Yarn在Hadoop的生态系统中担任了资源管理和任务调度的角色。在讨论其构造器之前先简单了解一下Yarn的架构。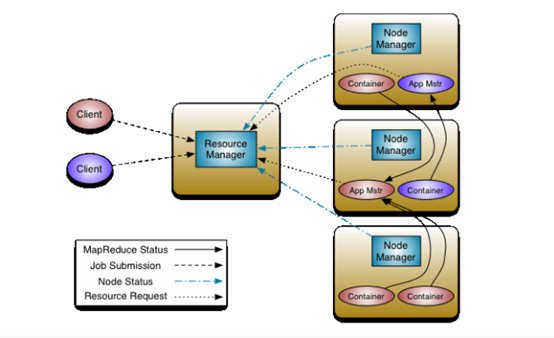
上图是Yarn的基本架构,其中ResourceManager是整个架构的核心组件,它负责整个集群中包括内存、CPU等资源的管理;ApplicationMaster负责应用程序在整个生命周期的任务调度;NodeManager负责本节点上资源的供给和隔离;Container可以抽象的看成是运行任务的一个容器。本文讨论的调度器是在ResourceManager组建中进行调度的,接下来就一起研究一下包括FIFO调度器、Capacity调度器、Fair调度器在内的三个调度器。
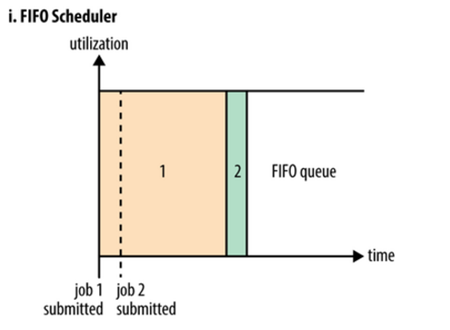
上图为FIFO调度器的执行过程示意图。FIFO调度器也就是平时所说的先进先出(First In First Out)调度器。FIFO调度器是Hadoop最早应用的一种调度策略,可以简单的将其理解为一个Java队列,它的含义在于集群中同时只能有一个作业在运行。将所有的Application按照提交时候的顺序来执行,只有当上一个Job执行完成之后后面的Job才会按照队列的顺序依次被执行。FIFO调度器以集群资源独占的方式来运行作业,这样的好处是一个作业可以充分利用所有的集群资源,但是对于运行时间短,重要性高或者交互式查询类的MR作业就要等待排在序列前的作业完成才能被执行,这也就导致了如果有一个非常大的Job在运行,那么后面的作业将会被阻塞。因此,虽然单一的FIFO调度实现简单,但是对于很多实际的场景并不能满足要求。这也就催发了Capacity调度器和Fair调度器的出现。
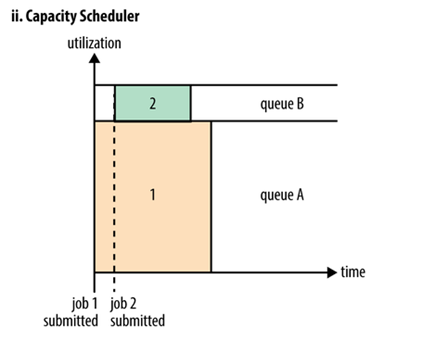
上图是Capacity调度器的执行过程示意图。Capacity调度器也就是日常说的容器调度器。可以将它理解成一个个的资源队列。这个资源队列是用户自己去分配的。例如因为工作所需要把整个集群分成了AB两个队列,A队列下面还可以继续分,比如将A队列再分为1和2两个子队列。那么队列的分配就可以参考下面的树形结构:
—A[60%]
|—A.1[40%]
|—A.2[60%]
—B[40%]
上述的树形结构可以理解为A队列占用整个资源的60%,B队列占用整个资源的40%。A队列里面又分了两个子队列,A.1占据40%,A.2占据60%,也就是说此时A.1和A.2分别占用A队列的40%和60%的资源。虽然此时已经具体分配了集群的资源,但是并不是说A提交了任务之后只能使用它被分配到的60%的资源,而B队列的40%的资源就处于空闲。只要是其它队列中的资源处于空闲状态,那么有任务提交的队列可以使用空闲队列所分配到的资源,使用的多少是依据配来决定。参数的配置会在后文中提到。
Capacity调度器具有以下的几个特性:
1. 层次化的队列设计,这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
2.容量保证,队列上都会设置一个资源的占比,这样可以保证每个队列都不会占用整个集群的资源。
3. 安全,每个队列又严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。
4.弹性分配,空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
5.多租户租用,通过队列的容量限制,多个用户就可以共享同一个集群,同事保证每个队列分配到自己的容量,提高利用率。
6.操作性,Yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改。还提供给管理员界面,来显示当前的队列状况。管理员可以在运行时,添加一个队列;但是不能删除一个队列。管理员还可以在运行时暂停某个队列,这样可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了stopped,那么就不能向他或者子队列上提交任务了。
7.基于资源的调度,协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
相关参数的配置:
(1)capacity:队列的资源容量(百分比)。 当系统非常繁忙时,应保证每个队列的容量得到满足,而如果每个队列应用程序较少,可将剩余资源共享给其他队列。注意,所有队列的容量之和应小于100。
(2)maximum-capacity:队列的资源使用上限(百分比)。由于存在资源共享,因此一个队列使用的资源量可能超过其容量,而最多使用资源量可通过该参数限制。(这也是前文提到的关于有任务运行的队列可以占用的资源的最大百分比)
(3)user-limit-factor:每个用户最多可使用的资源量(百分比)。比如,假设该值为30,则任何时刻,每个用户使用的资源量不能超过该队列容量的30%。
(4)maximum-applications :集群或者队列中同时处于等待和运行状态的应用程序数目上限,这是一个强限制,一旦集群中应用程序数目超过该上限,后续提交的应用程序将被拒绝,默认值为 10000。所有队列的数目上限可通过参数yarn.scheduler.capacity.maximum-applications设置(可看做默认值),而单个队列可通过参数yarn.scheduler.capacity..maximum- applications设置适合自己的值。
(5)maximum-am-resource-percent:集群中用于运行应用程序 ApplicationMaster的资源比例上限,该参数通常用于限制处于活动状态的应用程序数目。该参数类型为浮点型,默认是0.1,表示10%。所有队列的ApplicationMaster资源比例上限可通过参数yarn.scheduler.capacity. maximum-am-resource-percent设置(可看做默认值),而单个队列可通过参数 yarn.scheduler.capacity.. maximum-am-resource-percent设置适合自己的值。
(6)state :队列状态可以为STOPPED或者 RUNNING,如果一个队列处于STOPPED状态,用户不可以将应用程序提交到该队列或者它的子队列中,类似的,如果ROOT队列处于STOPPED 状态,用户不可以向集群中提交应用程序,但正在运行的应用程序仍可以正常运行结束,以便队列可以优雅地退出。
(7)acl_submit_applications:限定哪些Linux用户/用户组可向给定队列中提交应用程序。需要注意的是,该属性具有继承性,即如果一个用户可以向某个队列中提交应用程序,则它可以向它的所有子队列中提交应用程序。配置该属性时,用户之间或用户组之间用“,”分割,用户和用户组之间用空格分割,比如“user1, user2 group1,group2”。
(8)acl_administer_queue:为队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等。同样,该属性具有继承性,如果一个用户可以向某个队列中提交应用程序,则它可以向它的所有子队列中提交应用程序。
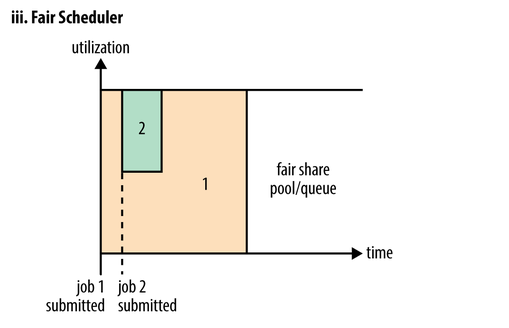
上图是Fair调度器在一个队列中的执行过程示意图。Fair调度器也就是日常说的公平调度器。Fair调度器是一个队列资源分配方式,在整个时间线上,所有的Job平均的获取资源。默认情况下,Fair调度器只是对内存资源做公平的调度和分配。当集群中只有一个任务在运行时,那么此任务会占用整个集群的资源。当其他的任务提交后,那些释放的资源将会被分配给新的Job,所以每个任务最终都能获取几乎一样多的资源。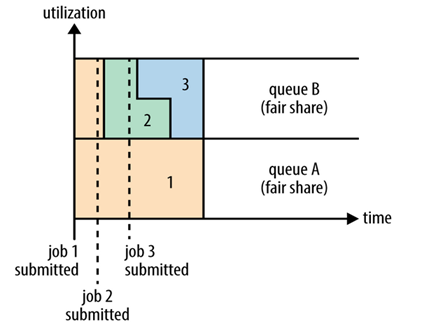
公平调度器也可以在多个队列间工作,如上图所示,例如有两个用户A和B,他们分别拥有一个队列。当A启动一个Job而B没有任务提交时,A会获得全部集群资源;当B启动一个Job后,A的任务会继续运行,不过队列A会慢慢释放它的一些资源,一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个Job并且其它任务也还在运行时,那么它将会和B队列中的的第一个Job共享队列B的资源,也就是队列B的两个Job会分别使用集群四分之一的资源,而队列A的Job仍然会使用集群一半的资源,结果就是集群的资源最终在两个用户之间平等的共享。
相关参数的配置:
(1)yarn.scheduler.fair.allocation.file: “allocation”文件的位置,“allocation”文件是一个用来描述queue以及它们的属性的配置文件。这个文件必须为格式严格的xml文件。如果为相对路径,那么将会在classpath下查找此文件(conf目录下)。默认值为“fair-scheduler.xml”。
(2)yarn.scheduler.fair.user-as-default-queue:是否将与allocation有关的username作为默认的queue name,当queue name没有指定的时候。如果设置成false(且没有指定queue name) 或者没有设定,所有的jobs将共享“default” queue。默认值为true。
(3)yarn.scheduler.fair.preemption:是否使用“preemption”(优先权,抢占),默认为fasle,在此版本中此功能为测试性的。
(4)yarn.scheduler.fair.assignmultiple:是在允许在一个心跳中,发送多个container分配信息。默认值为false。
(5)yarn.scheduler.fair.max.assign:如果assignmultuple为true,那么在一次心跳中,最多发送分配container的个数。默认为-1,无限制。
(6)yarn.scheduler.fair.locality.threshold.node:一个float值,在0~1之间,表示在等待获取满足node-local条件的containers时,最多放弃不满足node-local的container的机会次数,放弃的nodes个数为集群的大小的比例。默认值为-1.0表示不放弃任何调度的机会。
(7)yarn.scheduler.fair.locality.threashod.rack:同上,满足rack-local。
(8)yarn.scheduler.fair.sizebaseweight:是否根据application的大小(Job的个数)作为权重。默认为false,如果为true,那么复杂的application将获取更多的资源。
如果业务逻辑比较简单或者刚接触Hadoop的时候建议使用FIFO调度器;如果需要控制部分应用的优先级同时又想要充分利用集群资源的情况下,建议使用Capacity调度器;如果想要多用户或者多队列公平的共享集群资源,那么就选用Fair调度器。希望大家能够根据业务所需选择合适的调度器。
本文出自 “Cobub官方博客” 博客,请务必保留此出处http://cobub.blog.51cto.com/13036102/1951022
原文地址:http://cobub.blog.51cto.com/13036102/1951022