标签:阈值 系统 观察 便宜 规则 相关 inpu 独立 分离
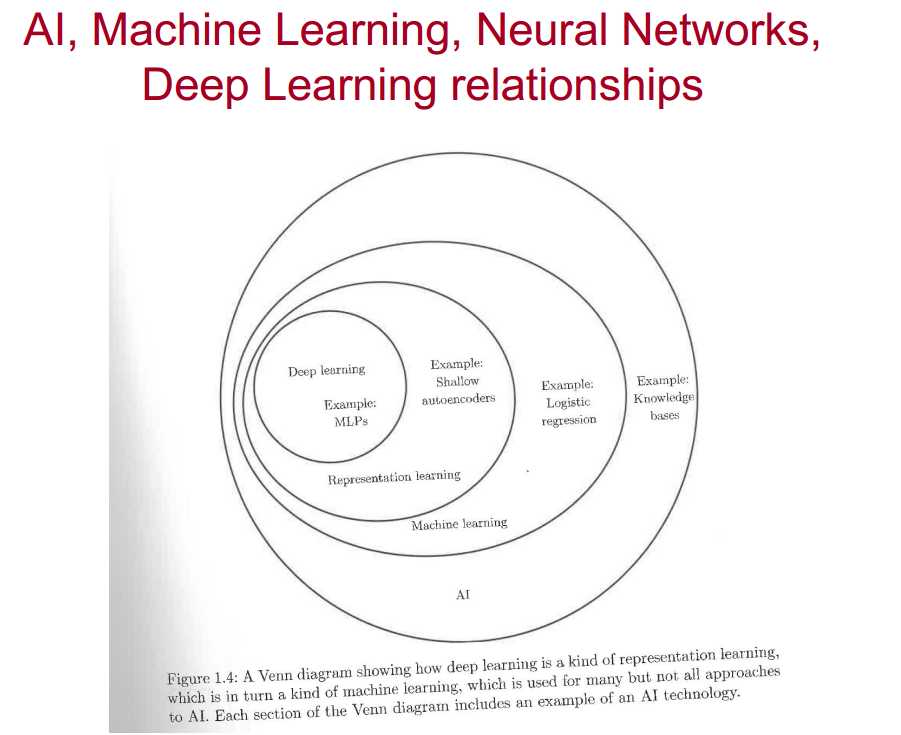
前言 WHY?AI是从策略出发,简单可描述(可以用清晰的规则和算法取实现)的任务,让机器去执行。我们希望复杂难以描述的任务(如无人驾驶,语音识别等情况复杂,需要推理和抽象化的任务)也可以由机器去实现,ML/DL是从数据驱动出发。数据挖掘、模式识别、机器学习和神经网络都是用来解决这些复杂的情况下的任务(几者之间互相联系,相关关联,甚至区别不大)。
一、模式识别

解决问题:如何让机器做与人感知相关的任务?认知模型、区分模式,从而形成正确的判决(聚类与系统推荐)
①类人的观察②感知环境中感兴趣的部分(特征抽取与整合)③作出与人推理相近的判决。
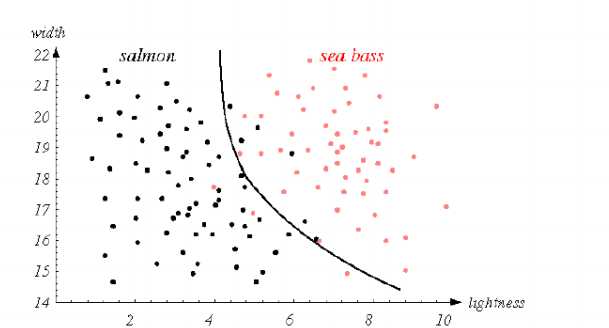
举例:如何区分两种鱼?
典型的决策机制
特征选择
我们知道两种鱼的长度一般不一样,可以作为区分的特征,需要选择长度的阈值,同时,我们也可以看到一般鱼的长度是不一样,但是并不是严格不同,即长度不能完全区分两种鱼,此时我们考虑尝试其他的特征。机器学习中①并不存在单一特征可以区分类别,采用多个特征进行组合分析(整个情况就更加复杂)②假定各个特征之间独立,尽可能选择特征之间互相独立的特征(避免相关性,但是往往实际中,特征之间是相关的,如身高和体重),尽可能考虑多的特征。
特征维数变多出现的问题:一是模型更加复杂(容易过拟合)。二是学习的效率下降。
期望提取的特征:能够区分类别,选择好的特征能够正确区分类别(差的特征可能无法区别类别)
特征提取的方法有两种:一种是Feature extraction 即特征映射?通过函数映射到新的特征空间,新的特征空间采用矢量表示特征,可以体现或者容易比较两者(两者只类别还是特征之间呢?)之间的相关性。另一种是特征选择,在若干特征中选择一部分。
tradeoff:依据判别结果所付出的代价对模型进行调整(例如:salmon的价格高于sea bass时,我们把分类曲线往左移,那么对于salmon的判断基本不会出错,不会发生顾客用高价钱买到的却是sea bass,不会有上当受骗的嫌疑。有可能使用低价钱买到salmon(salmon被判定为sea bass时),这个时候顾客就会很高兴,下次会继续过来这里买鱼,即我们希望salmon的正确率一定要保证)
模型好坏的度量:
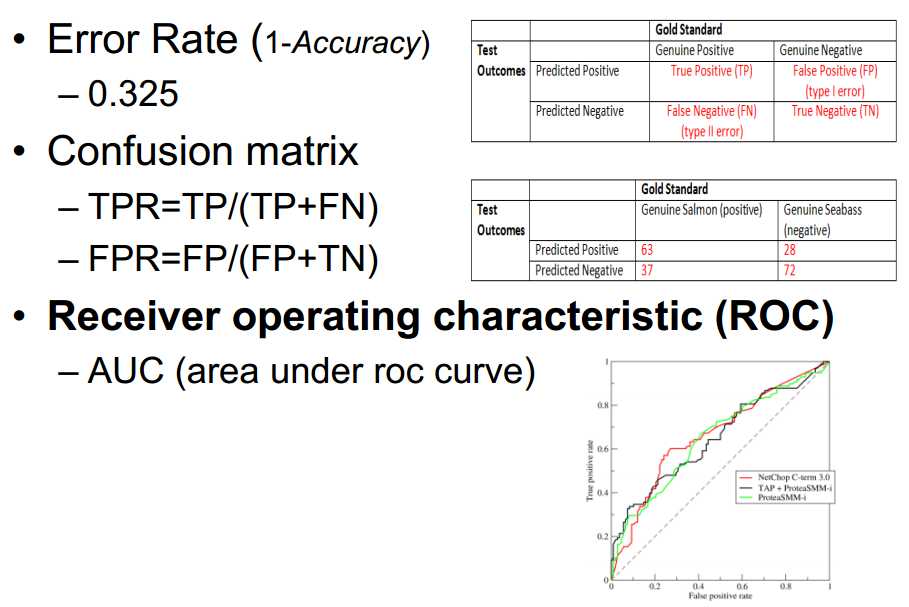
(ROC与AUC?)
二、机器学习
机器可以替代人的技能

机器学习是使用大量数据去学习模型。机器考虑特征与结果的相关性比人要好,人可以考虑影响结果的2到3个特征,机器可以考虑很多个影响因素。
为什么用机器学习?从特定的样例中学习数据的一般模型,数据丰富且便宜,知识少而昂贵。建立一个模型去很好并且有效的近似数据
机器学习模型:
1、监督学习(决策树、前向神经网络和反向传播) 有监督模型的优点是提供标签,准确率高。
2、无监督学习(聚类、关联分析) 无监督学习不需要标签,所以数据数量可以很大很大,优点是适用大数据。
3、Reinforcement learning http://www.cse.unsw.edu.au/~cs9417ml/RL1/applet.html
机器学习的输出:

三、神经网络
神经元
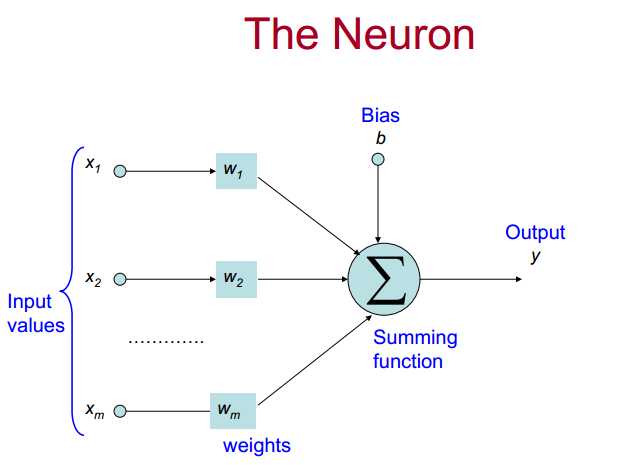
神经网络
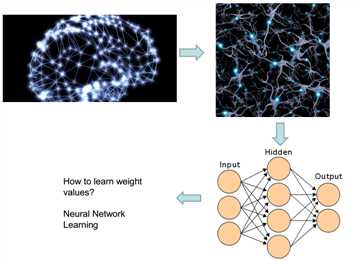
神经网路主要是学习权重,怎么样得到好的权重去完成任务(怎么修改权重?谁先改?)。生物依据,只是概念上一样,功能上并不同。同一层之间不相连接,彼此之间改变互不影响,模型简单。隐藏层(hidden):我们不能确定它应该输出是怎么样,不能预测它真实的输出。输入和输出是可以得到预测的输入与输出,并且可以与真实的输出进行对比。

Why Deep Learning?
Deep Learning可以通过input对每一层学习得到的进行解释,隐藏层可以解释(如某一层表示边缘,即每一层都有一定的归结,DL往往每一层可以表示出来,区分DL与传统NN的区别)
区别与关系
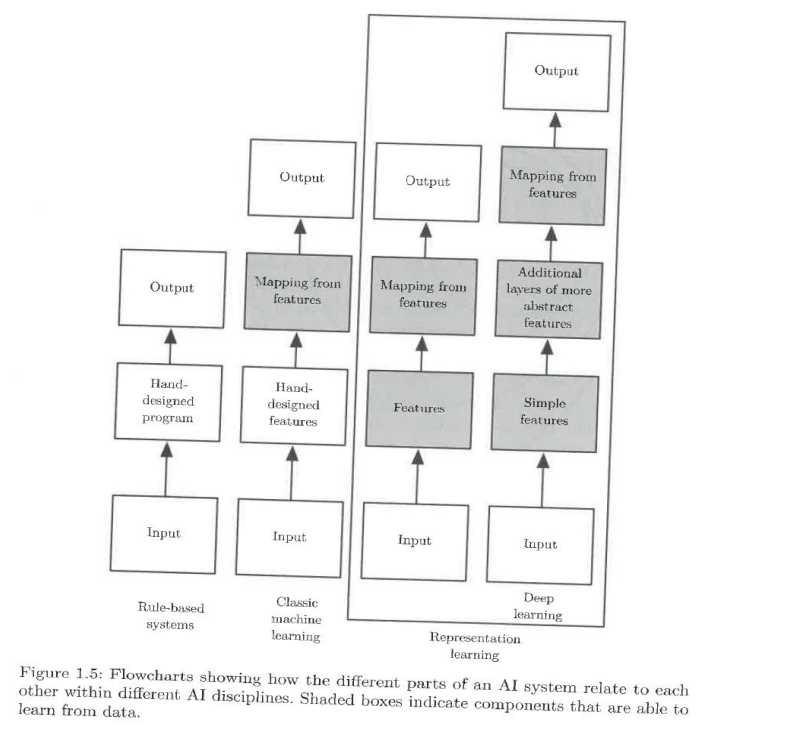
原来知道哪些特征好,就用那些特征,现在不知道,让它自己学习哪些特征好(特征 → 学习新的特征)。
标签:阈值 系统 观察 便宜 规则 相关 inpu 独立 分离
原文地址:http://www.cnblogs.com/betterforever/p/7206721.html