标签:package ica 提升 组织 http 业界 所有应用 版本 mapred
原理
架构图如下:

原 MapReduce 程序的流程:
首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job
Tracker 中,Job Tracker需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有
job 失败、重启等操作。
TaskTracker 是 Map-reduce
集群中每台机器都有的一个部分,它的职责有两个:一是监视自己所在机器的资源情况,二是监视当前机器的 tasks 运行状况。TaskTracker
需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job
分配运行在哪些机器上。上图虚线箭头就是表示消息的发送 - 接收的过程。
存在的问题
其他问题摘抄如下:
在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
从 操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 ) 时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应 用程序是不是适用新的 Hadoop 版本而浪费大量时间。
一句话总结:JobTracker干的事儿太多了。
架构图如下:

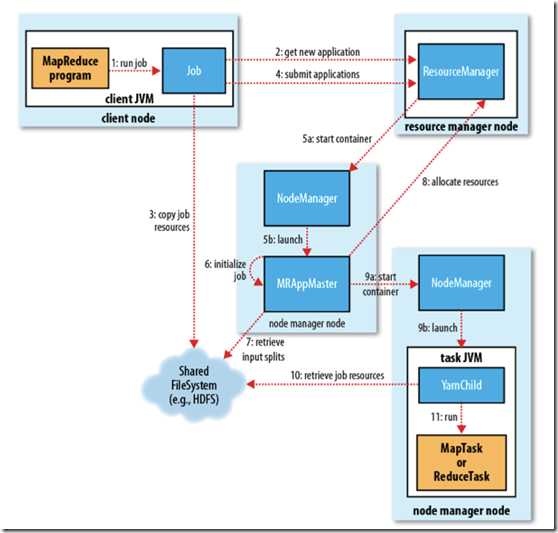
基本思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控。
ResourceManager
管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的
MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager
和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。NodeManager
是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
架构变化的总结
原来的JobTracker和TaskTracker是从物理节点的角度来设置,但每个
节点内部还包括资源监控、任务调度的功能。改版之后,从逻辑上进行功能模块设计,ResourceManager专门负责管理和分配资
源,NodeManager是RM在各节点上的代理,每个应用有一个ApplicationMaster,但不放在RM节点上,而是分布式存放,用来管理
应用在各节点上的运行、向RM申请资源。这样,原来JobTracker被分解为两个功能模块,并且不在同一个节点上运行,自然降低了RM节点(原
JobTracker节点)的管理负荷。
摘自:http://www.jianshu.com/p/3b9179534127
yarn架构——本质上是在做解耦 将资源分配和应用程序状态监控两个功能职责分离为RM和AM
标签:package ica 提升 组织 http 业界 所有应用 版本 mapred
原文地址:http://www.cnblogs.com/bonelee/p/7246964.html