标签:cst ext 写入 0.00 详细 binary should aar map
学习深度学习已有一段时间了,总想着拿它做点什么,今天终于完成了一个基于caffe的人脸检测,这篇博文将告诉你怎样通过caffe一步步实现人脸检测。本文主要参考唐宇迪老师的教程,在这里感谢老师的辛勤付出。
传统机器学习方法实现人脸检测:
人脸检测在opencv中已经帮我们实现了,我们要把它玩起来很简单,只需要简简单单的几行代码其实就可以搞定。(haarcascade_frontalface_alt.xml这个文件在opencv的安装目录下能找到,笔者的路径是:E:\opencv2.4.10\opencv\sources\data\haarcascades,大家可根据自己的安装路径找到)

#include <opencv2\core\core.hpp> #include <opencv2\highgui\highgui.hpp> #include <opencv2\imgproc\imgproc.hpp> #include <opencv2\objdetect\objdetect.hpp> #include <iostream> #include <vector> using namespace std; using namespace cv; string xmlName = "haarcascade_frontalface_alt.xml"; CascadeClassifier face_cascade; void detectFaces(Mat image); int main() { Mat image = imread("kobe1.jpg"); if (!image.data) { cout << "read image failed……" << endl; return -1; } face_cascade.load(xmlName); detectFaces(image); waitKey(0); } void detectFaces(Mat image) { vector<Rect> faces; Mat face_gray; cvtColor(image, face_gray, CV_BGR2GRAY); face_cascade.detectMultiScale(face_gray, faces, 1.1, 2, 0 | CV_HAAR_SCALE_IMAGE, Size(1, 1)); cout << faces.size() << endl; for (int i = 0; i < faces.size(); i++) { Rect r(faces[i].x, faces[i].y, faces[i].width, faces[i].height); rectangle(image, r, Scalar(0, 0, 255), 3); } namedWindow("face", CV_WINDOW_NORMAL); imshow("face", image); }
运行结果:
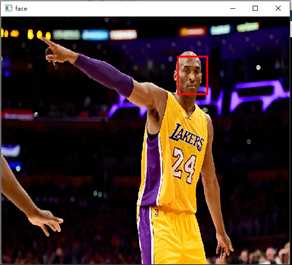
caffe实现人脸检测:
我是在ubuntu16.04环境下完成的实验,渣渣笔记本有不起GPU跑训练,所有实验也是基于CPU的。要想把人脸检测玩起来,首先你得保证你的ubuntu已经安装了opencv和caffe,初次配这两个环境初学者往往会弄到吐血,而且还是吐老血,我自己已经记不清到底花了多久才把它们搞定(估计是我太怂,也许你很快就能弄好哟,加油)。这里给两个参考链接,opencv在ubuntu下的配置和测试:http://blog.csdn.net/a1429331875/article/details/31539129;ubuntu16.04上caffe的配置与安装(CPU ONLY):http://blog.csdn.net/u010402483/article/details/51506616;以上两个链接仅供参考,配置过程出了问题大家就多去网上搜解决方案吧,总会有人也遇到过和你一样的问题。配置好以后大家可以先跑跑MNIST手写字体识别这个案例吧,这个案例算是给自己的一个安慰。 到这里就已经默认大家环境已经配置好了。
第一步:(这样写感觉很蠢,但还是写得尽量详细吧)在桌面或者你喜欢的路径下建一个文件夹,这个文件夹将用来存放我们实验中用到的所有东西。我自己是在桌面建了一个文件夹,取名:faceDetect
第二步:获取人脸和非人脸图片当作训练集和验证集。首先我们一定要有样本,在本实验中我们的样本是一个二分类的样本,大家可以自行去网上找数据集,当然也可以给我发邮件(likai_uestc@163.com),我这里有数据集。数据集我们分训练集(trainData20000_20000)和验证集(testData1600_1600),trainData20000_20000文件夹和testData1600_1600文件夹我们把它们两个都放在faceDetect文件夹下,trainData20000_20000文件夹和testData1600_1600文件夹下又都放两个文件夹face和noface,人脸图片我们放在face文件夹下,非人脸图片我们放在noface文件夹下。此时的目录结构如下:
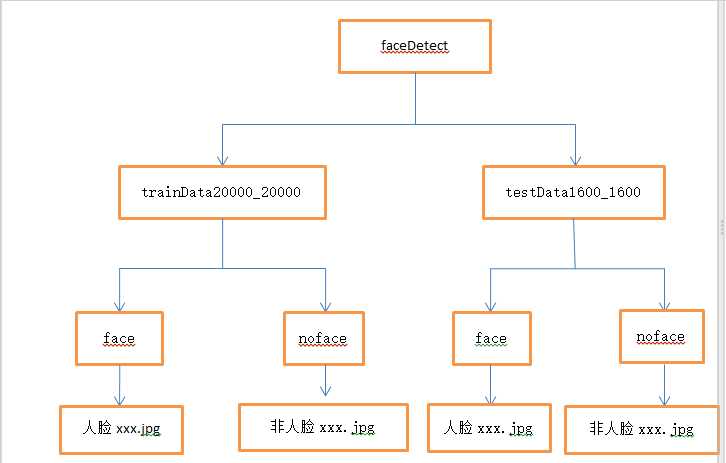
第三步:给样本打标签。本实验中是人脸我们给的标签是1,不是人脸给标签0.训练样本的标签我们写入train.txt,验证样本的标签我们写入test.txt. train.txt和test.txt文件我们放在faceDetect目录下。 txt文件中的内容如下:
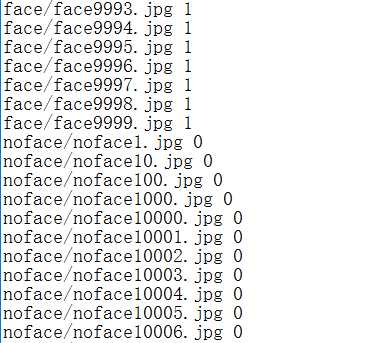
生成txt文件的内容的参考代码如下:(仅供参考)
#include <opencv2\opencv.hpp> #include <iostream> #include <fstream> #include <vector> #include <string> #include <cstdlib> using namespace std; using namespace cv; int main() { Directory dir; string basePath = "face"; string exten = "*"; bool addPath = true; vector<string> fileNames = dir.GetListFiles(basePath, exten, addPath); cout << fileNames.size() << endl; ofstream outData("train.txt"); for (int i = 0; i < fileNames.size(); i++) { cout << fileNames[i] << endl; outData << fileNames[i] << " 1" << endl; } outData.close(); system("pause"); return 0; }
第四步:制作LMDB数据源。通过shell脚本制作,脚本文件名 face-lmdb.sh,face-lmdb.sh也放在faceDetect路径下。脚本的内容:
重点关注第5,6,7,9,10,14,16,17,44,45,54,55行。第5第6行就是你faceDetect的路径,第7行是你caffe中tools的路径,第9第10行是训练样本和验证样本的路径,第14行为true表示对图片进行resize操作,第16,17行填写resize的大小,第44行和54行就是填标签文件,第45和55行是生成的lmdb文件存放的文件夹名,这两个文件夹不能自己手动提前建立。
1 #!/usr/bin/env sh 2 # Create the face_48 lmdb inputs 3 # N.B. set the path to the face_48 train + val data dirs 4 5 EXAMPLE=/home/kobe/Desktop/faceDetect 6 DATA=/home/kobe/Desktop/faceDetect 7 TOOLS=/home/kobe/caffe/build/tools 8 9 TRAIN_DATA_ROOT=/home/kobe/Desktop/faceDetect/trainData20000_20000/ 10 VAL_DATA_ROOT=/home/kobe/Desktop/faceDetect/testData1600_1600/ 11 12 # Set RESIZE=true to resize the images to 60 x 60. Leave as false if images have 13 # already been resized using another tool. 14 RESIZE=true 15 if $RESIZE; then 16 RESIZE_HEIGHT=227 17 RESIZE_WIDTH=227 18 else 19 RESIZE_HEIGHT=0 20 RESIZE_WIDTH=0 21 fi 22 23 if [ ! -d "$TRAIN_DATA_ROOT" ]; then 24 echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT" 25 echo "Set the TRAIN_DATA_ROOT variable in create_face_48.sh to the path" 26 "where the face_48 training data is stored." 27 exit 1 28 fi 29 30 if [ ! -d "$VAL_DATA_ROOT" ]; then 31 echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT" 32 echo "Set the VAL_DATA_ROOT variable in create_face_48.sh to the path" 33 "where the face_48 validation data is stored." 34 exit 1 35 fi 36 37 echo "Creating train lmdb..." 38 39 GLOG_logtostderr=1 $TOOLS/convert_imageset 40 --resize_height=$RESIZE_HEIGHT 41 --resize_width=$RESIZE_WIDTH 42 --shuffle 43 $TRAIN_DATA_ROOT 44 $DATA/train.txt 45 $EXAMPLE/face_train_lmdb 46 47 echo "Creating val lmdb..." 48 49 GLOG_logtostderr=1 $TOOLS/convert_imageset 50 --resize_height=$RESIZE_HEIGHT 51 --resize_width=$RESIZE_WIDTH 52 --shuffle 53 $VAL_DATA_ROOT 54 $DATA/test.txt 55 $EXAMPLE/face_test_lmdb 56 57 echo "Done." 58 Status API Training Shop Blog About
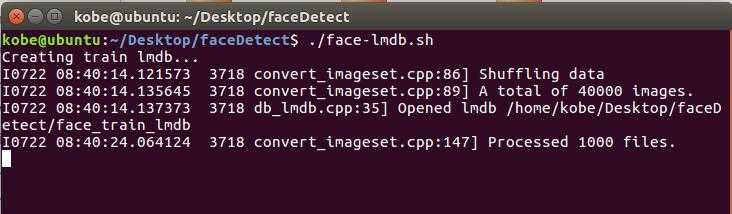
现在在终端执行 ./face-lmdb.sh 命令即可,执行截图如下:
第五步:准备网络模型文件(train.prototxt)及超参数文件(solver.prototxt)。train.prototxt和solver.prototxt文件也放在faceDetect路径下。网络模型各层参数详解及超参数文件详解可参考:https://wenku.baidu.com/view/f77c73d02f60ddccdb38a025.html。
网络模型文件:
############################# DATA Layer ############################# name: "face_train_val" layer { top: "data" top: "label" name: "data" type: "Data" data_param { source: "/home/kobe/Desktop/faceDetect/face_train_lmdb"#改成自己的路径 backend:LMDB batch_size: 64 } transform_param { #mean_file: "/home/test/Downloads/caffe-master/data/ilsvrc12/imagenet_mean.binaryproto" mirror: true } include: { phase: TRAIN } } layer { top: "data" top: "label" name: "data" type: "Data" data_param { source: "/home/kobe/Desktop/faceDetect/face_test_lmdb"#改成自己的路径 backend:LMDB batch_size: 64 } transform_param { #mean_file: "/home/test/Downloads/caffe-master/data/ilsvrc12/imagenet_mean.binaryproto" mirror: true } include: { phase: TEST } } layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 96 kernel_size: 11 stride: 4 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "relu1" type: "ReLU" bottom: "conv1" top: "conv1" } layer { name: "norm1" type: "LRN" bottom: "conv1" top: "norm1" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 } } layer { name: "pool1" type: "Pooling" bottom: "norm1" top: "pool1" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "conv2" type: "Convolution" bottom: "pool1" top: "conv2" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 256 pad: 2 kernel_size: 5 group: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0.1 } } } layer { name: "relu2" type: "ReLU" bottom: "conv2" top: "conv2" } layer { name: "norm2" type: "LRN" bottom: "conv2" top: "norm2" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 } } layer { name: "pool2" type: "Pooling" bottom: "norm2" top: "pool2" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "conv3" type: "Convolution" bottom: "pool2" top: "conv3" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 384 pad: 1 kernel_size: 3 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "relu3" type: "ReLU" bottom: "conv3" top: "conv3" } layer { name: "conv4" type: "Convolution" bottom: "conv3" top: "conv4" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 384 pad: 1 kernel_size: 3 group: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0.1 } } } layer { name: "relu4" type: "ReLU" bottom: "conv4" top: "conv4" } layer { name: "conv5" type: "Convolution" bottom: "conv4" top: "conv5" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 256 pad: 1 kernel_size: 3 group: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0.1 } } } layer { name: "relu5" type: "ReLU" bottom: "conv5" top: "conv5" } layer { name: "pool5" type: "Pooling" bottom: "conv5" top: "pool5" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "fc6" type: "InnerProduct" bottom: "pool5" top: "fc6" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } inner_product_param { num_output: 4096 weight_filler { type: "gaussian" std: 0.005 } bias_filler { type: "constant" value: 0.1 } } } layer { name: "relu6" type: "ReLU" bottom: "fc6" top: "fc6" } layer { name: "drop6" type: "Dropout" bottom: "fc6" top: "fc6" dropout_param { dropout_ratio: 0.5 } } layer { name: "fc7" type: "InnerProduct" bottom: "fc6" top: "fc7" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } inner_product_param { num_output: 4096 weight_filler { type: "gaussian" std: 0.005 } bias_filler { type: "constant" value: 0.1 } } } layer { name: "relu7" type: "ReLU" bottom: "fc7" top: "fc7" } layer { name: "drop7" type: "Dropout" bottom: "fc7" top: "fc7" dropout_param { dropout_ratio: 0.5 } } layer { name: "fc8-expr" type: "InnerProduct" bottom: "fc7" top: "fc8-expr" param { lr_mult: 10 decay_mult: 1 } param { lr_mult: 20 decay_mult: 0 } inner_product_param { num_output: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "accuracy" type: "Accuracy" bottom: "fc8-expr" bottom: "label" top: "accuracy" include { phase: TEST } } layer { name: "loss" type: "SoftmaxWithLoss" bottom: "fc8-expr" bottom: "label" top: "loss" }
超参数文件:
第1行网络模型文件的路径,第15行训练得到的模型的保存路径,在本实验中自己在faceDetect文件夹下建一个model文件夹用于保存得到的模型文件。net: "/home/kobe/Desktop/faceDetect/train.prototxt"
test_iter: 50
test_interval: 500
# lr for fine-tuning should be lower than when starting from scratch
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
# stepsize should also be lower, as we‘re closer to being done
stepsize: 20000
display: 100
max_iter: 100000
momentum: 0.9
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "/home/kobe/Desktop/faceDetect/model/"
# uncomment the following to default to CPU mode solving
solver_mode: CPU
第六步:开始训练。运行train.sh脚本进行训练,train.sh也放在faceDetect路径下。脚本的内容:(根据自己的实际路径进行修改)
1 #!/usr/bin/env sh 2 3 /home/kobe/caffe/build/tools/caffe train --solver=/home/kobe/Desktop/faceDetect/solver.prototxt #4 #--weights=models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel 5 #--gpu 0
在终端中运行 ./train.sh 就可以开始训练了,训练很花时间的,根据机器配置不同所花时间也不同。训练截图如下:
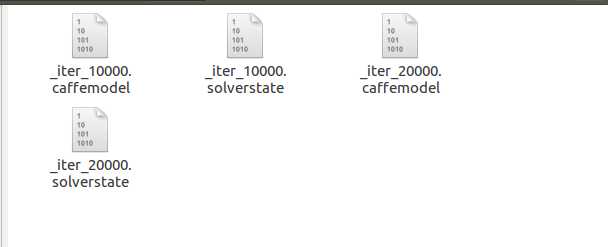
训练结束后,我们得到以下的文件(model下的文件),caffemodel结尾的文件就是我们最终需要的文件了:
第七步:实现多尺度人脸检测。基于滑动窗口的人脸检测,在训练的时候样本已经resize成227*227,所以对于输入图片,我们在输入图片中截取227*227大小的窗口放入模型进行分类,依次这样进行窗口滑动,最终找出其中的人脸区域。但是图片中人脸并不一定就是227*227大小的,所以我们需要进行多尺度变换,所谓多尺度变换就是指对于输入图片我们进行放大和缩小变换,这样输入一张图片,就可以得到很多经过放大或缩小的图片了,把所有图片当作一组输入进行人脸检测。那么现在问题又来了,我们输入的是不同大小的图片,网络中有一个全连接层,全连接层的存在导致输入的图片大小必须一样大小,要解决这个问题我们的解决方法是把全连接层转换成全卷积层(可参考caffe官网进行操作)。
转换过程中需要用到的两个deploy文件。
全连接时使用(deploy.prototxt):
name: "CaffeNet" input: "data" input_dim: 10 input_dim: 3 input_dim: 227 input_dim: 227 layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 96 kernel_size: 11 stride: 4 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "relu1" type: "ReLU" bottom: "conv1" top: "conv1" } layer { name: "pool1" type: "Pooling" bottom: "conv1" top: "pool1" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "norm1" type: "LRN" bottom: "pool1" top: "norm1" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 } } layer { name: "conv2" type: "Convolution" bottom: "norm1" top: "conv2" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 256 pad: 2 kernel_size: 5 group: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 1 } } } layer { name: "relu2" type: "ReLU" bottom: "conv2" top: "conv2" } layer { name: "pool2" type: "Pooling" bottom: "conv2" top: "pool2" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "norm2" type: "LRN" bottom: "pool2" top: "norm2" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 } } layer { name: "conv3" type: "Convolution" bottom: "norm2" top: "conv3" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 384 pad: 1 kernel_size: 3 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "relu3" type: "ReLU" bottom: "conv3" top: "conv3" } layer { name: "conv4" type: "Convolution" bottom: "conv3" top: "conv4" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 384 pad: 1 kernel_size: 3 group: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 1 } } } layer { name: "relu4" type: "ReLU" bottom: "conv4" top: "conv4" } layer { name: "conv5" type: "Convolution" bottom: "conv4" top: "conv5" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 256 pad: 1 kernel_size: 3 group: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 1 } } } layer { name: "relu5" type: "ReLU" bottom: "conv5" top: "conv5" } layer { name: "pool5" type: "Pooling" bottom: "conv5" top: "pool5" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "fc6" type: "InnerProduct" bottom: "pool5" top: "fc6" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } inner_product_param { num_output: 4096 weight_filler { type: "gaussian" std: 0.005 } bias_filler { type: "constant" value: 1 } } } layer { name: "relu6" type: "ReLU" bottom: "fc6" top: "fc6" } layer { name: "drop6" type: "Dropout" bottom: "fc6" top: "fc6" dropout_param { dropout_ratio: 0.5 } } layer { name: "fc7" type: "InnerProduct" bottom: "fc6" top: "fc7" # Note that lr_mult can be set to 0 to disable any fine-tuning of this, and any other, layer param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } inner_product_param { num_output: 4096 weight_filler { type: "gaussian" std: 0.005 } bias_filler { type: "constant" value: 1 } } } layer { name: "relu7" type: "ReLU" bottom: "fc7" top: "fc7" } layer { name: "drop7" type: "Dropout" bottom: "fc7" top: "fc7" dropout_param { dropout_ratio: 0.5 } } layer { name: "fc8_flickr" type: "InnerProduct" bottom: "fc7" top: "fc8_flickr" # lr_mult is set to higher than for other layers, because this layer is starting from random while the others are already trained param { lr_mult: 10 decay_mult: 1 } param { lr_mult: 20 decay_mult: 0 } inner_product_param { num_output: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "prob" type: "Softmax" bottom: "fc8_flickr" top: "prob" }
全卷积时使用(deploy_full_conv.prototxt):
name: "CaffeNet_full_conv" input: "data" input_dim: 1 input_dim: 3 input_dim: 500 input_dim: 500 layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 96 kernel_size: 11 stride: 4 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "relu1" type: "ReLU" bottom: "conv1" top: "conv1" } layer { name: "pool1" type: "Pooling" bottom: "conv1" top: "pool1" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "norm1" type: "LRN" bottom: "pool1" top: "norm1" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 } } layer { name: "conv2" type: "Convolution" bottom: "norm1" top: "conv2" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 256 pad: 2 kernel_size: 5 group: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 1 } } } layer { name: "relu2" type: "ReLU" bottom: "conv2" top: "conv2" } layer { name: "pool2" type: "Pooling" bottom: "conv2" top: "pool2" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "norm2" type: "LRN" bottom: "pool2" top: "norm2" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 } } layer { name: "conv3" type: "Convolution" bottom: "norm2" top: "conv3" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 384 pad: 1 kernel_size: 3 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "relu3" type: "ReLU" bottom: "conv3" top: "conv3" } layer { name: "conv4" type: "Convolution" bottom: "conv3" top: "conv4" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 384 pad: 1 kernel_size: 3 group: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 1 } } } layer { name: "relu4" type: "ReLU" bottom: "conv4" top: "conv4" } layer { name: "conv5" type: "Convolution" bottom: "conv4" top: "conv5" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 256 pad: 1 kernel_size: 3 group: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 1 } } } layer { name: "relu5" type: "ReLU" bottom: "conv5" top: "conv5" } layer { name: "pool5" type: "Pooling" bottom: "conv5" top: "pool5" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "fc6-conv" type: "Convolution" bottom: "pool5" top: "fc6-conv" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 4096 kernel_size: 6 weight_filler { type: "gaussian" std: 0.005 } bias_filler { type: "constant" value: 1 } } } layer { name: "relu6" type: "ReLU" bottom: "fc6-conv" top: "fc6-conv" } layer { name: "drop6" type: "Dropout" bottom: "fc6-conv" top: "fc6-conv" dropout_param { dropout_ratio: 0.5 } } layer { name: "fc7-conv" type: "Convolution" bottom: "fc6-conv" top: "fc7-conv" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 4096 kernel_size: 1 weight_filler { type: "gaussian" std: 0.005 } bias_filler { type: "constant" value: 1 } } } layer { name: "relu7" type: "ReLU" bottom: "fc7-conv" top: "fc7-conv" } layer { name: "drop7" type: "Dropout" bottom: "fc7-conv" top: "fc7-conv" dropout_param { dropout_ratio: 0.5 } } layer { name: "fc8-conv" type: "Convolution" bottom: "fc7-conv" top: "fc8-conv" param { lr_mult: 10 decay_mult: 1 } param { lr_mult: 20 decay_mult: 0 } convolution_param { num_output: 2 kernel_size: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "prob" type: "Softmax" bottom: "fc8-conv" top: "prob" }
全连接转全卷积参考代码:
# -*- coding: utf-8 -*- import caffe #matplotlib inline import numpy as np import matplotlib.pyplot as plt import matplotlib.cbook as cbook #import Image import sys import os from math import pow from PIL import Image, ImageDraw, ImageFont import cv2 import math import random caffe_root = ‘/home/kobe/caffe/‘ sys.path.insert(0, caffe_root + ‘python‘) os.environ[‘GLOG_minloglevel‘] = ‘2‘ caffe.set_mode_cpu() ##################################################################################################### # Load the original network and extract the fully connected layers‘ parameters. net = caffe.Net(‘/home/kobe/Desktop/faceDetect/project/deploy.prototxt‘, ‘/home/kobe/Desktop/faceDetect/model/_iter_50000.caffemodel‘, caffe.TEST) params = [‘fc6‘, ‘fc7‘, ‘fc8_flickr‘] # fc_params = {name: (weights, biases)} fc_params = {pr: (net.params[pr][0].data, net.params[pr][1].data) for pr in params} for fc in params: print ‘{} weights are {} dimensional and biases are {} dimensional‘.format(fc, fc_params[fc][0].shape, fc_params[fc][1].shape) ####################################################################################################### # Load the fully convolutional network to transplant the parameters. net_full_conv = caffe.Net(‘/home/kobe/Desktop/faceDetect/project/deploy_full_conv.prototxt‘, ‘/home/kobe/Desktop/faceDetect/model/_iter_50000.caffemodel‘, caffe.TEST) params_full_conv = [‘fc6-conv‘, ‘fc7-conv‘, ‘fc8-conv‘] # conv_params = {name: (weights, biases)} conv_params = {pr: (net_full_conv.params[pr][0].data, net_full_conv.params[pr][1].data) for pr in params_full_conv} for conv in params_full_conv: print ‘{} weights are {} dimensional and biases are {} dimensional‘.format(conv, conv_params[conv][0].shape, conv_params[conv][1].shape) ############################################################################################################# for pr, pr_conv in zip(params, params_full_conv): conv_params[pr_conv][0].flat = fc_params[pr][0].flat # flat unrolls the arrays conv_params[pr_conv][1][...] = fc_params[pr][1] ############################################################################################################## net_full_conv.save(‘/home/kobe/Desktop/faceDetect/alexnet_iter_50000_full_conv.caffemodel‘)
转换后得到另一个模型(alexnet_iter_50000_full_conv.caffemodel).
实现多尺度人脸检测代码:
# -*- coding: utf-8 -*- import caffe #matplotlib inline import numpy as np import matplotlib.pyplot as plt import matplotlib.cbook as cbook #import Image import sys import os from math import pow from PIL import Image, ImageDraw, ImageFont import cv2 import math import random caffe_root = ‘/home/kobe/caffe/‘ sys.path.insert(0, caffe_root + ‘python‘) os.environ[‘GLOG_minloglevel‘] = ‘2‘ caffe.set_mode_cpu() #非极大值抑制算法NMS class Point(object): def __init__(self, x, y): self.x = x self.y = y def calculateDistance(x1,y1,x2,y2): #计算人脸框的对角线距离 dist = math.sqrt((x2 - x1)**2 + (y2 - y1)**2) return dist def range_overlap(a_min, a_max, b_min, b_max): return (a_min <= b_max) and (b_min <= a_max) def rect_overlaps(r1,r2): return range_overlap(r1.left, r1.right, r2.left, r2.right) and range_overlap(r1.bottom, r1.top, r2.bottom, r2.top) def rect_merge(r1,r2, mergeThresh): if rect_overlaps(r1,r2): # dist = calculateDistance((r1.left + r1.right)/2, (r1.top + r1.bottom)/2, (r2.left + r2.right)/2, (r2.top + r2.bottom)/2) SI= abs(min(r1.right, r2.right) - max(r1.left, r2.left)) * abs(max(r1.bottom, r2.bottom) - min(r1.top, r2.top)) SA = abs(r1.right - r1.left)*abs(r1.bottom - r1.top) SB = abs(r2.right - r2.left)*abs(r2.bottom - r2.top) S=SA+SB-SI ratio = float(SI) / float(S) if ratio > mergeThresh : return 1 return 0 class Rect(object): def __init__(self, p1, p2): #p1和p2为对角线上的两个点 ‘‘‘Store the top, bottom, left and right values for points p1 and p2 are the (corners) in either order ‘‘‘ self.left = min(p1.x, p2.x) #????? self.right = max(p1.x, p2.x) self.bottom = min(p1.y, p2.y) self.top = max(p1.y, p2.y) def __str__(self): return "Rect[%d, %d, %d, %d]" % ( self.left, self.top, self.right, self.bottom ) def nms_average(boxes, groupThresh=2, overlapThresh=0.2): rects = [] temp_boxes = [] weightslist = [] new_rects = [] for i in range(len(boxes)): if boxes[i][4] > 0.2: rects.append([boxes[i,0], boxes[i,1], boxes[i,2]-boxes[i,0], boxes[i,3]-boxes[i,1]]) rects, weights = cv2.groupRectangles(rects, groupThresh, overlapThresh) #函数解释http://blog.csdn.net/nongfu_spring/article/details/38977833 rectangles = [] for i in range(len(rects)): testRect = Rect( Point(rects[i,0], rects[i,1]), Point(rects[i,0]+rects[i,2], rects[i,1]+rects[i,3])) rectangles.append(testRect) clusters = [] for rect in rectangles: matched = 0 for cluster in clusters: if (rect_merge( rect, cluster , 0.2) ): matched=1 cluster.left = (cluster.left + rect.left )/2 cluster.right = ( cluster.right+ rect.right )/2 cluster.top = ( cluster.top+ rect.top )/2 cluster.bottom = ( cluster.bottom+ rect.bottom )/2 if ( not matched ): clusters.append( rect ) result_boxes = [] for i in range(len(clusters)): result_boxes.append([clusters[i].left, clusters[i].bottom, clusters[i].right, clusters[i].top, 1]) return result_boxes def generateBoundingBox(featureMap, scale): #由于做了scale变换,所以在这里还要将坐标反变换回去 boundingBox = [] #存储候选框,以及属于人脸的概率 stride = 32 #感受野的大小,filter大小,这个需要自己不断地去调整; cellSize = 227 #人脸框的大小,它这里是认为特征图上的一块区域的prob大于95%,就以那个点在原始图像中相应的位置作为人脸框的左上角点,然后框出候选框,但这么做感觉会使候选框变多 #遍历最终的特征图,寻找属于人脸的概率大于95%的那些区域,加上Box for (x,y), prob in np.ndenumerate(featureMap): if(prob >= 0.95): boundingBox.append([float(stride * y)/ scale, float(x * stride)/scale, float(stride * y + cellSize - 1)/scale, float(stride * x + cellSize - 1)/scale, prob]) return boundingBox def face_detection(imgFile): net_full_conv = caffe.Net(os.path.join(caffe_root, ‘faceDetect‘, ‘deploy_full_conv.prototxt‘), os.path.join(caffe_root, ‘faceDetect‘, ‘alexnet_iter_50000_full_conv.caffemodel‘), caffe.TEST)#全卷积网络(导入训练好的模型和deploy配置文件) randNum = random.randint(1,10000) #设置一个在1到10000之间的随机数 scales = [] #设置几个scale,组成图像金字塔 factor = 0.793700526 #图像放大或者缩小的一个因子(经验值) img = cv2.imread(imgFile) #读入测试图像 largest = min(2, 4000/max(img.shape[0:2])) #设定做scale变幻时最大的scale scale = largest minD = largest*min(img.shape[0:2]) #设定最小的scale while minD >= 227: #只要最小的边做完最大的scale变换后大于227,之前得到的largest就可以作为最大的scale来用,并依此乘上factor,加入到scale列表中 scales.append(scale) scale *= factor minD *= factor total_boxes = [] #存储所有的候选框 #进行多尺度的人脸检测 for scale in scales: scale_img = cv2.resize(img,((int(img.shape[0] * scale), int(img.shape[1] * scale)))) #调整图像的长和高 cv2.imwrite(‘/home/kobe/Desktop/faceDetect/project/1.jpg‘,scale_img) #保存图像 #图像预处理 im = caffe.io.load_image(‘/home/kobe/Desktop/faceDetect/project/1.jpg‘) #得到的特征值是0到1之间的小数 net_full_conv.blobs[‘data‘].reshape(1,3,scale_img.shape[1],scale_img.shape[0]) #blobs[‘data‘]指data层,字典用法;同时由于图像大小发生了变化,data层的输入接口也要发生相应的变化 transformer = caffe.io.Transformer({‘data‘: net_full_conv.blobs[‘data‘].data.shape}) #设定图像的shape格式 transformer.set_mean(‘data‘, np.load(caffe_root + ‘python/caffe/imagenet/ilsvrc_2012_mean.npy‘).mean(1).mean(1)) #减去均值操作 transformer.set_transpose(‘data‘, (2,0,1)) #move image channels to outermost dimension transformer.set_channel_swap(‘data‘, (2,1,0)) #swap channels from RGB to BGR transformer.set_raw_scale(‘data‘, 255.0) #rescale from [0,1] to [0,255] out = net_full_conv.forward_all(data=np.asarray([transformer.preprocess(‘data‘, im)])) #进行一次前向传播,out包括所有经过每一层后的特征图,其中元素为[(x,y),prob](特征图中的每一个小区域都代表一个概率) boxes = generateBoundingBox(out[‘prob‘][0,1], scale) #输出两类的可能性,并经过筛选获得候选框 if(boxes): total_boxes.extend(boxes) #将每次scale变换后的图片得到的候选框存进total_boxes中 boxes_nms = np.array(total_boxes) true_boxes = nms_average(boxes_nms, 1, 0.2) #利用非极大值算法过滤出人脸概率最大的框 if not true_boxes == []: (x1, y1, x2, y2) = true_boxes[0][:-1] print (x1, y1, x2, y2) cv2.rectangle(img, (int(x1),int(y1)), (int(x2),int(y2)), (0,0,255),thickness = 5) cv2.imwrite(‘/home/kobe/Desktop/faceDetect/project/result.jpg‘,img) imgFile = ‘/home/kobe/Desktop/faceDetect/project/test.jpg‘ print(‘start detect‘) face_detection(imgFile) print(‘finish detect‘) #image_file = cbook.get_sample_data(imgFile) img = plt.imread(imgFile) plt.imshow(img) plt.show()
运行结果:

标签:cst ext 写入 0.00 详细 binary should aar map
原文地址:http://www.cnblogs.com/418ks/p/7221185.html
