标签:防止 优点 可扩展 sax dev erro 空格 技术分享 有趣
XML 文档形成了一种树结构,它从"根部"开始,然后扩展到"枝叶"。
XML 文档使用简单的具有自我描述性的语法:
第一行是 XML 声明。它定义 XML 的版本(1.0)和所使用的编码(UTF-8 : 万国码, 可显示各种语言)。
下一行描述文档的根元素(像在说:"本文档是一个便签"):
<note>
接下来 4 行描述根的 4 个子元素(to, from, heading 以及 body):
最后一行定义根元素的结尾:
</note>
您可以假设,从这个实例中,XML 文档包含了一张 Jani 写给 Tove 的便签。
XML 具有出色的自我描述性,您同意吗?
XML 文档必须包含根元素。该元素是所有其他元素的父元素。
XML 文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。
所有的元素都可以有子元素:
父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞(兄弟或姐妹)。
所有的元素都可以有文本内容和属性(类似 HTML 中)。
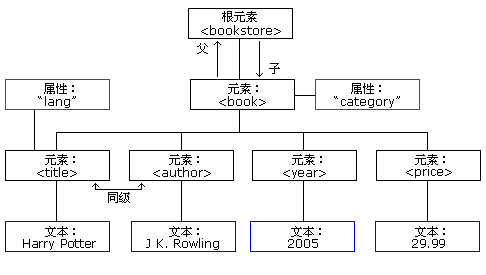
上图表示下面的 XML 中的一本书:
实例中的根元素是 <bookstore>。文档中的所有 <book> 元素都被包含在 <bookstore> 中。
<book> 元素有 4 个子元素:<title>、<author>、<year>、<price>。
XML 的语法规则很简单,且很有逻辑。这些规则很容易学习,也很容易使用。
XML 必须包含根元素,它是所有其他元素的父元素,比如以下实例中 root 就是根元素:
以下实例中 note 是根元素:
XML 声明文件的可选部分,如果存在需要放在文档的第一行,如下所示:
<?xml version="1.0" encoding="utf-8"?>
以上实例包含 XML 版本(<version="1.0"),甚至包含字符编码(encoding="utf-8")。< p="">
UTF-8 也是 HTML5, CSS, JavaScript, PHP, 和 SQL 的默认编码。
在 HTML 中,某些元素不必有一个关闭标签:
<p>This is a paragraph.
<br>
在 XML 中,省略关闭标签是非法的。所有元素都必须有关闭标签:
<p>This is a paragraph.</p>
<br />
注释:从上面的实例中,您也许已经注意到 XML 声明没有关闭标签。这不是错误。声明不是 XML 文档本身的一部分,它没有关闭标签。
XML 标签对大小写敏感。标签 <Letter> 与标签 <letter> 是不同的。
必须使用相同的大小写来编写打开标签和关闭标签:
<Message>这是错误的</message>
<message>这是正确的</message>
注释:打开标签和关闭标签通常被称为开始标签和结束标签。不论您喜欢哪种术语,它们的概念都是相同的。
在 HTML 中,常会看到没有正确嵌套的元素:
<b><i>This text is bold and italic</b></i>
在 XML 中,所有元素都必须彼此正确地嵌套:
<b><i>This text is bold and italic</i></b>
在上面的实例中,正确嵌套的意思是:由于 <i> 元素是在 <b> 元素内打开的,那么它必须在 <b> 元素内关闭。
与 HTML 类似,XML 元素也可拥有属性(名称/值的对)。
在 XML 中,XML 的属性值必须加引号。
请研究下面的两个 XML 文档。 第一个是错误的,第二个是正确的:
<note date=12/11/2007>
<to>Tove</to>
<from>Jani</from>
</note>
<note date="12/11/2007">
<to>Tove</to>
<from>Jani</from>
</note>
在第一个文档中的错误是,note 元素中的 date 属性没有加引号。
在 XML 中,一些字符拥有特殊的意义。
如果您把字符 "<" 放在 XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。
这样会产生 XML 错误:
<message>if salary < 1000 then</message>
为了避免这个错误,请用实体引用来代替 "<" 字符:
<message>if salary < 1000 then</message>
在 XML 中,有 5 个预定义的实体引用:
| < | < | less than |
| > | > | greater than |
| & | & | ampersand |
| ' | ‘ | apostrophe |
| " | " | quotation mark |
注释:在 XML 中,只有字符 "<" 和 "&" 确实是非法的。大于号是合法的,但是用实体引用来代替它是一个好习惯。
在 XML 中编写注释的语法与 HTML 的语法很相似。
<!-- This is a comment -->
HTML 会把多个连续的空格字符裁减(合并)为一个:
| HTML: | Hello Tove |
| Output: | Hello Tove |
在 XML 中,文档中的空格不会被删减。
在 Windows 应用程序中,换行通常以一对字符来存储:回车符(CR)和换行符(LF)。
在 Unix 和 Mac OSX 中,使用 LF 来存储新行。
在旧的 Mac 系统中,使用 CR 来存储新行。
XML 以 LF 存储换行。
XML 文档包含 XML 元素。
XML 元素指的是从(且包括)开始标签直到(且包括)结束标签的部分。
一个元素可以包含:
在上面的实例中,<bookstore> 和 <book> 都有 元素内容,因为他们包含其他元素。<book> 元素也有属性(category="CHILDREN")。<title>、<author>、<year> 和 <price> 有文本内容,因为他们包含文本。
XML 元素必须遵循以下命名规则:
可使用任何名称,没有保留的字词。
使名称具有描述性。使用下划线的名称也很不错:<first_name>、<last_name>。
名称应简短和简单,比如:<book_title>,而不是:<the_title_of_the_book>。
避免 "-" 字符。如果您按照这样的方式进行命名:"first-name",一些软件会认为您想要从 first 里边减去 name。
避免 "." 字符。如果您按照这样的方式进行命名:"first.name",一些软件会认为 "name" 是对象 "first" 的属性。
避免 ":" 字符。冒号会被转换为命名空间来使用(稍后介绍)。
XML 文档经常有一个对应的数据库,其中的字段会对应 XML 文档中的元素。有一个实用的经验,即使用数据库的命名规则来命名 XML 文档中的元素。
在 XML 中,éòá 等非英语字母是完全合法的,不过需要留意,您的软件供应商不支持这些字符时可能出现的问题。
XML 元素是可扩展,以携带更多的信息。
请看下面的 XML 实例:
让我们设想一下,我们创建了一个应用程序,可将 <to>、<from> 以及 <body> 元素从 XML 文档中提取出来,并产生以下的输出:
| MESSAGE
To: Tove Don‘t forget me this weekend! |
想象一下,XML 文档的作者添加的一些额外信息:
那么这个应用程序会中断或崩溃吗?
不会。这个应用程序仍然可以找到 XML 文档中的 <to>、<from> 以及 <body> 元素,并产生同样的输出。
XML 的优势之一,就是可以在不中断应用程序的情况下进行扩展。
XML元素具有属性,类似 HTML。
属性(Attribute)提供有关元素的额外信息。
在 HTML 中,属性提供有关元素的额外信息:
属性通常提供不属于数据组成部分的信息。在下面的实例中,文件类型与数据无关,但是对需要处理这个元素的软件来说却很重要:
属性值必须被引号包围,不过单引号和双引号均可使用。比如一个人的性别,person 元素可以这样写:
或者这样也可以:
如果属性值本身包含双引号,您可以使用单引号,就像这个实例:
或者您可以使用字符实体:
请看这些实例:
在第一个实例中,sex 是一个属性。在第二个实例中,sex 是一个元素。这两个实例都提供相同的信息。
没有什么规矩可以告诉我们什么时候该使用属性,而什么时候该使用元素。我的经验是在 HTML 中,属性用起来很便利,但是在 XML 中,您应该尽量避免使用属性。如果信息感觉起来很像数据,那么请使用元素吧。
下面的三个 XML 文档包含完全相同的信息:
第一个实例中使用了 date 属性:
第二个实例中使用了 date 元素:
第三个实例中使用了扩展的 date 元素(这是我的最爱):
因使用属性而引起的一些问题:
属性难以阅读和维护。请尽量使用元素来描述数据。而仅仅使用属性来提供与数据无关的信息。
不要做这样的蠢事(这不是 XML 应该被使用的方式):
有时候会向元素分配 ID 引用。这些 ID 索引可用于标识 XML 元素,它起作用的方式与 HTML 中 id 属性是一样的。这个实例向我们演示了这种情况:
上面的 id 属性仅仅是一个标识符,用于标识不同的便签。它并不是便签数据的组成部分。
在此我们极力向您传递的理念是:元数据(有关数据的数据)应当存储为属性,而数据本身应当存储为元素。
拥有正确语法的 XML 被称为"形式良好"的 XML。
通过 DTD 验证的XML是"合法"的 XML。
"形式良好"的 XML 文档拥有正确的语法。
在前面的章节描述的语法规则:
合法的 XML 文档是"形式良好"的 XML 文档,这也符合文档类型定义(DTD)的规则:
在上面的实例中,DOCTYPE 声明是对外部 DTD 文件的引用。下面的段落展示了这个文件的内容。
DTD 的目的是定义 XML 文档的结构。它使用一系列合法的元素来定义文档结构:
如果您想要学习 DTD,请在我们的首页查找 DTD 教程。
W3C 支持一种基于 XML 的 DTD 代替者,它名为 XML Schema:
http://www.runoob.com/xml/xml-tutorial.html
文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。
一个 DOM 的解析器在解析一个 XML 文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后你可以利用DOM 提供的不同的函数来读取或修改文档的内容和结构,也可以把修改过的内容写入xml文件。
python中用xml.dom.minidom来解析xml文件,实例如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from xml.dom.minidom import parse
import xml.dom.minidom
# 使用minidom解析器打开 XML 文档
DOMTree = xml.dom.minidom.parse("movies.xml")
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print "Root element : %s" % collection.getAttribute("shelf")
# 在集合中获取所有电影
movies = collection.getElementsByTagName("movie")
# 打印每部电影的详细信息
for movie in movies:
print "*****Movie*****"
if movie.hasAttribute("title"):
print "Title: %s" % movie.getAttribute("title")
type = movie.getElementsByTagName(‘type‘)[0]
print "Type: %s" % type.childNodes[0].data
format = movie.getElementsByTagName(‘format‘)[0]
print "Format: %s" % format.childNodes[0].data
rating = movie.getElementsByTagName(‘rating‘)[0]
print "Rating: %s" % rating.childNodes[0].data
description = movie.getElementsByTagName(‘description‘)[0]
print "Description: %s" % description.childNodes[0].data
以上程序执行结果如下:
Root element : New Arrivals *****Movie***** Title: Enemy Behind Type: War, Thriller Format: DVD Rating: PG Description: Talk about a US-Japan war *****Movie***** Title: Transformers Type: Anime, Science Fiction Format: DVD Rating: R Description: A schientific fiction *****Movie***** Title: Trigun Type: Anime, Action Format: DVD Rating: PG Description: Vash the Stampede! *****Movie***** Title: Ishtar Type: Comedy Format: VHS Rating: PG Description: Viewable boredom
原文: http://eli.thegreenplace.net/2012/03/15/processing-xml-in-python-with-elementtree/
译者: TheLover_Z
当你需要解析和处理 XML 的时候,Python 表现出了它 “batteries included” 的一面。 标准库 中大量可用的模块和工具足以应对 Python 或者是 XML 的新手。
几个月前在 Python 核心开发者之间发生了一场 有趣的讨论 ,他们讨论了 Python 下可用的 XML 处理工具的优点,还有如何将它们最好的展示给用户看。这篇文章是我本人的拙作,我打算讲讲哪些工具比较好用还有为什么它们好用,当然,这篇文章也可以当作一个如何使用的基础教程来看。
这篇文章所使用的代码基于 Python 2.7,你稍微改动一下就可以在 Python 3.x 上面使用了。
Python 有非常非常多的工具来处理 XML。在这个部分我想对 Python 所提供的包进行一个简单的浏览,并且解释为什么 ElementTree 是你最应该用的那一个。
xml.dom.* 模块 - 是 W3C DOM API 的实现。如果你有处理 DOM API 的需要,那么这个模块适合你。注意:在 xml.dom 包里面有许多模块,注意它们之间的不同。
xml.sax.* 模块 - 是 SAX API 的实现。这个模块牺牲了便捷性来换取速度和内存占用。SAX 是一个基于事件的 API,这就意味着它可以“在空中”(on the fly)处理庞大数量的的文档,不用完全加载进内存(见注释1)。
xml.parser.expat - 是一个直接的,低级一点的基于 C 的 expat 的语法分析器(见注释2)。 expat 接口基于事件反馈,有点像 SAX 但又不太像,因为它的接口并不是完全规范于 expat 库的。
最后,我们来看看 xml.etree.ElementTree (以下简称 ET)。它提供了轻量级的 Python 式的 API ,它由一个 C 实现来提供。相对于 DOM 来说,ET 快了很多(见注释3)而且有很多令人愉悦的 API 可以使用。相对于 SAX 来说,ET 也有 ET.iterparse 提供了 “在空中” 的处理方式,没有必要加载整个文档到内存。ET 的性能的平均值和 SAX 差不多,但是 API 的效率更高一点而且使用起来很方便。我一会儿会给你们看演示。
我的建议 是尽可能的使用 ET 来处理 XML ,除非你有什么非常特别的需要。
ElementTree 生来就是为了处理 XML ,它在 Python 标准库中有两种实现。一种是纯 Python 实现例如 xml.etree.ElementTree ,另外一种是速度快一点的 xml.etree.cElementTree 。你要记住: 尽量使用 C 语言实现的那种,因为它速度更快,而且消耗的内存更少。如果你的电脑上没有 _elementtree (见注释4) 那么你需要这样做:
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
这是一个让 Python 不同的库使用相同 API 的一个比较常用的办法。还是那句话,你的编译环境和别人的很可能不一样,所以这样做可以防止一些莫名其妙的小问题。注意:从 Python 3.3 开始,你没有必要这么做了,因为 ElementTree 模块会自动寻找可用的 C 库来加快速度。所以只需要 import xml.etree.ElementTree 就可以了。但是在 3.3 正式推出之前,你最好还是使用我上面提供的那段代码。
我们来讲点基础的。XML 是一种分级的数据形式,所以最自然的表示方法是将它表示为一棵树。ET 有两个对象来实现这个目的 - ElementTree 将整个 XML 解析为一棵树, Element 将单个结点解析为树。如果是整个文档级别的操作(比如说读,写,找到一些有趣的元素)通常用 ElementTree 。单个 XML 元素和它的子元素通常用 Element 。下面的例子能说明我刚才啰嗦的一大堆。(见注释5)
我们用这个 XML 文件来做例子:
<?xml version="1.0"?>
<doc>
<branch name="testing" hash="1cdf045c">
text,source
</branch>
<branch name="release01" hash="f200013e">
<sub-branch name="subrelease01">
xml,sgml
</sub-branch>
</branch>
<branch name="invalid">
</branch>
</doc>
让我们加载并且解析这个 XML :
>>> import xml.etree.cElementTree as ET
>>> tree = ET.ElementTree(file=‘doc1.xml‘)
然后抓根结点元素:
>>> tree.getroot()
<Element ‘doc‘ at 0x11eb780>
和预期一样,root 是一个 Element 元素。我们可以来看看:
>>> root = tree.getroot()
>>> root.tag, root.attrib
(‘doc‘, {})
看吧,根元素没有任何状态(见注释6)。就像任何 Element 一样,它可以找到自己的子结点:
>>> for child_of_root in root:
... print child_of_root.tag, child_of_root.attrib
...
branch {‘hash‘: ‘1cdf045c‘, ‘name‘: ‘testing‘}
branch {‘hash‘: ‘f200013e‘, ‘name‘: ‘release01‘}
branch {‘name‘: ‘invalid‘}
我们也可以进入一个指定的子结点:
>>> root[0].tag, root[0].text
(‘branch‘, ‘\n text,source\n ‘)
从上面的例子我们可以轻而易举的看到,我们可以用一个简单的递归获取 XML 中的任何元素。然而,因为这个操作比较普遍,ET 提供了一些有用的工具来简化操作.
Element 对象有一个 iter 方法可以对子结点进行深度优先遍历。 ElementTree 对象也有 iter 方法来提供便利。
>>> for elem in tree.iter():
... print elem.tag, elem.attrib
...
doc {}
branch {‘hash‘: ‘1cdf045c‘, ‘name‘: ‘testing‘}
branch {‘hash‘: ‘f200013e‘, ‘name‘: ‘release01‘}
sub-branch {‘name‘: ‘subrelease01‘}
branch {‘name‘: ‘invalid‘}
遍历所有的元素,然后检验有没有你想要的。ET 可以让这个过程更便捷。 iter 方法接受一个标签名字,然后只遍历那些有指定标签的元素:
>>> for elem in tree.iter(tag=‘branch‘):
... print elem.tag, elem.attrib
...
branch {‘hash‘: ‘1cdf045c‘, ‘name‘: ‘testing‘}
branch {‘hash‘: ‘f200013e‘, ‘name‘: ‘release01‘}
branch {‘name‘: ‘invalid‘}
为了寻找我们感兴趣的元素,一个更加有效的办法是使用 XPath 支持。 Element 有一些关于寻找的方法可以接受 XPath 作为参数。 find 返回第一个匹配的子元素, findall 以列表的形式返回所有匹配的子元素, iterfind 为所有匹配项提供迭代器。这些方法在 ElementTree 里面也有。
给出一个例子:
>>> for elem in tree.iterfind(‘branch/sub-branch‘):
... print elem.tag, elem.attrib
...
sub-branch {‘name‘: ‘subrelease01‘}
这个例子在 branch 下面找到所有标签为 sub-branch 的元素。然后给出如何找到所有的 branch 元素,用一个指定 name 的状态即可:
>>> for elem in tree.iterfind(‘branch[@name="release01"]‘):
... print elem.tag, elem.attrib
...
branch {‘hash‘: ‘f200013e‘, ‘name‘: ‘release01‘}
想要深入学习 XPath 的话,请看 这里 。
ET 提供了建立 XML 文档和写入文件的便捷方式。 ElementTree 对象提供了 write 方法。
现在,这儿有两个常用的写 XML 文档的脚本。
修改文档可以使用 Element 对象的方法:
>>> root = tree.getroot()
>>> del root[2]
>>> root[0].set(‘foo‘, ‘bar‘)
>>> for subelem in root:
... print subelem.tag, subelem.attrib
...
branch {‘foo‘: ‘bar‘, ‘hash‘: ‘1cdf045c‘, ‘name‘: ‘testing‘}
branch {‘hash‘: ‘f200013e‘, ‘name‘: ‘release01‘}
我们在这里删除了根元素的第三个子结点,然后为第一个子结点增加新状态。然后这个树可以写回到文件中。
>>> import sys
>>> tree.write(sys.stdout) # ET.dump can also serve this purpose
<doc>
<branch foo="bar" hash="1cdf045c" name="testing">
text,source
</branch>
<branch hash="f200013e" name="release01">
<sub-branch name="subrelease01">
xml,sgml
</sub-branch>
</branch>
</doc>
注意状态的顺序和原文档的顺序不太一样。这是因为 ET 讲状态保存在无序的字典中。语义上来说,XML 并不关心顺序。
建立一个全新的元素也很容易。ET 模块提供了 SubElement 函数来简化过程:
>>> a = ET.Element(‘elem‘)
>>> c = ET.SubElement(a, ‘child1‘)
>>> c.text = "some text"
>>> d = ET.SubElement(a, ‘child2‘)
>>> b = ET.Element(‘elem_b‘)
>>> root = ET.Element(‘root‘)
>>> root.extend((a, b))
>>> tree = ET.ElementTree(root)
>>> tree.write(sys.stdout)
<root><elem><child1>some text</child1><child2 /></elem><elem_b /></root>
就像我在文章一开头提到的那样,XML 文档通常比较大,所以将它们全部读入内存的库可能会有点儿小问题。这也是为什么我建议使用 SAX API 来替代 DOM 。
我们刚讲过如何使用 ET 来将 XML 读入内存并且处理。但它就不会碰到和 DOM 一样的内存问题么?当然会。这也是为什么这个包提供一个特殊的工具,用来处理大型文档,并且解决了内存问题,这个工具叫 iterparse 。
我给大家演示一个 iterparse 如何使用的例子。我用 自动生成 拿到了一个 XML 文档来进行说明。这只是开头的一小部分:
<?xml version="1.0" standalone="yes"?>
<site>
<regions>
<africa>
<item id="item0">
<location>United States</location> <!-- Counting locations -->
<quantity>1</quantity>
<name>duteous nine eighteen </name>
<payment>Creditcard</payment>
<description>
<parlist>
[...]
我已经用注释标出了我要处理的元素,我们用一个简单的脚本来计数有多少 location 元素并且文本内容为“Zimbabwe”。这是用 ET.parse 的一个标准的写法:
tree = ET.parse(sys.argv[2])
count = 0
for elem in tree.iter(tag=‘location‘):
if elem.text == ‘Zimbabwe‘:
count += 1
print count
所有 XML 树中的元素都会被检验。当处理一个大约 100MB 的 XML 文件时,占用的内存大约是 560MB ,耗时 2.9 秒。
注意:我们并不需要在内存中加载整颗树。它检测我们需要的带特定值的 location 元素。其他元素被丢弃。这是 iterparse 的来源:
count = 0
for event, elem in ET.iterparse(sys.argv[2]):
if event == ‘end‘:
if elem.tag == ‘location‘ and elem.text == ‘Zimbabwe‘:
count += 1
elem.clear() # discard the element
print count
这个循环遍历 iterparse 事件,检测“闭合的”(end)事件并且寻找 location 标签和指定的值。在这里 elem.clear() 是关键 - iterparse 仍然建立一棵树,只不过不需要全部加载进内存,这样做可以有效的利用内存空间(见注释7)。
处理同样的文件,这个脚本占用内存只需要仅仅的 7MB ,耗时 2.5 秒。速度的提升归功于生成树的时候只遍历一次。相比较来说, parse 方法首先建立了整个树,然后再次遍历来寻找我们需要的元素(所以慢了一点)。
在 Python 众多处理 XML 的模块中, ElementTree 真是屌爆了。它将轻量,符合 Python 哲学的 API ,出色的性能完美的结合在了一起。所以说如果要处理 XML ,果断地使用它吧!
这篇文章简略地谈了谈 ET 。我希望这篇拙作可以抛砖引玉。
注释1:和 DOM 不一样,DOM 将整个 XML 加载进内存并且允许随机访问任何深度地元素。
注释2: expat 是一个开源的用于处理 XML 的 C 语言库。Python 将它融合进自身。
注释3:Fredrik Lundh,是 ElementTree 的原作者,他提到了一些 基准 。
注释4:当我提到 _elementtree 的时候,我意思是 C 语言的 cElementTree._elementtree 扩展模块。
注释5:确定你手边有 模块手册 然后可以随时查阅我提到的方法和函数。
注释6: 状态 是一个意义太多的术语。Python 对象有状态,XML 元素也有状态。希望我能将它们表达的更清楚一点。
注释7:准确来说,树的根元素仍然存活。在某些情况下根结点非常大,你也可以丢弃它,但那需要多一点点代码。
标签:防止 优点 可扩展 sax dev erro 空格 技术分享 有趣
原文地址:http://www.cnblogs.com/JZ-Ser/p/7219428.html