class" #对类的说明 def __init__(self,name): #构造函数或者是构造方法,也可以叫初始化方法 self.name = name def sayhi(self): #类方法 "sayhi funcation" #对类方法的说明 print("hello,i am a dog,my name is ",self.name)d = dog("alex") #定义一个d的对象,叫实例d.sayhi() #调用实例的方法 |
有很多小伙伴不禁的疑问,这个self是什么鬼?为什么在执行sayhi函数时,上面的self.name可以在函数中被调用?如下图:
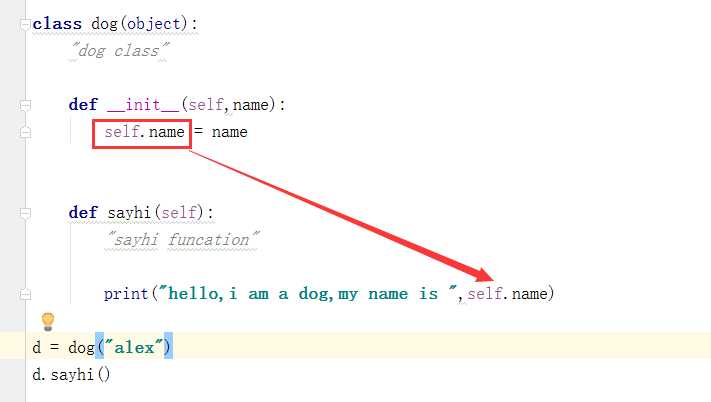
其实self 这个关键字相当于实例化对象本身(self相当于d),在实例化过程中,把自己传进去了,我们队上面的两行做一下解释:
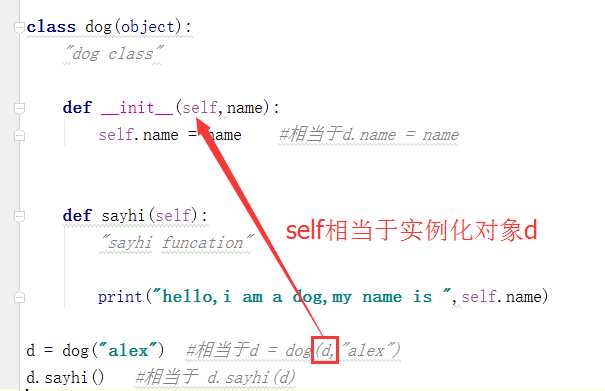
在类中__init__()函数叫构造函数,又叫构造方法,也可以叫初始化函数。它的作用就是初始化实例时,初始化传入实例的的默认值。如果不写__init__(),就会调用的默认为空的__init__(),说白了,这个方法不管你写不写,都会调用,而且,一旦实例化就会调用。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class dog(object): "dog class" def __init__(self,name): #构造方法,不写调用默认的构造方法 self.name = name def eat(self,food): print("the dog name is {0},it like food is {1}".format(self.name,food))d = dog("alex")d.eat("hotdog")#输出the dog name is alex,it like food is hotdog |
最后我们画一个图,来说明一下实话过程的图,不然真的很难理解这个玩意:
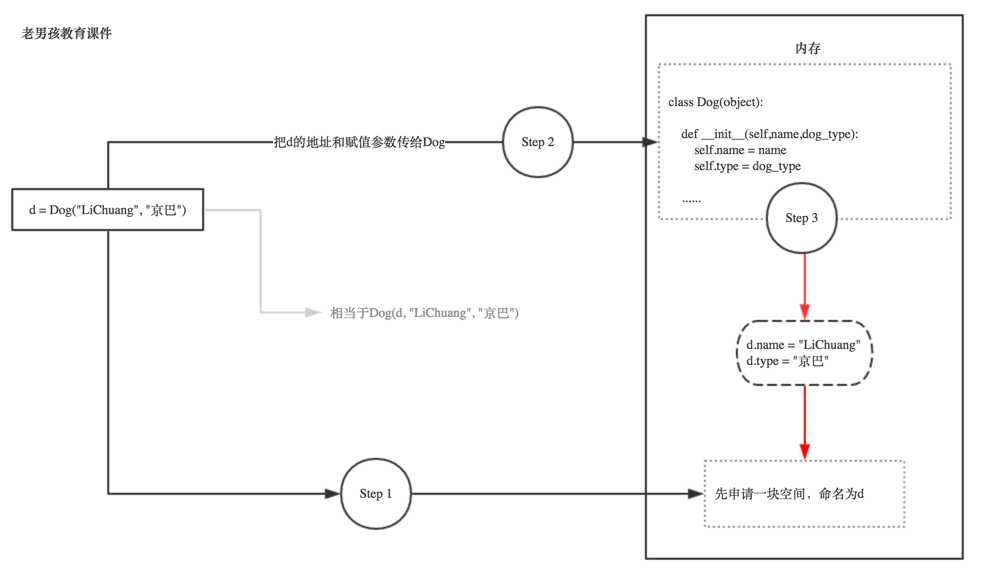
由上图可知:其实self,就是实例本身!你实例化时python会自动把这个实例本身通过self参数传进去。
在上篇博客中我们已经讲了一些关于类的知识,我们来回顾以下:
下面我们继续学习类的特性。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class dog(object): "dog class" def __init__(self,name): self.name = name #类的成员变量 def sayhi(self): print("the dog {0} is sayhi".format(self.name)) def eat(self,food): #传入一个参数,参数名:food print("the dog name is {0},it like food is {1}".format(self.name,food))d = dog("alex") #实例化对象d.sayhi() #调sayhi方法d.eat("hotdog") #调eat方法#输出the dog alex is sayhithe dog name is alex,it like food is hotdog |
①很多人产生疑问,为什么eat方法里面会传入一个food的参数名呢?而这个为什么不能再其他方法里面用呢?而self.name就可以呢?
因为food它只是作为eat方法的一个参数,不是类的成员变量,只能在自己的方法里面使用,而self.name是类的成员变量,它是类的属性,所以可以被调用。
②为什么类的每一个方法第一个参数都是self呢?
是因为类在实例化的时候,需要把实例对象本身传进来,好去调用对象本身的属性和方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class dog(object): "dog class" def __init__(self,name,age): self.name = name self.age = age def sayhi(self,update_age): #传入一个update_age参数 self.age = update_age #修改对象的age属性d = dog("alex",18)d.sayhi(22) #第1次在类的方法中修改print(d.age) d.age = 19 #第2次在类外面修改print(d.age)#输出2219 |
注:就是说在类的方法中或者类的外面都可以修改类的属性
说明:之前我们说,我们可以访问类的属性,也可以随意修改类的属性,但是类属性一旦被定义成私有的,对外是不可以被访问的,也是不可以随意被改变的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class dog(object): "dog class" def __init__(self,name,age): self.name = name self.age = age self.__sex = "man" #定义私有属性__sex def sayhi(self,update_age): self.age = update_aged = dog("alex",18)print(d.__sex) #访问私有属性__sex#输出Traceback (most recent call last): File "E:/PycharmProjects/pythontest/day6/封装.py", line 16, in <module> print(d.__sex)AttributeError: ‘dog‘ object has no attribute ‘__sex‘ #报错,说没有__sex这个属性 |
从上面的例子可以看出,私有属性是不可以访问的,更不可以修改。但是我们就想访问,但是不去修改,我们怎么办呢?
虽然我们外部不能访问私有属性,但是我们在类内部可以访问私有属性,所以我们用如下方法,访问私有属性
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class dog(object): "dog class" def __init__(self,name): self.name = name self.__sex = "man" #定义私有属性sex def get_sex(self): #定义get方法 return self.__sex #返回私有属性sex值d = dog("alex")d_sex = d.get_sex() #调用实例对象d的get_sex()方法获取私有属性sexprint(d_sex)#输出man |
注:这种方法只能访问私有属性,但是不能更改私有属性
上面的方法只能访问,但是不能修改,下面这种方法就更为暴力,可以访问也可以修改,就是:对象名._类名__属性名
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
class dog(object): "dog class" def __init__(self,name): self.name = name self.__sex = "man" #定义私有方法sexd = dog("alex")print(d._dog__sex) #访问私有属性sexd._dog__sex = "woman" #修改私有属性sexprint(d._dog__sex) #打印修改后的值#输出manwoman |
def get_sex(self):
return self.__sex
标签:ret container down cin 团队 总结 产生 功能 pycha
原文地址:http://www.cnblogs.com/luoahong/p/7207801.html