标签:www set 页面 查看 elf 格式 rac 手动 span
由于有相关需求,最近两天开始学了一下scrapy
这次我们就以爬取斗鱼直播间为例,我们准备爬取斗鱼所有的在线直播信息,
包括1.主播昵称 2.直播领域 3.所在页面数 4.直播观看人数 5.直播间url
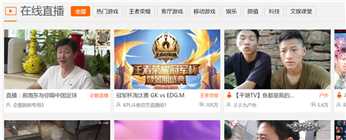
开始准备爬取的页面如图
url为:https://www.douyu.com/directory/all
但实际经过查看发现翻页是由ajax响应的,实际的ajax页面为:
https://www.douyu.com/directory/all?page=1&isAjax=1
其中page即为页面数
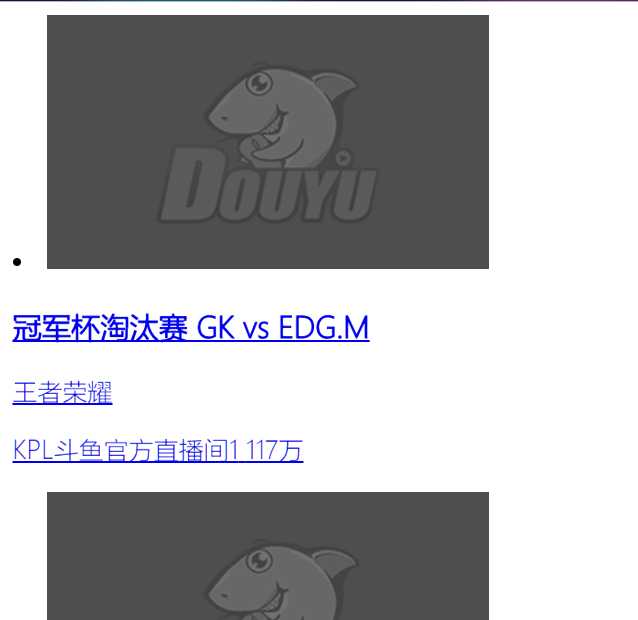
我们所需要的信息也在页面中,所以直接爬取该页面即可,但是由于没有想到什么特别好的方法判断是否是最后一页,这里我们手动输入
先编辑items.py
class ProjectItem(scrapy.Item): title=scrapy.Field() user=scrapy.Field() num=scrapy.Field() area=scrapy.Field() zhibojian=scrapy.Field() index=scrapy.Field()
接着编写spider.py,其中思路比较简单,回调函数即为parse本身
def handlenum(char): if u‘万‘ in char[0]: char[0] = str(float(char[0].replace(u‘万‘, ‘‘)) * 10000) return char class newspider(scrapy.Spider): name=‘ajax‘ allowed_domains = ["www.douyu.com", ‘douyucdn.cn‘] start_urls = ["https://www.douyu.com/directory/all?page=1&isAjax=1"] box=[] def parse(self, response): global index,box selector=Selector(response) for sel in selector.xpath(‘/html/body/li‘): item=ProjectItem() item[‘title‘]=sel.xpath(‘a/@title‘).extract() item[‘user‘]=sel.xpath(‘a/div/p/span[1]/text()‘).extract() num=sel.xpath(‘a/div/p/span[2]/text()‘).extract() item[‘num‘] =handlenum(num) item[‘area‘]=sel.xpath(‘a/div/div/span/text()‘).extract() item[‘zhibojian‘]=sel.xpath(‘a/@href‘).extract() item[‘index‘]=index yield item if index is 80: return else: index+=1 nexturl=‘https://www.douyu.com/directory/all?page=%s&isAjax=1‘%str(index) yield scrapy.Request(nexturl,callback=self.parse)
最后设置setting.py,这里我们使用csv格式来保存
FEED_URI=u‘file:///C:/Users/tLOMO/Desktop/one.csv‘ FEED_FORMAT=‘CSV‘
最后运行即可得到one.csv
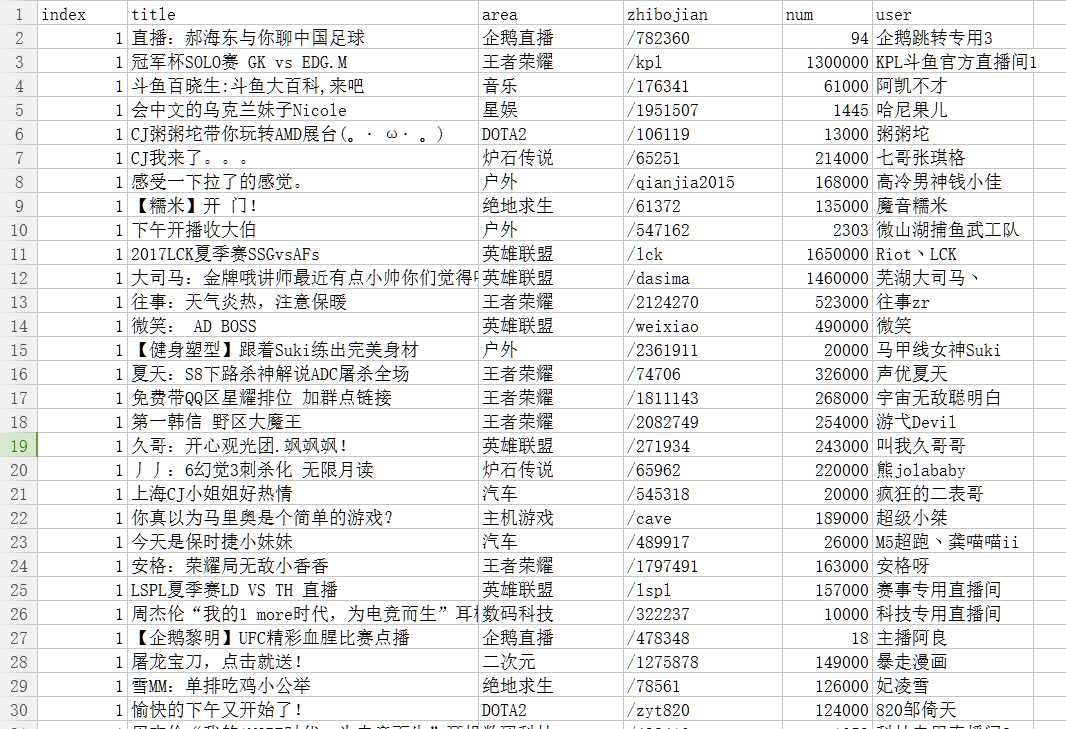
进过统计,我程序跑的时候,所有观看直播的人数为18290373,这个数字可信度我也搞不清啊,简单看了一下,所有的直播中直播王者荣耀和英雄联盟的是最多的
标签:www set 页面 查看 elf 格式 rac 手动 span
原文地址:http://www.cnblogs.com/lomooo/p/7246041.html