标签:cto 处理 百度 属性 print 读取 帐号 version point
在爬取之前需要在浏览器先登录百度贴吧的帐号,各位也可以在代码中使用post提交或者加入cookie
爬行地址:http://tieba.baidu.com/f?kw=%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=0
#-*- coding:utf-8 -*-
import urllib2
import re
import requests
from lxml import etree
这些是要导入的库,代码并没有使用正则,使用的是xpath,正则困难的童鞋可以尝试使用下
推荐各位先使用基本库来写,这样可以学习到更多
links=[] #遍历url的地址
k=1
print u‘请输入最后的页数:‘
endPage=int(raw_input()) #最终的页数 (r‘\d+(?=\s*页) 这是一个比较通用的正则抓取总页数的代码,当然最后要group
#这里是手动输入页数,避免内容太多
for j in range(0,endPage):
url=‘http://tieba.baidu.com/f?kw=%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=‘+str(j) #页数的url地址
html=urllib2.urlopen(url).read() #读取首页的内容
selector=etree.HTML(html) #转换为xml,用于在接下来识别
links=selector.xpath(‘//div/a[@class="j_th_tit"]/@href‘) #抓取当前页面的所有帖子的url
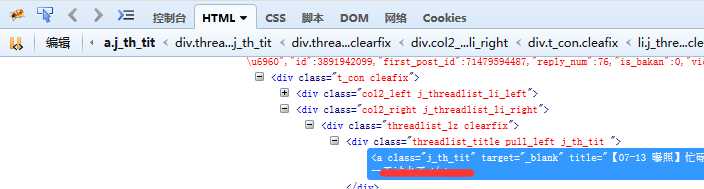
#大家可以使用浏览器自带的源码查看工具,在指定目标处查看元素,这样更快捷
for i in links:
url1="http://tieba.baidu.com"+i #因为爬取到的地址是相对地址,所以要加上百度的domain
html2=urllib2.urlopen(url1).read() #读取当前页面的内容
selector=etree.HTML(html2) #转换为xml用于识别
link=selector.xpath(‘//img[@class="BDE_Image"]/@src‘) #抓取图片,各位也可以更换为正则,或者其他你想要的内容
#此处就是遍历下载
for each in link:
#print each
print u‘正在下载%d‘%k
fp=open(‘image/‘+str(k)+‘.bmp‘,‘wb‘) #下载在当前目录下 image文件夹内,图片格式为bmp
image1=urllib2.urlopen(each).read() #读取图片的内容
fp.write(image1) #写入图片
fp.close()
k+=1 #k就是文件的名字,每下载一个文件就加1
print u‘下载完成!‘
如果想要爬取其他站点的内容,大家可以参考一下
测试版本python2.7,
参考xpath文档
简单了解一下xpath:
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
因此,对 XPath 的理解是很多高级 XML 应用的基础。
这个是w3c上关于xpath的介绍,可以看出xpath是在xml文档中查询信息的语言
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
根节点在xpath中可以用“//”来啊表示
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
接下来一个例子
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book> <title lang="eng">Harry Potter</title> <price>29.99</price> </book> <book> <title lang="eng">Learning XML</title> <price>39.95</price> </book> </bookstore>
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=‘eng‘] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price |
选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
这些就是xpath的语法内容
在运用到python抓取时要先转换为xml
Import lxml #首先要先导入库
etree.HTML() #这个就是转换为xml的python的语法,HTML括号内填入目标站点的源码,
标签:cto 处理 百度 属性 print 读取 帐号 version point
原文地址:http://www.cnblogs.com/onemorepoint/p/7217525.html