标签:访问 header image 最小 tables cond get请求 关联 border
DDoS(Distributed Denial of Service,分布式拒绝服务)攻击的主要目的是让指定目标无法提供正常服务,甚至从互联网上消失,是目前最强大、最难防御的攻击之一。
按照发起的方式,DDoS可以简单分为三类。
第一类以力取胜
海量数据包从互联网的各个角落蜂拥而来,堵塞IDC入口,让各种强大的硬件防御系统、快速高效的应急流程无用武之地。这种类型的攻击典型代表是ICMP Flood和UDP Flood,现在已不常见。
第二类以巧取胜
灵动而难以察觉,每隔几分钟发一个包甚至只需要一个包,就可以让豪华配置的服务器不再响应。这类攻击主要是利用协议或者软件的漏洞发起,例如Slowloris攻击、Hash冲突攻击等,需要特定环境机缘巧合下才能出现。
第三类是上述两种的混合
轻灵浑厚兼而有之,既利用了协议、系统的缺陷,又具备了海量的流量,例如SYN Flood攻击、DNS Query Flood攻击,是当前的主流攻击方式。
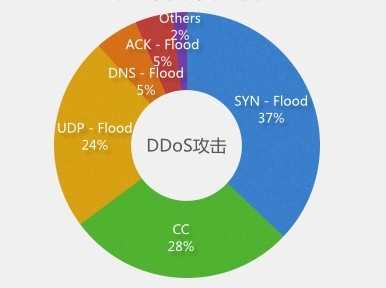
目前最经典的攻击手法SYN Flood依旧占据大头;CC攻击有后来居上的趋势,因为发起容易,效果显著;UDP攻击屈居第三名,但却是流量攻击的首选,各种反射放大攻击都属于UDP攻击。
SYN Flood是互联网上最经典的DDoS攻击方式之一,最早出现于1999年左右,雅虎是当时最著名的受害者。SYN Flood攻击利用了TCP三次握手的缺陷,能够以较小代价使目标服务器无法响应,且难以追查。
标准的TCP三次握手过程如下:
经过这三步,TCP连接就建立完成。TCP协议为了实现可靠传输,在三次握手的过程中设置了一些异常处理机制。第三步中如果服务器没有收到客户端的最终ACK确认报文,会一直处于SYN_RECV状态,将客户端IP加入等待列表,并重发第二步的SYN+ACK报文。重发一般进行3-5次,大约间隔30秒左右轮询一次等待列表重试所有客户端。另一方面,服务器在自己发出了SYN+ACK报文后,会预分配资源为即将建立的TCP连接储存信息做准备,这个资源在等待重试期间一直保留。更为重要的是,服务器资源有限,可以维护的SYN_RECV状态超过极限后就不再接受新的SYN报文,也就是拒绝新的TCP连接建立。
SYN Flood正是利用了上文中TCP协议的设定,达到攻击的目的。攻击者伪装大量的IP地址给服务器发送SYN报文,由于伪造的IP地址几乎不可能存在,也就几乎没有设备会给服务器返回任何应答了。因此,服务器将会维持一个庞大的等待列表,不停地重试发送SYN+ACK报文,同时占用着大量的资源无法释放。更为关键的是,被攻击服务器的SYN_RECV队列被恶意的数据包占满,不再接受新的SYN请求,合法用户无法完成三次握手建立起TCP连接。也就是说,这个服务器被SYN Flood拒绝服务了。
作为互联网最基础、最核心的服务,DNS自然也是DDoS攻击的重要目标之一。打垮DNS服务能够间接打垮一家公司的全部业务,或者打垮一个地区的网络服务。前些时候风头正盛的黑客组织anonymous也曾经宣布要攻击全球互联网的13台根DNS服务器,不过最终没有得手。
UDP攻击是最容易发起海量流量的攻击手段,而且源IP随机伪造难以追查。但过滤比较容易,因为大多数IP并不提供UDP服务,直接丢弃UDP流量即可。所以现在纯粹的UDP流量攻击比较少见了,取而代之的是UDP协议承载的DNS Query Flood攻击。简单地说,越上层协议上发动的DDoS攻击越难以防御,因为协议越上层,与业务关联越大,防御系统面临的情况越复杂。
DNS Query Flood就是攻击者操纵大量傀儡机器,对目标发起海量的域名查询请求。为了防止基于ACL的过滤,必须提高数据包的随机性。常用的做法是UDP层随机伪造源IP地址、随机伪造源端口等参数。在DNS协议层,随机伪造查询ID以及待解析域名。随机伪造待解析域名除了防止过滤外,还可以降低命中DNS缓存的可能性,尽可能多地消耗DNS服务器的CPU资源。
上文描述的SYN Flood、DNS Query Flood在现阶段已经能做到有效防御了,真正令各大厂商以及互联网企业头疼的是HTTP Flood攻击。HTTP Flood是针对Web服务在第七层协议发起的攻击。它的巨大危害性主要表现在三个方面:发起方便、过滤困难、影响深远。
SYN Flood和DNS Query Flood都需要攻击者以root权限控制大批量的傀儡机。收集大量root权限的傀儡机很花费时间和精力,而且在攻击过程中傀儡机会由于流量异常被管理员发现,攻击者的资源快速损耗而补充缓慢,导致攻击强度明显降低而且不可长期持续。HTTP Flood攻击则不同,攻击者并不需要控制大批的傀儡机,取而代之的是通过端口扫描程序在互联网上寻找匿名的HTTP代理或者SOCKS代理,攻击者通过匿名代理对攻击目标发起HTTP请求。匿名代理是一种比较丰富的资源,花几天时间获取代理并不是难事,因此攻击容易发起而且可以长期高强度的持续。
另一方面,HTTP Flood攻击在HTTP层发起,极力模仿正常用户的网页请求行为,与网站业务紧密相关,安全厂商很难提供一套通用的且不影响用户体验的方案。在一个地方工作得很好的规则,换一个场景可能带来大量的误杀。
最后,HTTP Flood攻击会引起严重的连锁反应,不仅仅是直接导致被攻击的Web前端响应缓慢,还间接攻击到后端的Java等业务层逻辑以及更后端的数据库服务,增大它们的压力,甚至对日志存储服务器都带来影响。
有意思的是,HTTP Flood还有个颇有历史渊源的昵称叫做CC攻击。CC是Challenge Collapsar的缩写,而Collapsar是国内一家著名安全公司的DDoS防御设备。从目前的情况来看,不仅仅是Collapsar,所有的硬件防御设备都还在被挑战着,风险并未解除。
提起攻击,第一反应就是海量的流量、海量的报文。但有一种攻击却反其道而行之,以慢著称,以至于有些攻击目标被打死了都不知道是怎么死的,这就是慢速连接攻击,最具代表性的是rsnake发明的Slowloris。
HTTP协议规定,HTTP Request以\r\n\r\n结尾表示客户端发送结束,服务端开始处理。那么,如果永远不发送\r\n\r\n会如何?Slowloris就是利用这一点来做DDoS攻击的。攻击者在HTTP请求头中将Connection设置为Keep-Alive,要求Web Server保持TCP连接不要断开,随后缓慢地每隔几分钟发送一个key-value格式的数据到服务端,如a:b\r\n,导致服务端认为HTTP头部没有接收完成而一直等待。如果攻击者使用多线程或者傀儡机来做同样的操作,服务器的Web容器很快就被攻击者占满了TCP连接而不再接受新的请求。
很快的,Slowloris开始出现各种变种。比如POST方法向Web Server提交数据、填充一大大Content-Length但缓慢的一个字节一个字节的POST真正数据内容等等。
以上介绍了几种基础的攻击手段,其中任意一种都可以用来攻击网络,甚至击垮阿里、百度、腾讯这种巨型网站。但这些并不是全部,不同层次的攻击者能够发起完全不同的DDoS攻击,运用之妙,存乎一心。
高级攻击者从来不会使用单一的手段进行攻击,而是根据目标环境灵活组合。普通的SYN Flood容易被流量清洗设备通过反向探测、SYN Cookie等技术手段过滤掉,但如果在SYN Flood中混入SYN+ACK数据包,使每一个伪造的SYN数据包都有一个与之对应的伪造的客户端确认报文,这里的对应是指源IP地址、源端口、目的IP、目的端口、TCP窗口大小、TTL等都符合同一个主机同一个TCP Flow的特征,流量清洗设备的反向探测和SYN Cookie性能压力将会显著增大。其实SYN数据报文配合其他各种标志位,都有特殊的攻击效果,这里不一一介绍。对DNS Query Flood而言,也有独特的技巧。
首先,DNS可以分为普通DNS和授权域DNS,攻击普通DNS,IP地址需要随机伪造,并且指明服务器要求做递归解析;但攻击授权域DNS,伪造的源IP地址则不应该是纯随机的,而应该是事先收集的全球各地ISP的DNS地址,这样才能达到最大攻击效果,使流量清洗设备处于添加IP黑名单还是不添加IP黑名单的尴尬处境。添加会导致大量误杀,不添加黑名单则每个报文都需要反向探测从而加大性能压力。
另一方面,前面提到,为了加大清洗设备的压力不命中缓存而需要随机化请求的域名,但需要注意的是,待解析域名必须在伪造中带有一定的规律性,比如说只伪造域名的某一部分而固化一部分,用来突破清洗设备设置的白名单。道理很简单,腾讯的服务器可以只解析腾讯的域名,完全随机的域名可能会直接被丢弃,需要固化。但如果完全固定,也很容易直接被丢弃,因此又需要伪造一部分。
其次,对DNS的攻击不应该只着重于UDP端口,根据DNS协议,TCP端口也是标准服务。在攻击时,可以UDP和TCP攻击同时进行。
HTTP Flood的着重点,在于突破前端的cache,通过HTTP头中的字段设置直接到达Web Server本身。另外,HTTP Flood对目标的选取也非常关键,一般的攻击者会选择搜索之类需要做大量数据查询的页面作为攻击目标,这是非常正确的,可以消耗服务器尽可能多的资源。但这种攻击容易被清洗设备通过人机识别的方式识别出来,那么如何解决这个问题?很简单,尽量选择正常用户也通过APP访问的页面,一般来说就是各种Web API。正常用户和恶意流量都是来源于APP,人机差别很小,基本融为一体难以区分。
之类的慢速攻击,是通过巧妙的手段占住连接不释放达到攻击的目的,但这也是双刃剑,每一个TCP连接既存在于服务端也存在于自身,自身也需要消耗资源维持TCP状态,因此连接不能保持太多。如果可以解决这一点,攻击性会得到极大增强,也就是说Slowloris可以通过stateless的方式发动攻击,在客户端通过嗅探捕获TCP的序列号和确认维护TCP连接,系统内核无需关注TCP的各种状态变迁,一台笔记本即可产生多达65535个TCP连接。
前面描述的,都是技术层面的攻击增强。在人的方面,还可以有一些别的手段。如果SYN Flood发出大量数据包正面强攻,再辅之以Slowloris慢速连接,多少人能够发现其中的秘密?即使服务器宕机了也许还只发现了SYN攻击想去加强TCP层清洗而忽视了应用层的行为。种种攻击都可以互相配合,达到最大的效果。攻击时间的选择,也是一大关键,比如说选择维护人员吃午饭时、维护人员下班堵在路上或者在地铁里无线上网卡都没有信号时、目标企业在举行大规模活动流量飙升时等。
前面的攻击方式,多多少少都需要一些傀儡机,即使是HTTP Flood也需要搜索大量的匿名代理。如果有一种攻击,只需要发出一些指令,就有机器自动上来执行,才是完美的方案。这种攻击已经出现了,那就是来自P2P网络的攻击。
大家都知道,互联网上的P2P用户和流量都是一个极为庞大的数字。如果他们都去一个指定的地方下载数据,使成千上万的真实IP地址连接过来,没有哪个设备能够支撑住。拿BT下载来说,伪造一些热门视频的种子,发布到搜索引擎,就足以骗到许多用户和流量了,但这只是基础攻击。
高级P2P攻击,是直接欺骗资源管理服务器。如迅雷客户端会把自己发现的资源上传到资源管理服务器,然后推送给其他需要下载相同资源的用户,这样,一个链接就发布出去。通过协议逆向,攻击者伪造出大批量的热门资源信息通过资源管理中心分发出去,瞬间就可以传遍整个P2P网络。更为恐怖的是,这种攻击是无法停止的,即使是攻击者自身也无法停止,攻击一直持续到P2P官方发现问题更新服务器且下载用户重启下载软件时为止。
谈到DDoS防御,首先就是要知道到底遭受了多大的攻击。这个问题看似简单,实际上却有很多不为人知的细节在里面。
以SYN Flood为例,为了提高发送效率在服务端产生更多的SYN等待队列,攻击程序在填充包头时,IP首部和TCP首部都不填充可选的字段,因此IP首部长度恰好是20字节,TCP首部也是20字节,共40字节。
对于以太网来说,最小的包长度数据段必须达到46字节,而攻击报文只有40字节,因此,网卡在发送时,会做一些处理,在TCP首部的末尾,填充6个0来满足最小包的长度要求。这个时候,整个数据包的长度为14字节的以太网头,20字节的IP头,20字节的TCP头,再加上因为最小包长度要求而填充的6个字节的0,一共是60字节。
但这还没有结束。以太网在传输数据时,还有CRC检验的要求。网卡会在发送数据之前对数据包进行CRC检验,将4字节的CRC值附加到包头的最后面。这个时候,数据包长度已不再是60字节,而是变成64字节了,这就是常说的SYN小包攻击,数据包结构如下:
| |14字节以太网头部 | 20字节IP头部 | 20字节TCP | 6字节填充 | 4字节检验 | 目的MAC | 源MAC | 协议类型 | IP头 | TCP头 | 以太网填充 | CRC检验 | |
到64字节时,SYN数据包已经填充完成,准备开始传输了。攻击数据包很小,远远不够最大传输单元(MTU)的1500字节,因此不会被分片。那么这些数据包就像生产流水线上的罐头一样,一个包连着一个包紧密地挤在一起传输吗?事实上不是这样的。
以太网在传输时,还有前导码(preamble)和帧间距(inter-frame gap)。其中前导码占8字节(byte),即64比特位。前导码前面的7字节都是10101010,1和0间隔而成。但第八个字节就变成了10101011,当主机监测到连续的两个1时,就知道后面开始是数据了。在网络传输时,数据的结构如下:
| | 8字节前导码 | 6字节目的MAC地址 | 6字节源MAC地址 | 2字节上层协议类型 | 20字节IP头 | 20字节TCP头 | 6字节以太网填充 | 4字节CRC检验 | 12字节帧间距 | |
有了上面的基础,现在可以开始计算攻击流量和网络设备的线速问题了。当只填充IP头和TCP头的最小SYN包跑在以太网络上时,100Mbit的网络,能支持的最大PPS(Packet Per Second)是100×106 / (8 * (64+8+12)) = 148809,1000Mbit的网络,能支持的最大PPS是1488090。
前文描述过,SYN Flood攻击大量消耗服务器的CPU、内存资源,并占满SYN等待队列。相应的,我们修改内核参数即可有效缓解。主要参数如下:
| net.ipv4.tcp_syncookies = 1net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_synack_retries = 2 |
分别为启用SYN Cookie、设置SYN最大队列长度以及设置SYN+ACK最大重试次数。
SYN Cookie的作用是缓解服务器资源压力。启用之前,服务器在接到SYN数据包后,立即分配存储空间,并随机化一个数字作为SYN号发送SYN+ACK数据包。然后保存连接的状态信息等待客户端确认。启用SYN Cookie之后,服务器不再分配存储空间,而且通过基于时间种子的随机数算法设置一个SYN号,替代完全随机的SYN号。发送完SYN+ACK确认报文之后,清空资源不保存任何状态信息。直到服务器接到客户端的最终ACK包,通过Cookie检验算法鉴定是否与发出去的SYN+ACK报文序列号匹配,匹配则通过完成握手,失败则丢弃。当然,前文的高级攻击中有SYN混合ACK的攻击方法,则是对此种防御方法的反击,其中优劣由双方的硬件配置决定
tcp_max_syn_backlog则是使用服务器的内存资源,换取更大的等待队列长度,让攻击数据包不至于占满所有连接而导致正常用户无法完成握手。net.ipv4.tcp_synack_retries是降低服务器SYN+ACK报文重试次数,尽快释放等待资源。这三种措施与攻击的三种危害一一对应,完完全全地对症下药。但这些措施也是双刃剑,可能消耗服务器更多的内存资源,甚至影响正常用户建立TCP连接,需要评估服务器硬件资源和攻击大小谨慎设置。
除了定制TCP/IP协议栈之外,还有一种常见做法是TCP首包丢弃方案,利用TCP协议的重传机制识别正常用户和攻击报文。当防御设备接到一个IP地址的SYN报文后,简单比对该IP是否存在于白名单中,存在则转发到后端。如不存在于白名单中,检查是否是该IP在一定时间段内的首次SYN报文,不是则检查是否重传报文,是重传则转发并加入白名单,不是则丢弃并加入黑名单。是首次SYN报文则丢弃并等待一段时间以试图接受该IP的SYN重传报文,等待超时则判定为攻击报文加入黑名单。
首包丢弃方案对用户体验会略有影响,因为丢弃首包重传会增大业务的响应时间,有鉴于此发展出了一种更优的TCP Proxy方案。所有的SYN数据报文由清洗设备接受,按照SYN Cookie方案处理。和设备成功建立了TCP三次握手的IP地址被判定为合法用户加入白名单,由设备伪装真实客户端IP地址再与真实服务器完成三次握手,随后转发数据。而指定时间内没有和设备完成三次握手的IP地址,被判定为恶意IP地址屏蔽一定时间。除了SYN Cookie结合TCP Proxy外,清洗设备还具备多种畸形TCP标志位数据包探测的能力,通过对SYN报文返回非预期应答测试客户端反应的方式来鉴别正常访问和恶意行为。
清洗设备的硬件具有特殊的网络处理器芯片和特别优化的操作系统、TCP/IP协议栈,可以处理非常巨大的流量和SYN队列。
HTTP Flood攻击防御主要通过缓存的方式进行,尽量由设备的缓存直接返回结果来保护后端业务。大型的互联网企业,会有庞大的CDN节点缓存内容。
当高级攻击者穿透缓存时,清洗设备会截获HTTP请求做特殊处理。最简单的方法就是对源IP的HTTP请求频率做统计,高于一定频率的IP地址加入黑名单。这种方法过于简单,容易带来误杀,并且无法屏蔽来自代理服务器的攻击,因此逐渐废止,取而代之的是JavaScript跳转人机识别方案。
HTTP Flood是由程序模拟HTTP请求,一般来说不会解析服务端返回数据,更不会解析JS之类代码。因此当清洗设备截获到HTTP请求时,返回一段特殊JavaScript代码,正常用户的浏览器会处理并正常跳转不影响使用,而攻击程序会攻击到空处。
DNS攻击防御也有类似HTTP的防御手段,第一方案是缓存。其次是重发,可以是直接丢弃DNS报文导致UDP层面的请求重发,可以是返回特殊响应强制要求客户端使用TCP协议重发DNS查询请求。
特殊的,对于授权域DNS的保护,设备会在业务正常时期提取收到的DNS域名列表和ISP DNS IP列表备用,在攻击时,非此列表的请求一律丢弃,大幅降低性能压力。对于域名,实行同样的域名白名单机制,非白名单中的域名解析请求,做丢弃处理。
Slowloris攻击防御比较简单,主要方案有两个。
第一个是统计每个TCP连接的时长并计算单位时间内通过的报文数量即可做精确识别。一个TCP连接中,HTTP报文太少和报文太多都是不正常的,过少可能是慢速连接攻击,过多可能是使用HTTP 1.1协议进行的HTTP Flood攻击,在一个TCP连接中发送多个HTTP请求。
第二个是限制HTTP头部传输的最大许可时间。超过指定时间HTTP Header还没有传输完成,直接判定源IP地址为慢速连接攻击,中断连接并加入黑名单。
互联网企业防御DDoS攻击,主要还是使用上文的基础防御手段, 重点在于使用监控、组织以及流程等东西来保障及时、正确的使用这些手段,并根据攻击策略的改变而改变。
监控需要具备多层监控、纵深防御的概念,从骨干网络、IDC入口网络的BPS、PPS、协议分布,负载均衡层的VIP新建连接数、并发连接数、BPS、PPS到主机层的CPU状态、TCP新建连接数状态、TCP并发连接数状态,到业务层的业务处理量、业务连通性等多个点部署监控系统。即使一个监控点失效,其他监控点也能够及时给出报警信息。多个点的信息结合起来,有助于准确的判断攻击目标和攻击手法。
一旦发现异常,立即启动在虚拟防御组织中的应急流程。防御组织需要囊括到足够全面的人员,至少包含监控部门、运维部门、网络部门、安全部门、客服部门、业务部门等,所有人员都需要2-3个备份。流程启动后,除了人工处理,还应该包含一定的自动处理、半自动处理能力。例如自动化的攻击分析,确定攻击类型,自动化、半自动化的防御策略,在安全人员到位之前,最先发现攻击的部门可以做一些缓解措施。
除了DDoS到来之时的流程等工作之外,更多的工作是在攻击到来之前。主要包含CDN节点部署、DNS设置、流程演习等。对于企业来说,具备多个CDN节点是DDoS防御容量的关键指标。当一个机房承担不住海量数据时,可以通过DNS轮询的方式,把流量引导到多个分布节点,使用防御设备分头处理。因此DNS的TTL值需要设置得足够小,能够快速切换,每个CDN节点的各种VIP设置也需要准备充分。
DRDoS(分布式反射攻击)最早在2004年左右就出现了,当时的DRDoS攻击不具备放大流量的能力,某种意义上说类似拿冲锋枪打墙,依靠反射回来的弹壳伤人,攻击力不升反降,因而并没有流行开来。
但是从2013年开始,DRDoS已经是互联网上最流行、最吸引眼球的DDoS攻击手段了,因为它附加流量放大属性,通过史无前例的海量流量击败了如日中天的云安全公司CloudFlare,引得大小黑客纷纷仿效。
DRDoS攻击的原理是黑客伪造成受害者的IP地址,向互联网上大量开放特定服务的主机发起请求,接收到请求的那些主机根据源IP地址将响应数据包返回给受害者。整个过程中,大量的无辜主机完全不知情,成为黑客攻击的帮凶。一般来说,黑客会使用响应包远大于请求包的服务来利用,这样才可以以较小的流量换取交大的流量去攻击,几十倍的放大攻击。能利用来做放大反射攻击的服务,常见的有DNS服务、NTP服务、SNMP服务、Chargen服务等等,甚至某些online游戏服务器也被利用来参与攻击。
CloudFlare在2013年遭受的300Gbps的攻击属于DNS反射攻击,当时导致他们全网故障。在2014年2月,它们遭受了前所未见的400Gbps的攻击,黑客使用了NTP服务进行放大。
互联网上有非常多的时间服务器,通过NTP协议提供对时服务。但是它缺乏身份认证手段,可以被任意使用。更重要的是,NTP协议有一个指令monlist可以列举出最近同步过时间的600个主机列表,如下图:
攻击者发出的Monlist指令只有1个数据包,耗费几十个字节,而返回包多达几十个,耗费2000-3000字节甚至更大,达到约50倍的放大。越是繁忙的NTP服务器,这个放大倍数越大。
攻击者只需要100Mbps的请求流量,可以换来5Gbps的攻击流量,效率非常高。其它的DNS放大、SNMP放大、Chargen放大与NTP放大原理一致,只是使用的协议有区别,不一一描述。
反射攻击利用的协议,一般同时具有3种特征:容易伪造源IP地址、无身份认证、响应包远大于请求包。因此,基于UDP的DNS协议、NTP协议、Chargen协议、SNMP协议成为首选。那么,是不是只有基于UDP的上层协议才能够用来做放大反射攻击,需要完成三次握手才能开始业务会话的基于TCP的上层协议就无法利用了?其实不是。
Chargen是一个常见的测试网络连通性服务,同时工作在UDP协议和TCP协议上。对于它监听的TCP端口,只要有客户端连上,就会源源不断的向客户端返回随机字符串,永不停止。可以想象,如果这个东西可以利用起来做攻击,无穷倍数的放大,是何等厉害。但是很遗憾,TCP不能伪造源IP地址,除非攻击者能够让攻击目标主动连接到Chargen的TCP端口去。
这种事情,恰好是代理协议做的事情!如果攻击目标是HTTP Proxy或者Socks5 Proxy,攻击者只需要连接上目标的代理端口,然后去访问Chargen服务并保持TCP连接不断掉就行了。以HTTP代理为例,直接连接target的3128端口,然后发出类似 http://chargen_server.com:19这样的请求即可,socks5代理类似。
使用Chargen攻击代理服务器效果虽好,但是毕竟应用范围比较狭窄,一般的攻击目标都是网站。黑客的创意在这儿展露无遗,他们也有各种新奇的手法,比如利用Google的某些服务或者Wordpress之类的博客来做DDoS攻击。
Google有一个叫做FeedFetcher的爬虫,为Google Feed API提供后端支持,会定期抓取RSS以及其它各种数据,如他们的电子表格服务spreadsheet中的链接。当电子表格服务中存在内容=image(“http://example.com/image.jpg”)时,Google就会“派出”FeedFetcher爬虫去抓取这个图片并保存到缓存中以将其显示出来。
恶意攻击者会找一个较大的文件,给文件名附加上随机参数,使FeedFetcher多次抓取这个文件。也就是说,如果一个网站有一个10MB的文件,将以下列表输入到Google spreadsheet中,那么Google的爬虫就会抓取该文件1000次,使网站产生大量出站流量。
如果是带宽比较小的站点,面对这种攻击时会非常痛苦。拦截会影响SEO效果,不拦截则需要付出更多的带宽租赁费用。
=image(“http://targetname/file.pdf?r=0″) =image(“http://targetname/file.pdf?r=1″) =image(“http://targetname/file.pdf?r=2″) =image(“http://targetname/file.pdf?r=3″) … =image(“http://targetname/file.pdf?r=1000″)
基于类似的原理,Wordpress博客的pingback功能也可以用来做反射攻击。PingBack是用来通知blog系统有文章被引用的一种手段。向http://www.anywordpresssite.com/xmlrpc.php 提交POST请求, 数据格式如下:
<methodCall> <methodName> pingback.ping </methodName> <params> <param> <value> <string>http://victim.com/post.php?id=1</string> </value> </param> <param> <value> <string>http://www.anywordpresssite.com/pst?id=111</string> </value> </param> </params> </methodCall>
则服务器www.anywordpresssite.com会向 http://victim.com/post.php?id=1发起GET请求。如果攻击者同时向大量的开启了pingback的blog系统提交请求,则有大量的GET请求涌向攻击目标,更多的更多细节可以见 http://drops.wooyun.org/news/1062。
但是就我看来,pingback这样的反射攻击意义不大,因为流量和请求次数都没有被放大,如果单纯是为了隐藏自己,可以选择通过proxy的方式发起攻击。更好的做法应该是向某个开启了pingback的blog a发送大量的POST包(这里的POST包通过代理发起),让它去ping大量的blog,然后大量的http response会同攻击者发起的POST包一起淹没blog a,这才是优雅的反射放大攻击——付出的代价是这种攻击方式仅对有pingback功能的系统起作用
TCP的反射攻击有可能发生,但是危害程度远不如UDP,而且发起难度较大,需要很多诡异的条件配合。因此,防御上无需做过多考虑,将目光主要集中到基于UDP的反射放大攻击。
首先,我们需要足够大的带宽,没有带宽一切都枉然。一般的,带宽可以通过CDN的方式提供,将业务分散到不同地区的不同机房。
其次,从DRDos的本质知道,这种反射攻击数据包的源端口一定是固定的,NTP放大攻击源端口一定是UDP 123端口,DNS放大攻击源端口一定是UDP 53端口。这其实是一个很好的特征,也是攻击者不愿意却不得不留下的特征——有得到就有代价。在带宽足够的情况下,可以在网络边界部署ACL策略,禁止外网进来的源端口是UDP 123的报文,禁止外网进来的源端口是UDP 161的报文,禁止外网进来的源端口是UDP 19的报文,诸如此类。源端口是UDP 53的也可以过滤?也可以的,至少大部分IP地址可以无需请求外部的DNS服务。
这里涉及到一条防御准则,可以三层过滤的不要在四层做,可以在四层做的过滤不要到七层做。越往上,解析开销越大
最常见的SYN Flood防御手段是SYN Cookie和SYN Proxy,它们原理简单,而且效果也非常好。
在正常情况下,服务器端接收到客户端发送的SYN包,会分配一个连接请求块(即request_sock结构)用于保存连接信息,然后发送SYN+ACK包给客户端,并将连接请求块添加到半连接队列中,没收到最后一个ACK的话就轮询重发SYN+ACK包。
对于启用了SYN Cookie的服务器,不会这样处理,它不维持任何连接信息, 而是将源IP、目的IP、源端口、目的端口、SYN序列号等信息进行hash运算,生成一个数字称之为cookie。服务端将这个cookie作为SYN+ACK包的ACK确认号发送给客户端,然后对这个IP发过来的后续ACK包的确认号进行验算,与Cookie吻合的说明是正确的报文,正常建立连接,而攻击的报文直接没有了任何后续动作,也没有额外开销。
SYN Proxy则是管家式的防御,它站在攻击者和目标服务器之间,伪装成目标服务器对所有的SYN报文进行应答,包括攻击者在内。当三次握手正确的建立起来后,就伪装成客户端IP地址与后端的目标服务器建立三次握手,然后转发数据,需要注意的是,TCP三次握手在这里变成了6次握手,而且两个握手内的ACK号肯定不一致,需要做一个修正。
SYN Cookie可以和SYN Proxy无缝集成,协同工作,提供更好的防御服务,基本上100%无误杀。那么使用这种防御手段,付出的代价是什么?
我们可以看到,SYN Cookie和SYN Proxy对每一个SYN包都会进行答复,如果攻击者发送1Gbps的报文过来,防御方会发送1Gbps的报文回去。10Gbps就10Gbps,100Gbps就100Gbps。问题是,企业网络禁得起这种折腾么?基本上,攻击流量达到一定程度,网络不攻自溃。
对于过大的反弹流量的问题,安全厂商想出了许多新的办法,那就是在答复之前做一些测试,能轻易过滤的流量就不反弹了。最主要的是随机丢包策略,直接粗暴的丢弃SYN包,按照TCP协议正常的用户会在3秒内重发这个SYN包,攻击流量的源IP是伪造的,因此直接被丢弃了没有任何后续。
这个方案看起来对SYN Cookie之类技术是一个很好的补充,但是也有一些问题。首先,正常用户的体验受到影响,访问业务的速度变慢了。其次是某些高级攻击者可以利用这个手段,绕过防御,简单的说,同样的SYN包发两次有可能被判定为正常访问。一旦被防御设备加入白名单,后续的报文就直接漏过了。
除了SYN Cookie、Proxy技术之外,还有一种反向探测的技术,也是颇为流行。防御设备接收到SYN包时,回复一个ACK确认号错误的SYN+ACK报文。按照协议,客户端会发一个RST报文过来重置连接。攻击者一般是伪造源IP地址,没有人会帮他做这个应答,SYN包被直接过滤掉。
这个方案,在实际环境中会遇到一些问题。某些防火墙设备,包括iptables,会过滤掉ACK号错误的SYN+ACK包,导致正常用户的RST包发不过来而导致被误杀。因此,考虑到稳定可靠,防御设备回复的SYN+ACK包的ACK确认号需要满足某些特征,比如小于或者等于SYN确认号。
对于攻击者而言,他们可以通过tcp ping的方式扫描到真实存活的主机列表,然后使用这些IP地址作为源IP地址发起攻击,可以有效绕过这种防御手段。虽然一般的攻击是要伪造不存在的源IP以达到更好的效果,但是这里则要反其道而行之。
标签:访问 header image 最小 tables cond get请求 关联 border
原文地址:http://www.cnblogs.com/alwayswangzi/p/7224710.html