标签:size org 技术分享 str img 基本 ima 9.png 相关
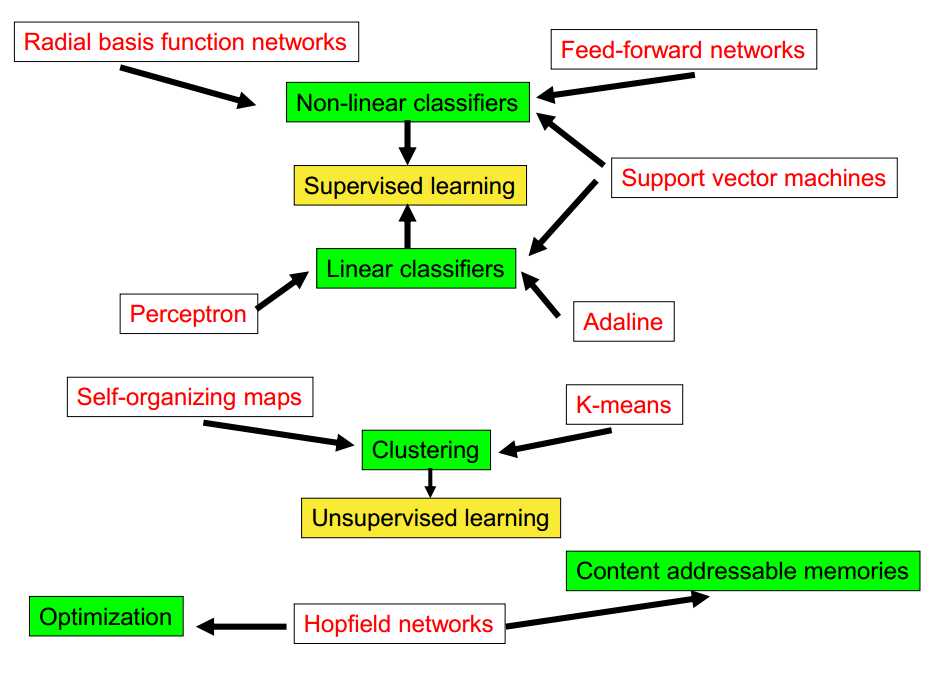
一、神经网络的结构
习惯的强势:能量最小化 大脑控制区在人对某一个事情形成习惯后,在该事情发生时,作出判断时不再消耗能量。(能量最小化与误差最小化?我想知道这里的能量与一般的能量函数之间有没有什么联系的地方?)
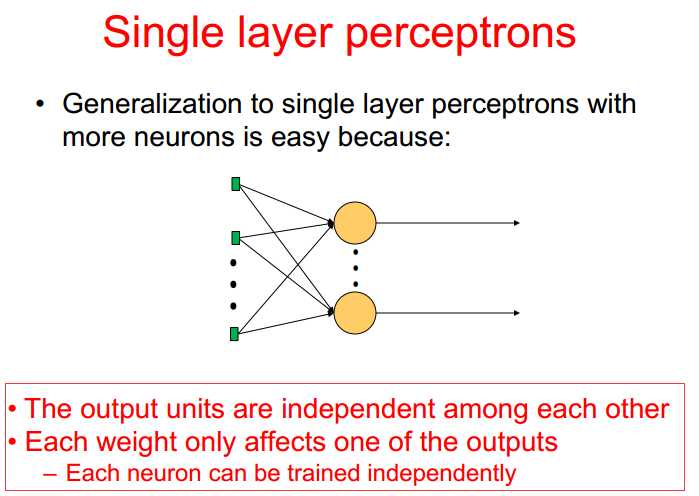
前向网络:网络中只有输入到输出的连接(下面给出单层和多层前向网络)
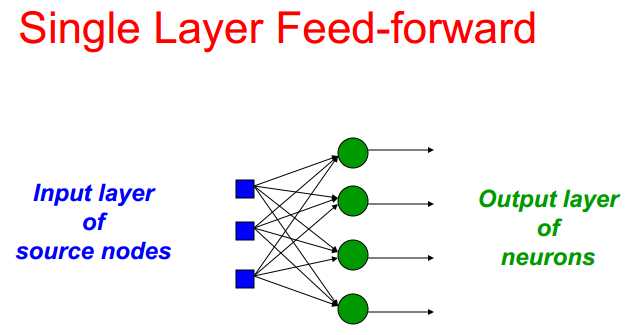
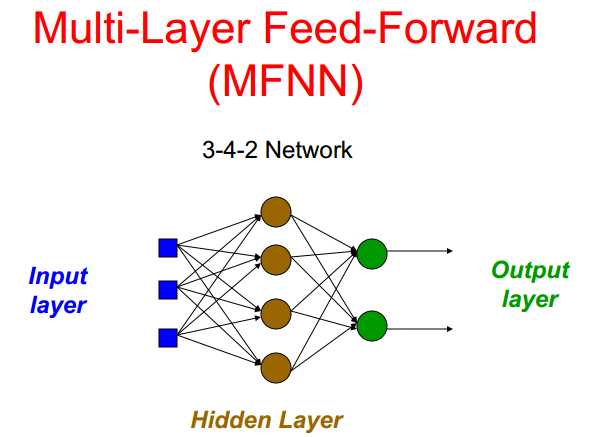
非隐藏层中可以比较期望输出与真实输出(注意观察最后一层的独立性,各个输出对权重的调整互不影响)
Why RNN?

前后顺序有相关性,时间顺序之间相关性,例如:文本分析。
神经网络(结构、神经元、学习算法)
神经元
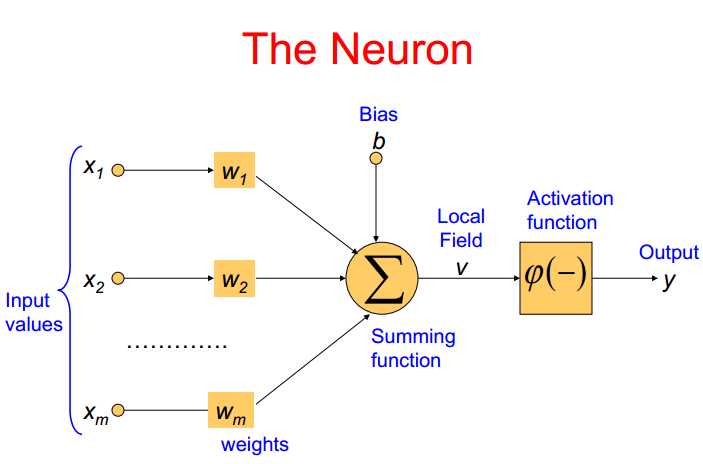
神经元是神经网络中基本的信息处理单元,包括①一系列连接的权重Wi,②加法函数计算输入与权重的和,③激活函数:限制神经元的输出值大小(为什么要限制大小呢?)
激活函数
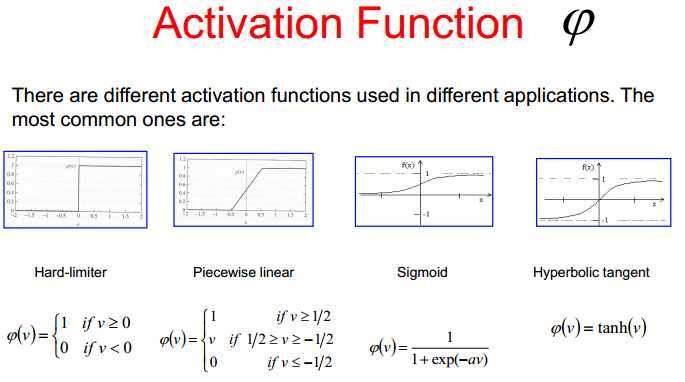
第一种是二值化,可以用于分类。第二种可以求导但是不连续。第三种是可以求导。
学习算法(重点)
什么时候考虑神经网络?

二、单层神经网络
只考了一个神经元的训练,多个神经元的训练类似,只是输出不同
1、感知机训练规则 不保证获得最优曲线,只保证获得可区分的情况
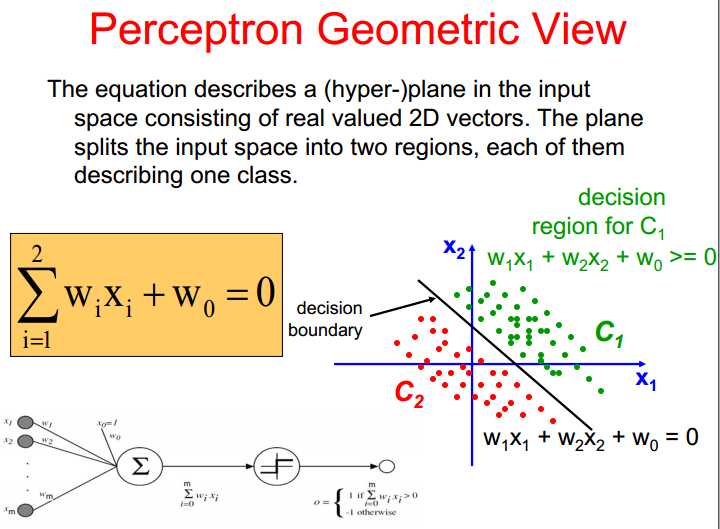


缺点:
1、不断修改,不断抖动(遇到不符合即刻修改)
2、线性不可分问题不能解决
3、正确样本在划分正确以后就没有再利用(期望正确分类的那些好的性质也可以利用起来)
4、错误划分的错误程度没有计入考虑之中(不同程度考虑方案不同)
2、梯度下降学习法则
梯度迭代,权重更新沿梯度反方向

平方误差误差来构造二次方程(二次方程有全局最小值),二次函数前面的1/2主要是为了求导方便
缺点:按全部样本(一次计算出所有样本的情况,对ΔW进行累加)的ΔW来更改权重,计算量大。
选择学习率η要充分小,太大的时候容易越过最优点。

3、Incremental stochastic gradient descent 随机选择样本进行迭代
两种方式

第一种选择部分子集替代所有集合进行梯度迭代,这个时候也存在风险,有部分集合一直属于错分状态,没有利用到。第二种是在计算存在ΔW不为0的时候,就开始进行更新权重,迭代速度加快。
学习规则的对比:

模型性能的验证
训练集和测试集的分割
2017/7/20 朱兴全教授学术讲座观点与总结第二讲:单个神经元/单层神经网络
标签:size org 技术分享 str img 基本 ima 9.png 相关
原文地址:http://www.cnblogs.com/betterforever/p/7214806.html
{kind=link}