标签:des style blog http os io 使用 strong ar
线性回归与梯度下降算法
作者:上品物语
知识点:
l 批量梯度下降算法
l 随机梯度下降算法
l 算法收敛判断方法
1.1 线性回归
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
下面我们来举例何为一元线性回归分析,图1为某地区的房屋面积(feet)与价格($)的一个数据集,在该数据集中,只有一个自变量面积(feet),和一个因变量价格($),所以我们可以将数据集呈现在二维空间上,如图2所示。利用该数据集,我们的目的是训练一个线性方程,无限逼近所有数据点,然后利用该方程与给定的某一自变量(本例中为面积),可以预测因变量(本例中为房价)。本例中,训练所得的线性方程如图3所示。
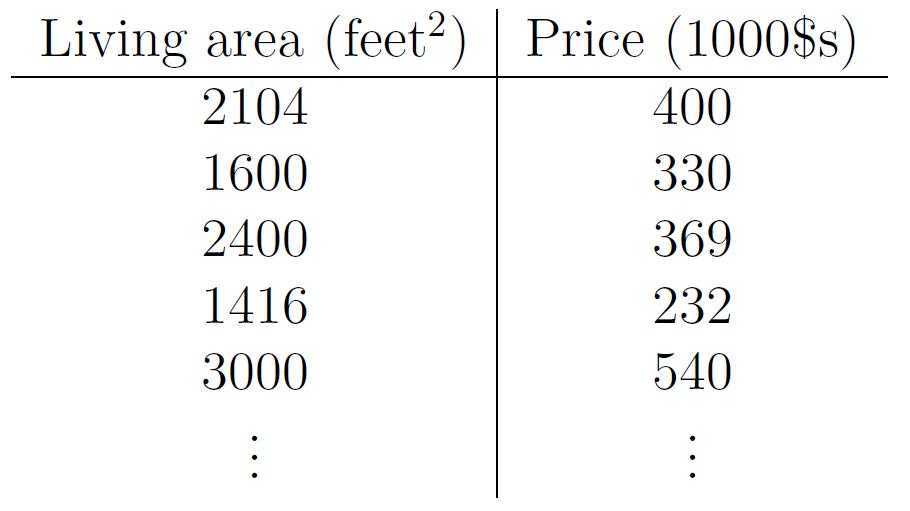
图1、房价与面积对应数据集
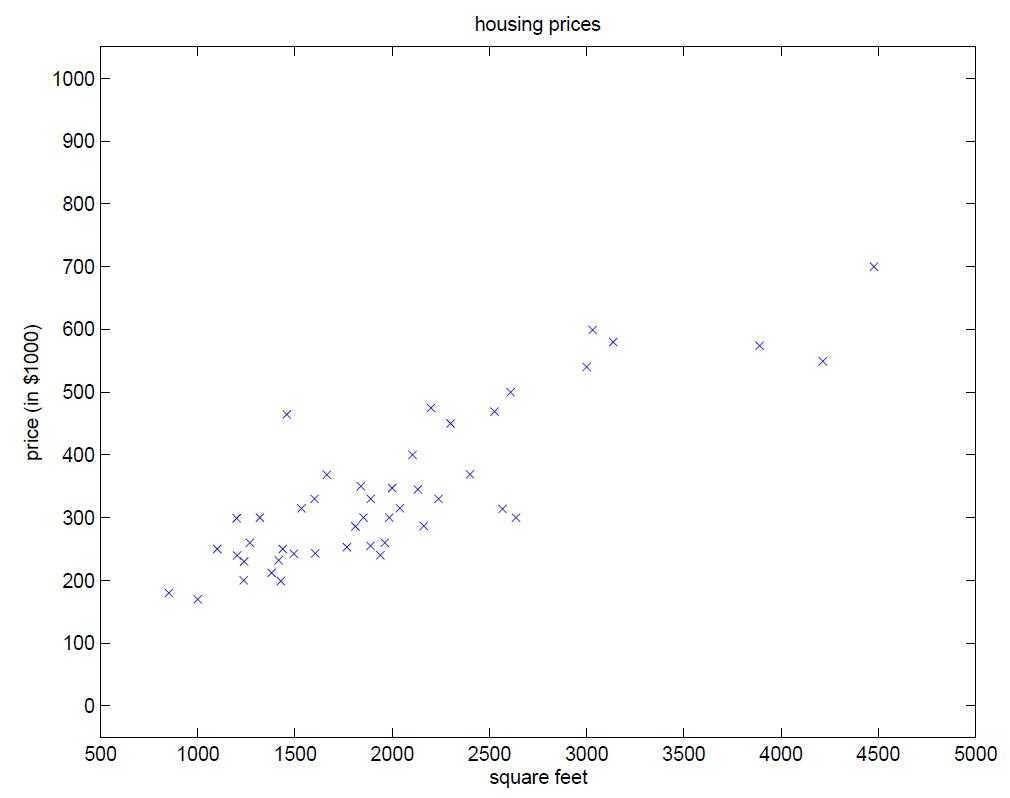
图2、二维空间上的房价与面积对应图
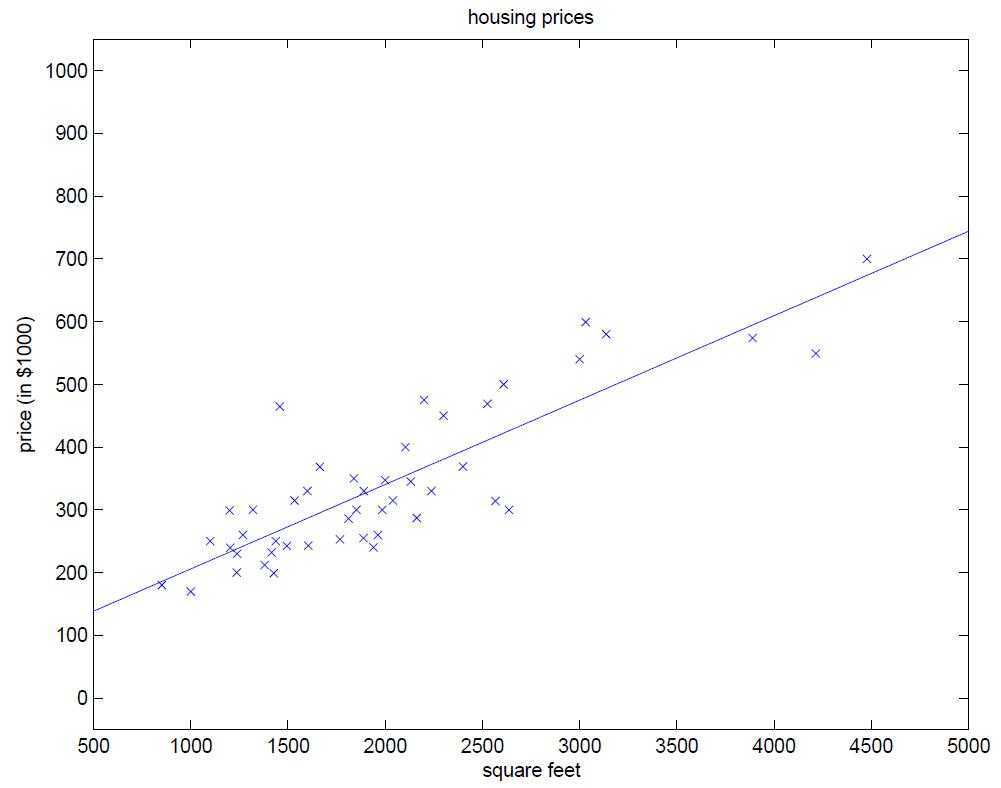
图3、线性逼近
同时,分析得到的线性方程为:
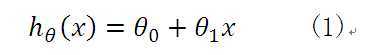
接下来还是该案例,举一个多元线性回归的例子。如果增添了一个自变量:房间数,那么数据集可以如下所示:
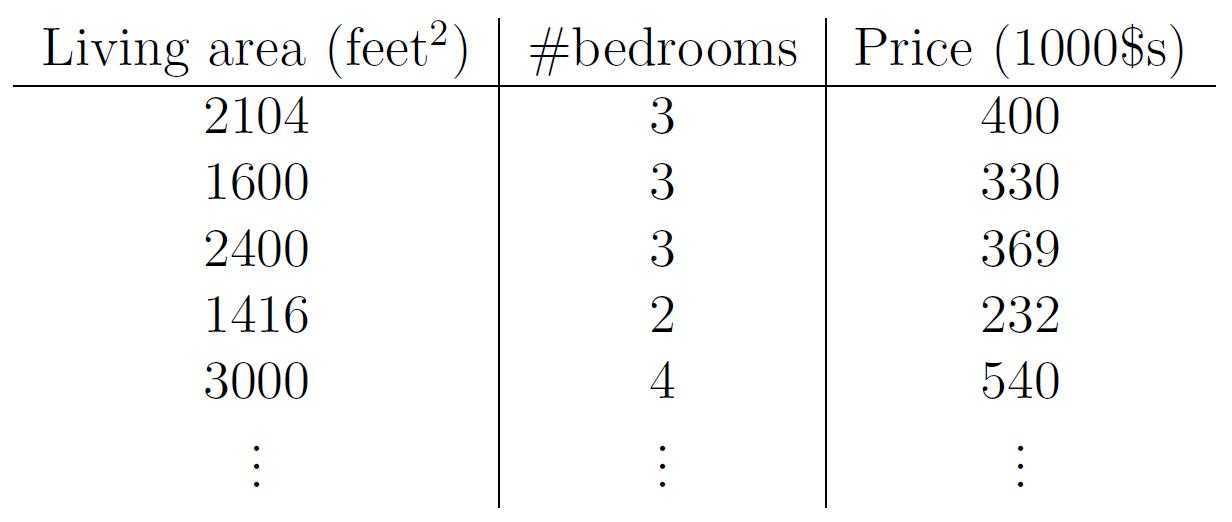
图4、房价与面积、房间数对应数据集
那么,分析得到的线性方程应如下所示:
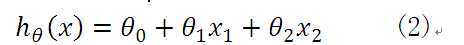
因此,无论是一元线性方程还是多元线性方程,可统一写成如下的格式:
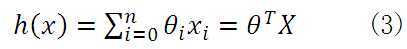
上式中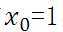 ,而求线性方程则演变成了求方程的参数
,而求线性方程则演变成了求方程的参数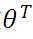 。
。
线性回归假设特征和结果满足线性关系。其实线性关系的表达能力非常强大,每个特征对结果的影响强弱可以有前面的参数体现,而且每个特征变量可以首先映射到一个函数,然后再参与线性计算,这样就可以表达特征与结果之间的非线性关系。
1.2 梯度下降算法
为了得到目标线性方程,我们只需确定公式(3)中的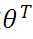 ,同时为了确定所选定的的
,同时为了确定所选定的的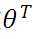 效果好坏,通常情况下,我们使用一个损失函数(loss function)或者说是错误函数(error function)来评估
效果好坏,通常情况下,我们使用一个损失函数(loss function)或者说是错误函数(error function)来评估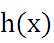 函数的好坏。该错误函数如公式(4)所示。
函数的好坏。该错误函数如公式(4)所示。
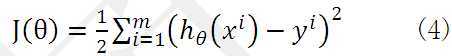
如何调整以使得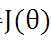 取得最小值有很多方法,其中有完全用数学描述的最小二乘法(min square)和梯度下降法。
取得最小值有很多方法,其中有完全用数学描述的最小二乘法(min square)和梯度下降法。
1.2.1 批量梯度下降算法
由之前所述,求的问题演变成了求的极小值问题,这里使用梯度下降法。而梯度下降法中的梯度方向由对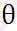 的偏导数确定,由于求的是极小值,因此梯度方向是偏导数的反方向。
的偏导数确定,由于求的是极小值,因此梯度方向是偏导数的反方向。
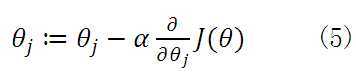
公式(5)中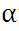 为学习速率,当过大时,有可能越过最小值,而当过小时,容易造成迭代次数较多,收敛速度较慢。假如数据集中只有一条样本,那么样本数量,所以公式(5)中
为学习速率,当过大时,有可能越过最小值,而当过小时,容易造成迭代次数较多,收敛速度较慢。假如数据集中只有一条样本,那么样本数量,所以公式(5)中
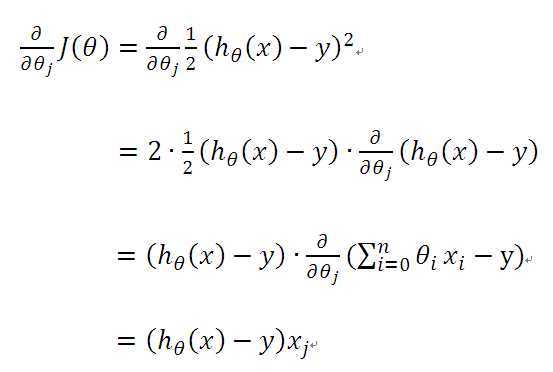
所以公式(5)就演变成:
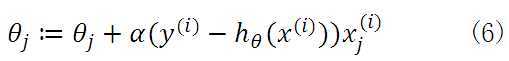
当样本数量m不为1时,将公式(5)中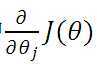 由公式(4)带入求偏导,那么每个参数沿梯度方向的变化值由公式(7)求得。
由公式(4)带入求偏导,那么每个参数沿梯度方向的变化值由公式(7)求得。
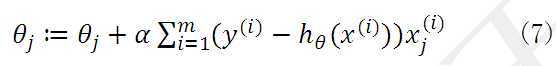
初始时可设为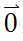 ,然后迭代使用公式(7)计算中的每个参数,直至收敛为止。由于每次迭代计算时,都使用了整个样本集,因此我们称该梯度下降算法为批量梯度下降算法(batch gradient descent)。
,然后迭代使用公式(7)计算中的每个参数,直至收敛为止。由于每次迭代计算时,都使用了整个样本集,因此我们称该梯度下降算法为批量梯度下降算法(batch gradient descent)。
1.2.2 随机梯度下降算法
当样本集数据量m很大时,批量梯度下降算法每迭代一次的复杂度为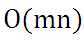 ,复杂度很高。因此,为了减少复杂度,当m很大时,我们更多时候使用随机梯度下降算法(stochastic gradient descent),算法如下所示:
,复杂度很高。因此,为了减少复杂度,当m很大时,我们更多时候使用随机梯度下降算法(stochastic gradient descent),算法如下所示:
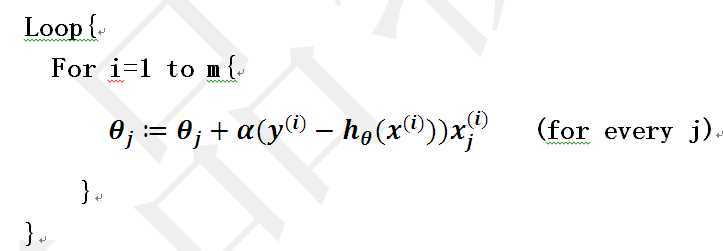
即每读取一条样本,就迭代对进行更新,然后判断其是否收敛,若没收敛,则继续读取样本进行处理,如果所有样本都读取完毕了,则循环重新从头开始读取样本进行处理。
这样迭代一次的算法复杂度为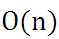 。对于大数据集,很有可能只需读取一小部分数据,函数就收敛了。比如样本集数据量为100万,有可能读取几千条或几万条时,函数就达到了收敛值。所以当数据量很大时,更倾向于选择随机梯度下降算法。
。对于大数据集,很有可能只需读取一小部分数据,函数就收敛了。比如样本集数据量为100万,有可能读取几千条或几万条时,函数就达到了收敛值。所以当数据量很大时,更倾向于选择随机梯度下降算法。
但是,相较于批量梯度下降算法而言,随机梯度下降算法使得趋近于最小值的速度更快,但是有可能造成永远不可能收敛于最小值,有可能一直会在最小值周围震荡,但是实践中,大部分值都能够接近于最小值,效果也都还不错。
1.2.3 算法收敛判断方法
的变化距离为0,或者说变化距离小于某一阈值(中每个参数的变化绝对值都小于一个阈值)。为减少计算复杂度,该方法更为推荐使用。不再变化,或者说变化程度小于某一阈值。计算复杂度较高,但是如果为了精确程度,那么该方法更为推荐使用。标签:des style blog http os io 使用 strong ar
原文地址:http://www.cnblogs.com/eczhou/p/3951861.html