标签:读取 features 读数 取数据 cti 矩阵 区别 opera dict
最近在看机器学习的西瓜书,再用代码实现上面的部分算法。边学边实现,用的是Python语言,遇到了一个问题,就是读取数据集后的处理。搞不清楚数组和矩阵的区别,所以对距离的计算也就无从下手。
现总结一下下午工作的内容:
1、矩阵可以直接进行加减乘操作,而数组不可以,列表页不可以
2、mat()函数,是将一种数据类型转换为矩阵形式
3、eye(4)是一个4x4的单位矩阵
4、zeros(4)是一个一维的包含4个元素的数组
5、对于读取文件时的格式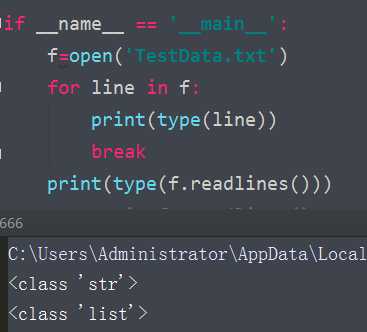 for循环时反回的是字符串形式,readlines返回的是列表形式
for循环时反回的是字符串形式,readlines返回的是列表形式
6、split(‘‘)返回的是一个列表,strip()返回的是字符串
6、将两个列表合并为一个字典,按对应元素,这是两种方法
dict(map(lambda x, y: [x, y], testLabelSet, testLabels))
combined = {} for i in range(len(testLabels)): combined[testLabels[i]] = testLabelSet[i] print(combined)
接下来就是自己实现的KNN分类算法:
首先定义了一个文件读取的函数,开始的时候就是在这个地方出问题的。后来想想要将文件的属性值改为矩阵形式才能进行计算:
def fileMat(filename): file=open(filename,‘r‘) ‘‘‘读取文件的内容,readlines返回的是一个列表‘‘‘ contain=file.readlines() count=len(contain)#这是文件共有count行 ‘‘‘创建一个count x len(contain[0].split(‘,‘))-1的矩阵‘‘‘ features=zeros((count,len(contain[0].split(‘,‘))-1)) labels=[] index=0 for line in contain: #一行行读数据文件 line=line.strip() listFormLine=line.split(‘,‘) ‘‘‘将listFormLine中的前len(len(listFormLine)-1)列加入到矩阵中去‘‘‘ features[index:]=listFormLine[0:len(listFormLine)-1] labels.append(listFormLine[-1]) #最后一列作为类标 index+=1 ‘‘‘返回的features为特征矩阵,labels为类别列表‘‘‘ return features,labels
然后计算欧式距离
‘‘‘计算欧式距离dist = numpy.sqrt(numpy.sum(numpy.square(vec1 - vec2))) 并排序,并分割前k个欧氏距离、排序、计算类别比例‘‘‘ def OushiDistance(trainingSet,trainingLabelSet,testInstance): dist=[] labels=[] k=0 for i in range(len(trainingSet)): ‘‘‘欧式距离的计算公式‘‘‘ distance = np.sqrt(np.sum(np.square(testInstance - trainingSet[i]))) dist.append(distance) k+=1 ‘‘‘训练样本的平方根作为k‘‘‘ k=int(math.sqrt(k)) ‘‘‘从小到大排序后的欧氏距离的前k个下标‘‘‘ sortIndex=np.argsort(dist) sortIndex=sortIndex[0:k] ‘‘‘统计训练标记的比例‘‘‘ for i in sortIndex: ‘‘‘取欧氏距离最小的k个值的类别‘‘‘ labels.append(trainingLabelSet[i]) ‘‘‘统计labels中的元素的出现次数‘‘‘ countLabels=dict(Counter(labels)) ‘‘‘按字典的value进行从大到小排序‘‘‘ dict1 = sorted(countLabels.items(), key=lambda x: x[1], reverse=True) ‘‘‘返回出现次数最多的‘‘‘ return dict1[0][0]
再写个测试函数
def testing(): ‘‘‘读取测是文件,和训练文件‘‘‘ trainingSet,trainingLabelSet=fileMat(‘trainingData.txt‘) testSet,testLabelSet=fileMat(‘testData.txt‘) testLabels=[] for i in range(len(testSet)): classify=OushiDistance(trainingSet,trainingLabelSet,testSet[i]) testLabels.append(classify) print(testLabels)
总的代码如下
import numpy as np from numpy import * import math import operator from collections import Counter ‘‘‘‘读取文件内容‘‘‘ def fileMat(filename): file=open(filename,‘r‘) ‘‘‘读取文件的内容,readlines返回的是一个列表‘‘‘ contain=file.readlines() count=len(contain)#这是文件共有count行 ‘‘‘创建一个count x len(contain[0].split(‘,‘))-1的矩阵‘‘‘ features=zeros((count,len(contain[0].split(‘,‘))-1)) labels=[] index=0 for line in contain: #一行行读数据文件 line=line.strip() listFormLine=line.split(‘,‘) ‘‘‘将listFormLine中的前len(len(listFormLine)-1)列加入到矩阵中去‘‘‘ features[index:]=listFormLine[0:len(listFormLine)-1] labels.append(listFormLine[-1]) #最后一列作为类标 index+=1 ‘‘‘返回的features为特征矩阵,labels为类别列表‘‘‘ return features,labels ‘‘‘计算欧式距离dist = numpy.sqrt(numpy.sum(numpy.square(vec1 - vec2))) 并排序,并分割前k个欧氏距离、排序、计算类别比例‘‘‘ def OushiDistance(trainingSet,trainingLabelSet,testInstance): dist=[] labels=[] k=0 for i in range(len(trainingSet)): ‘‘‘欧式距离的计算公式‘‘‘ distance = np.sqrt(np.sum(np.square(testInstance - trainingSet[i]))) dist.append(distance) k+=1 ‘‘‘训练样本的平方根作为k‘‘‘ k=int(math.sqrt(k)) ‘‘‘从小到大排序后的欧氏距离的前k个下标‘‘‘ sortIndex=np.argsort(dist) sortIndex=sortIndex[0:k] ‘‘‘统计训练标记的比例‘‘‘ for i in sortIndex: ‘‘‘取欧氏距离最小的k个值的类别‘‘‘ labels.append(trainingLabelSet[i]) ‘‘‘统计labels中的元素的出现次数‘‘‘ countLabels=dict(Counter(labels)) ‘‘‘按字典的value进行从大到小排序‘‘‘ dict1 = sorted(countLabels.items(), key=lambda x: x[1], reverse=True) ‘‘‘返回出现次数最多的‘‘‘ return dict1[0][0] def testing(): ‘‘‘读取测是文件,和训练文件‘‘‘ trainingSet,trainingLabelSet=fileMat(‘trainingData.txt‘) testSet,testLabelSet=fileMat(‘testData.txt‘) testLabels=[] for i in range(len(testSet)): classify=OushiDistance(trainingSet,trainingLabelSet,testSet[i]) testLabels.append(classify) print(testLabels) if __name__ == ‘__main__‘: print(testing())
注:可以指正,请勿转载
标签:读取 features 读数 取数据 cti 矩阵 区别 opera dict
原文地址:http://www.cnblogs.com/ruiqingliu/p/7220810.html