标签:span 如何使用 set lda indent 运算 示例 white ora
前言
编写 CUDA 程序真心不是个简单的事儿,调试也不方便,很费时。那么有没有一些现成的 CUDA 库来调用呢?
答案是有的,如 CUBLAS 就是 CUDA 专门用来解决线性代数运算的库。
本文将大致介绍如何使用 CUBLAS 库,同时演示一个使用 CUBLAS 库进行矩阵乘法的例子。
CUBLAS 内容
CUBLAS 是 CUDA 专门用来解决线性代数运算的库,它分为三个级别:
Lev1. 向量相乘
Lev2. 矩阵乘向量
Lev3. 矩阵乘矩阵
同时该库还包含状态结构和一些功能函数。
CUBLAS 用法
大体分成以下几个步骤:
1. 定义 CUBLAS 库对象
2. 在显存中为待运算的数据以及需要存放结果的变量开辟显存空间。( cudaMalloc 函数实现 )
3. 将待运算的数据传输进显存。( cudaMemcpy,cublasSetVector 等函数实现 )
3. 调用 CUBLAS 库函数 ( 根据 CUBLAS 手册调用需要的函数 )
4. 从显存中获取结果变量。( cudaMemcpy,cublasGetVector 等函数实现 )
5. 释放申请的显存空间以及 CUBLAS 库对象。( cudaFree 及 cublasDestroy 函数实现 )
代码示例
如下程序使用 CUBLAS 库进行矩阵乘法运算,请仔细阅读注释,尤其是 API 的参数说明:

1 // CUDA runtime 库 + CUBLAS 库 2 #include "cuda_runtime.h" 3 #include "cublas_v2.h" 4 5 #include <time.h> 6 #include <iostream> 7 8 using namespace std; 9 10 // 定义测试矩阵的维度 11 int const M = 5; 12 int const N = 10; 13 14 int main() 15 { 16 // 定义状态变量 17 cublasStatus_t status; 18 19 // 在 内存 中为将要计算的矩阵开辟空间 20 float *h_A = (float*)malloc (N*M*sizeof(float)); 21 float *h_B = (float*)malloc (N*M*sizeof(float)); 22 23 // 在 内存 中为将要存放运算结果的矩阵开辟空间 24 float *h_C = (float*)malloc (M*M*sizeof(float)); 25 26 // 为待运算矩阵的元素赋予 0-10 范围内的随机数 27 for (int i=0; i<N*M; i++) { 28 h_A[i] = (float)(rand()%10+1); 29 h_B[i] = (float)(rand()%10+1); 30 31 } 32 33 // 打印待测试的矩阵 34 cout << "矩阵 A :" << endl; 35 for (int i=0; i<N*M; i++){ 36 cout << h_A[i] << " "; 37 if ((i+1)%N == 0) cout << endl; 38 } 39 cout << endl; 40 cout << "矩阵 B :" << endl; 41 for (int i=0; i<N*M; i++){ 42 cout << h_B[i] << " "; 43 if ((i+1)%M == 0) cout << endl; 44 } 45 cout << endl; 46 47 /* 48 ** GPU 计算矩阵相乘 49 */ 50 51 // 创建并初始化 CUBLAS 库对象 52 cublasHandle_t handle; 53 status = cublasCreate(&handle); 54 55 if (status != CUBLAS_STATUS_SUCCESS) 56 { 57 if (status == CUBLAS_STATUS_NOT_INITIALIZED) { 58 cout << "CUBLAS 对象实例化出错" << endl; 59 } 60 getchar (); 61 return EXIT_FAILURE; 62 } 63 64 float *d_A, *d_B, *d_C; 65 // 在 显存 中为将要计算的矩阵开辟空间 66 cudaMalloc ( 67 (void**)&d_A, // 指向开辟的空间的指针 68 N*M * sizeof(float) // 需要开辟空间的字节数 69 ); 70 cudaMalloc ( 71 (void**)&d_B, 72 N*M * sizeof(float) 73 ); 74 75 // 在 显存 中为将要存放运算结果的矩阵开辟空间 76 cudaMalloc ( 77 (void**)&d_C, 78 M*M * sizeof(float) 79 ); 80 81 // 将矩阵数据传递进 显存 中已经开辟好了的空间 82 cublasSetVector ( 83 N*M, // 要存入显存的元素个数 84 sizeof(float), // 每个元素大小 85 h_A, // 主机端起始地址 86 1, // 连续元素之间的存储间隔 87 d_A, // GPU 端起始地址 88 1 // 连续元素之间的存储间隔 89 ); 90 cublasSetVector ( 91 N*M, 92 sizeof(float), 93 h_B, 94 1, 95 d_B, 96 1 97 ); 98 99 // 同步函数 100 cudaThreadSynchronize(); 101 102 // 传递进矩阵相乘函数中的参数,具体含义请参考函数手册。 103 float a=1; float b=0; 104 // 矩阵相乘。该函数必然将数组解析成列优先数组 105 cublasSgemm ( 106 handle, // blas 库对象 107 CUBLAS_OP_T, // 矩阵 A 属性参数 108 CUBLAS_OP_T, // 矩阵 B 属性参数 109 M, // A, C 的行数 110 M, // B, C 的列数 111 N, // A 的列数和 B 的行数 112 &a, // 运算式的 α 值 113 d_A, // A 在显存中的地址 114 N, // lda 115 d_B, // B 在显存中的地址 116 M, // ldb 117 &b, // 运算式的 β 值 118 d_C, // C 在显存中的地址(结果矩阵) 119 M // ldc 120 ); 121 122 // 同步函数 123 cudaThreadSynchronize(); 124 125 // 从 显存 中取出运算结果至 内存中去 126 cublasGetVector ( 127 M*M, // 要取出元素的个数 128 sizeof(float), // 每个元素大小 129 d_C, // GPU 端起始地址 130 1, // 连续元素之间的存储间隔 131 h_C, // 主机端起始地址 132 1 // 连续元素之间的存储间隔 133 ); 134 135 // 打印运算结果 136 cout << "计算结果的转置 ( (A*B)的转置 ):" << endl; 137 138 for (int i=0;i<M*M; i++){ 139 cout << h_C[i] << " "; 140 if ((i+1)%M == 0) cout << endl; 141 } 142 143 // 清理掉使用过的内存 144 free (h_A); 145 free (h_B); 146 free (h_C); 147 cudaFree (d_A); 148 cudaFree (d_B); 149 cudaFree (d_C); 150 151 // 释放 CUBLAS 库对象 152 cublasDestroy (handle); 153 154 getchar(); 155 156 return 0; 157 }
运行测试
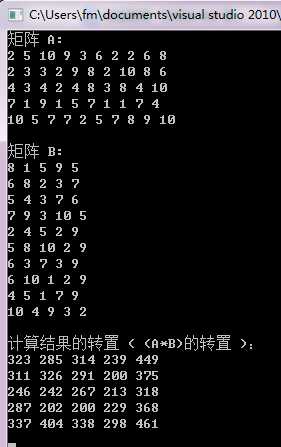
PS:矩阵元素是随机生成的
小结
1. 使用 CUDA 库固然方便,但也要仔细的参阅函数手册,其中每个参数的含义都要很清晰才不容易出错。
2. 如果程序仅使用 CUDA 库的话,用 .cpp 源码文件即可 (不用 .cu)
标签:span 如何使用 set lda indent 运算 示例 white ora
原文地址:http://www.cnblogs.com/hdk1993/p/7237079.html